让Scrapy的Spider更通用
2016-07-01 00:00
302 查看
摘要: 《Scrapy的架构初探》一文所讲的Spider是整个架构中最定制化的一个部件,Spider负责把网页内容提取出来,而不同数据采集目标的内容结构不一样,几乎需要为每一类网页都做定制。我们有个设想:是否能做一个比较通用的Spider,把定制部分再进一步隔离出去?

####1,引言
《Scrapy的架构初探》一文所讲的Spider是整个架构中最定制化的一个部件,Spider负责把网页内容提取出来,而不同数据采集目标的内容结构不一样,几乎需要为每一类网页都做定制。我们有个设想:是否能做一个比较通用的Spider,把定制部分再进一步隔离出去?
GooSeeker有一个爬虫群模式,从技术实现层面来考察的话,其实就是把爬虫软件做成一个被动接受任务的执行单元,给他什么任务他就做什么任务,也就是说同一个执行单元可以爬多种不同的网站。而分配任务的是GooSeeker会员中心的爬虫罗盘,实现集中管理分布执行。
开源Python即时网络爬虫项目同样也要尽量实现通用化。主要抓取以下2个重点:
网页内容提取器从外部注入到Spider中,让Spider变通用:参看《Python即时网络爬虫:API说明》,通过API从GooSeeker会员中心获得网页内容提取器,可以充分利用MS谋数台的直观标注快速生成提取器的能力。
抓取目标网址不再存于Spider,而是从外部获得:GooSeeker有个基于大数据平台的网址库系统,还有爬虫罗盘可观察网址的抓取状态,也有用户界面添加删除网址,把Spider进一步做成一个执行机构。
下面我们将进一步讲解实现原理,以助于读者阅读源码。
####2,爬虫群模式示意图
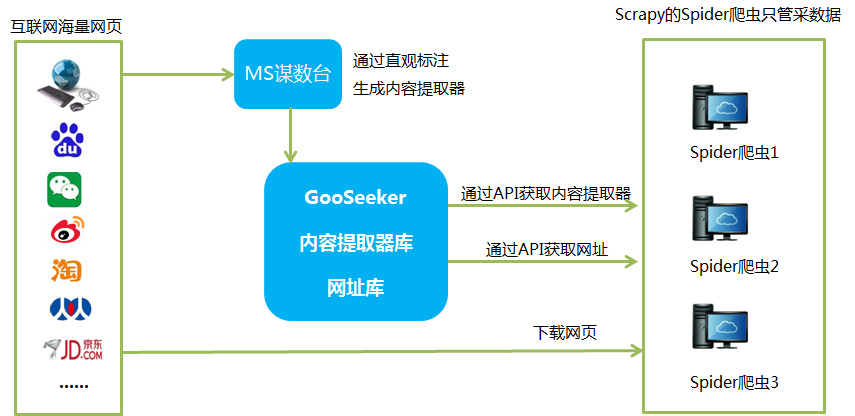
中间蓝色部分就是GooSeeker会员中心的地址库和爬虫罗盘。网址和提取规则本来应该硬编码到Spider中的,现在隔离出来,由会员中心进行管理,那么Spider就很容易做通用了。
####3,通用Spider的主要功能
地址库和提取规则隔离出来以后,Scrapy的Spider可以专注于以下流程:
通过API从GooSeeker会员中心获取内容提取器:这个API的url可以硬编码到Spider中,放在start_urls列表的位置, 这里本来是放目标网页地址的,现在换成一个固定的API地址,在这一点上,Spider变通用了
在第一个parse()过程,不是解析目标网页内容,而是把API中获得内容提取器注入到gsExtractor中。
在第一个parse()过程,为第二个API构造一个Request,目的是从GooSeeker会员中心获取要爬取的网址
在第二个parse()过程,用目标网址构造一个Request,这才是真正的交给Loader去下载目标网页
在第三个parse()过程,利用gsExtractor提取网页内容
在第三个parse()过程,再次为第二个API构造一个Request,获得下一个目标网址
跳到4,一直循环,直到GooSeeker会员中心的地址库都用完了。
####4,接下来的工作
按照上述设想编写和调测Scrapy的通用Spider
研究是否可以更加通用,把GooSeeker的爬虫群调度都引入到Spider中,也就是在通过第一个API获得提取器之前再增加一个获得爬虫群调度任务的过程,这样,把所有Spider都变成被动接受任务的工作模式,每个Spider是不固定抓取规则的。
####5,相关文档
Python即时网络爬虫项目: 内容提取器的定义
Scrapy:python3下的第一次运行测试
####6,集搜客GooSeeker开源代码下载源
开源Python即时网络爬虫GitHub源
####7,文档修改历史
2016-07-01:V1.0,首次发布
2016-07-01:V1.1,编辑修改,补充过程描述文字
####1,引言
《Scrapy的架构初探》一文所讲的Spider是整个架构中最定制化的一个部件,Spider负责把网页内容提取出来,而不同数据采集目标的内容结构不一样,几乎需要为每一类网页都做定制。我们有个设想:是否能做一个比较通用的Spider,把定制部分再进一步隔离出去?
GooSeeker有一个爬虫群模式,从技术实现层面来考察的话,其实就是把爬虫软件做成一个被动接受任务的执行单元,给他什么任务他就做什么任务,也就是说同一个执行单元可以爬多种不同的网站。而分配任务的是GooSeeker会员中心的爬虫罗盘,实现集中管理分布执行。
开源Python即时网络爬虫项目同样也要尽量实现通用化。主要抓取以下2个重点:
网页内容提取器从外部注入到Spider中,让Spider变通用:参看《Python即时网络爬虫:API说明》,通过API从GooSeeker会员中心获得网页内容提取器,可以充分利用MS谋数台的直观标注快速生成提取器的能力。
抓取目标网址不再存于Spider,而是从外部获得:GooSeeker有个基于大数据平台的网址库系统,还有爬虫罗盘可观察网址的抓取状态,也有用户界面添加删除网址,把Spider进一步做成一个执行机构。
下面我们将进一步讲解实现原理,以助于读者阅读源码。
####2,爬虫群模式示意图
中间蓝色部分就是GooSeeker会员中心的地址库和爬虫罗盘。网址和提取规则本来应该硬编码到Spider中的,现在隔离出来,由会员中心进行管理,那么Spider就很容易做通用了。
####3,通用Spider的主要功能
地址库和提取规则隔离出来以后,Scrapy的Spider可以专注于以下流程:
通过API从GooSeeker会员中心获取内容提取器:这个API的url可以硬编码到Spider中,放在start_urls列表的位置, 这里本来是放目标网页地址的,现在换成一个固定的API地址,在这一点上,Spider变通用了
在第一个parse()过程,不是解析目标网页内容,而是把API中获得内容提取器注入到gsExtractor中。
在第一个parse()过程,为第二个API构造一个Request,目的是从GooSeeker会员中心获取要爬取的网址
在第二个parse()过程,用目标网址构造一个Request,这才是真正的交给Loader去下载目标网页
在第三个parse()过程,利用gsExtractor提取网页内容
在第三个parse()过程,再次为第二个API构造一个Request,获得下一个目标网址
跳到4,一直循环,直到GooSeeker会员中心的地址库都用完了。
####4,接下来的工作
按照上述设想编写和调测Scrapy的通用Spider
研究是否可以更加通用,把GooSeeker的爬虫群调度都引入到Spider中,也就是在通过第一个API获得提取器之前再增加一个获得爬虫群调度任务的过程,这样,把所有Spider都变成被动接受任务的工作模式,每个Spider是不固定抓取规则的。
####5,相关文档
Python即时网络爬虫项目: 内容提取器的定义
Scrapy:python3下的第一次运行测试
####6,集搜客GooSeeker开源代码下载源
开源Python即时网络爬虫GitHub源
####7,文档修改历史
2016-07-01:V1.0,首次发布
2016-07-01:V1.1,编辑修改,补充过程描述文字

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- install scrapy with pip and easy_install
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定