数据库访问性能优化(四)
2016-07-01 11:02
253 查看
4.2、合理使用排序
Oracle的排序算法一直在优化,但是总体时间复杂度约等于nLog(n)。普通OLTP系统排序操作一般都是在内存里进行的,对于数据库来说是一种CPU的消耗,曾在PC机做过测试,单核普通CPU在1秒钟可以完成100万条记录的全内存排序操作,所以说由于现在CPU的性能增强,对于普通的几十条或上百条记录排序对系统的影响也不会很大。但是当你的记录集增加到上万条以上时,你需要注意是否一定要这么做了,大记录集排序不仅增加了CPU开销,而且可能会由于内存不足发生硬盘排序的现象,当发生硬盘排序时性能会急剧下降,这种需求需要与DBA沟通再决定,取决于你的需求和数据,所以只有你自己最清楚,而不要被别人说排序很慢就吓倒。以下列出了可能会发生排序操作的SQL语法:Order byGroup byDistinctExists子查询Not Exists子查询In子查询Not In子查询Union(并集),UnionAll也是一种并集操作,但是不会发生排序,如果你确认两个数据集不需要执行去除重复数据操作,那请使用Union
All 代替Union。Minus(差集)Intersect(交集)Create IndexMerge Join,这是一种两个表连接的内部算法,执行时会把两个表先排序好再连接,应用于两个大表连接的操作。如果你的两个表连接的条件都是等值运算,那可以采用Hash
Join来提高性能,因为Hash
Join使用Hash 运算来代替排序的操作。具体原理及设置参考SQL执行计划优化专题。
4.3、减少比较操作
我们SQL的业务逻辑经常会包含一些比较操作,如a=b,a之类的操作,对于这些比较操作数据库都体现得很好,但是如果有以下操作,我们需要保持警惕:Like模糊查询,如下所示:a like ‘c%’ Like模糊查询对于数据库来说不是很擅长,特别是你需要模糊检查的记录有上万条以上时,性能比较糟糕,这种情况一般可以采用专用Search或者采用全文索引方案来提高性能。不能使用索引定位的大量InList,如下所示:a in (:1,:2,:3,…,:n) ----n>20如果这里的a字段不能通过索引比较,那数据库会将字段与in里面的每个值都进行比较运算,如果记录数有上万以上,会明显感觉到SQL的CPU开销加大,这个情况有两种解决方式:a、 将in列表里面的数据放入一张中间小表,采用两个表Hash
Join关联的方式处理;b、 采用str2varList方法将字段串列表转换一个临时表处理,关于str2varList方法可以在网上直接查询,这里不详细介绍。 以上两种解决方案都需要与中间表Hash
Join的方式才能提高性能,如果采用了Nested
Loop的连接方式性能会更差。如果发现我们的系统IO没问题但是CPU负载很高,就有可能是上面的原因,这种情况不太常见,如果遇到了最好能和DBA沟通并确认准确的原因。
4.4、大量复杂运算在客户端处理
什么是复杂运算,一般我认为是一秒钟CPU只能做10万次以内的运算。如含小数的对数及指数运算、三角函数、3DES及BASE64数据加密算法等等。如果有大量这类函数运算,尽量放在客户端处理,一般CPU每秒中也只能处理1万-10万次这样的函数运算,放在数据库内不利于高并发处理。5、利用更多的资源
5.1、客户端多进程并行访问
多进程并行访问是指在客户端创建多个进程(线程),每个进程建立一个与数据库的连接,然后同时向数据库提交访问请求。当数据库主机资源有空闲时,我们可以采用客户端多进程并行访问的方法来提高性能。如果数据库主机已经很忙时,采用多进程并行访问性能不会提高,反而可能会更慢。所以使用这种方式最好与DBA或系统管理员进行沟通后再决定是否采用。 例如:我们有10000个产品ID,现在需要根据ID取出产品的详细信息,如果单线程访问,按每个IO要5ms计算,忽略主机CPU运算及网络传输时间,我们需要50s才能完成任务。如果采用5个并行访问,每个进程访问2000个ID,那么10s就有可能完成任务。那是不是并行数越多越好呢,开1000个并行是否只要50ms就搞定,答案肯定是否定的,当并行数超过服务器主机资源的上限时性能就不会再提高,如果再增加反而会增加主机的进程间调度成本和进程冲突机率。 以下是一些如何设置并行数的基本建议:如果瓶颈在服务器主机,但是主机还有空闲资源,那么最大并行数取主机CPU核数和主机提供数据服务的磁盘数两个参数中的最小值,同时要保证主机有资源做其它任务。如果瓶颈在客户端处理,但是客户端还有空闲资源,那建议不要增加SQL的并行,而是用一个进程取回数据后在客户端起多个进程处理即可,进程数根据客户端CPU核数计算。如果瓶颈在客户端网络,那建议做数据压缩或者增加多个客户端,采用mapreduce的架构处理。如果瓶颈在服务器网络,那需要增加服务器的网络带宽或者在服务端将数据压缩后再处理了。
5.2、数据库并行处理
数据库并行处理是指客户端一条SQL的请求,数据库内部自动分解成多个进程并行处理,如下图所示: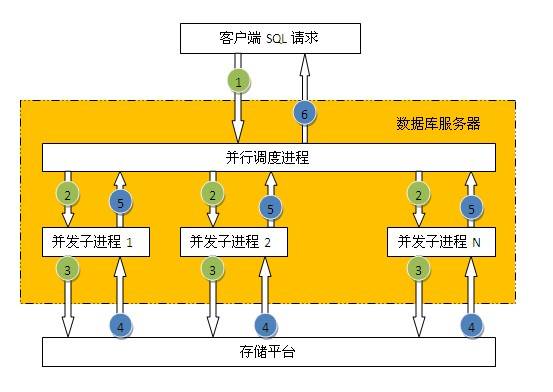
并不是所有的SQL都可以使用并行处理,一般只有对表或索引进行全部访问时才可以使用并行。数据库表默认是不打开并行访问,所以需要指定SQL并行的提示,如下所示:select * from
employee; 并行的优点:使用多进程处理,充分利用数据库主机资源(CPU,IO),提高性能。并行的缺点:1、单个会话占用大量资源,影响其它会话,所以只适合在主机负载低时期使用;2、只能采用直接IO访问,不能利用缓存数据,所以执行前会触发将脏缓存数据写入磁盘操作。 注:1、并行处理在OLTP类系统中慎用,使用不当会导致一个会话把主机资源全部占用,而正常事务得不到及时响应,所以一般只是用于数据仓库平台。2、一般对于百万级记录以下的小表采用并行访问性能并不能提高,反而可能会让性能更差。

相关文章推荐
- 基于 Red Hat 的发行版 Oracle Linux 正式发布Oracle Linux 7.1
- Oracle Containers for J2EE远程安全漏洞(CVE-2014-0413)
- Oracle 10g R2不能使用EM的问题
- 表空间操作
- PreparedStatement中in子句的处理
- VMware下RedHat4.8_64位安装Oracle 10g RAC--简略脚本
- oracle sql日期比较
- 基于 Red Hat 的发行版 Oracle Linux 正式发布Oracle Linux 7.1
- OS block size和Oracle block size,查找OS Blocksize的方法
- oracle中创建数据库和表空间的几点总结
- 数据库自动备份脚本
- SQL Server 2005中更改sa的用户名的方法
- oracle的nvl函数的使用介绍
- 解决oracle用户连接失败的解决方法
- oracle的一些tips技巧
- Oracle 下的开发日积月累
- Oracle存储过程之数据库中获取数据实例
- Windows下ORACLE 10g完全卸载的方法分析
- Oracle 函数大全[字符串函数,数学函数,日期函数]第1/4页