Nodejs监控文件内容变化并获取最新添加的内容
2016-06-29 07:46
579 查看
最新的代码我已经放在了github上
现在有个需求是这样:
“某个应用会产生日志文件,使用nodejs开发程序完成对日志的操作:当程序启动的时候首先获取日志所有内容并作相关处理,然后对日志监控,如果有新的内容添加进来,立即获取到最新内容继续做处理”。当然,这里我把需求简化了,主要就是下面酱紫:
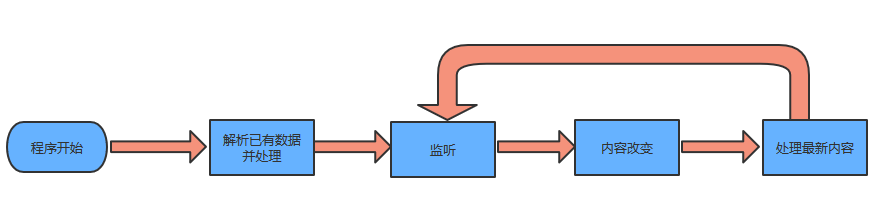
接触nodejs不到8小时,只有从nodejs的中文api找切入点,分别找到了两个模块
fs、ReadLine
watch和watchFile实现文件的监听,代码如下(watch):
效果图如下:
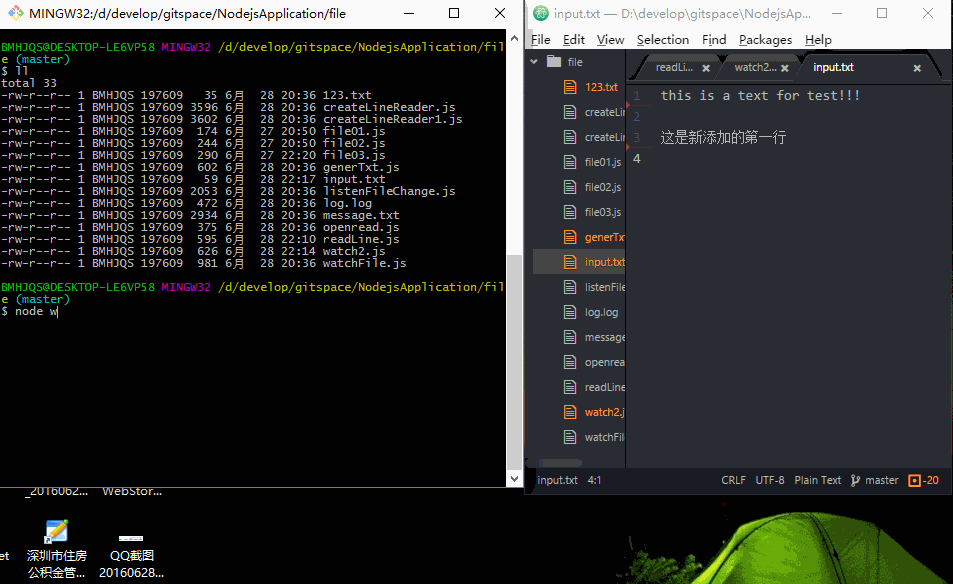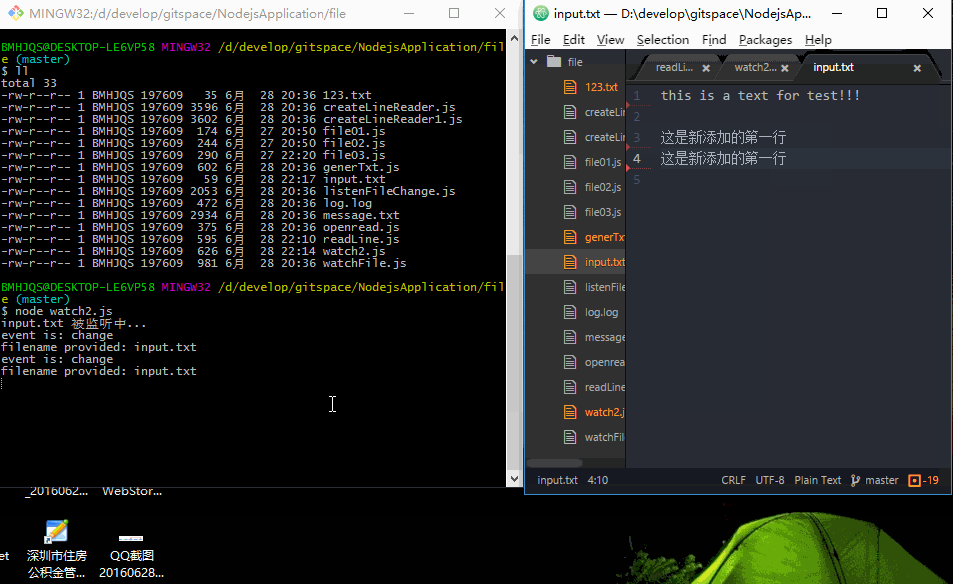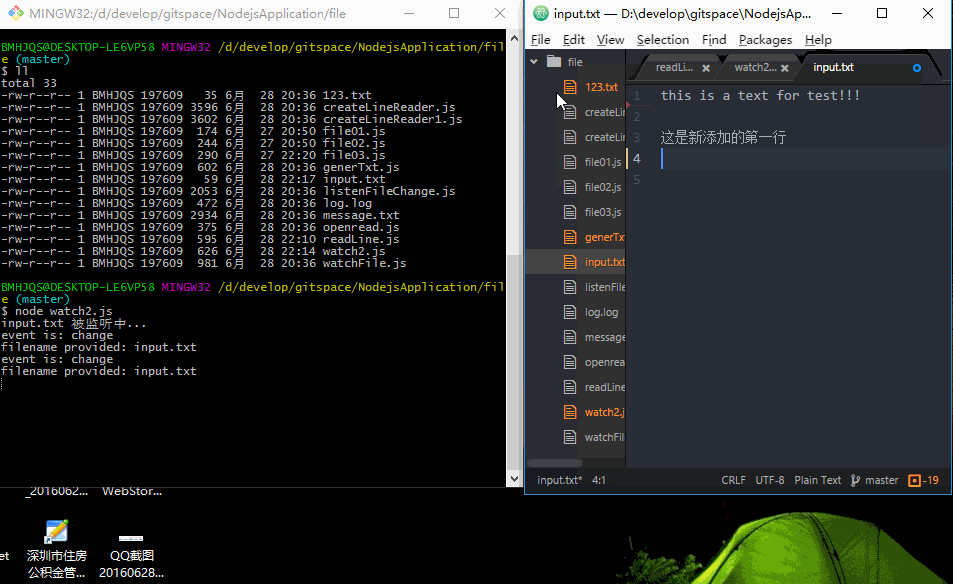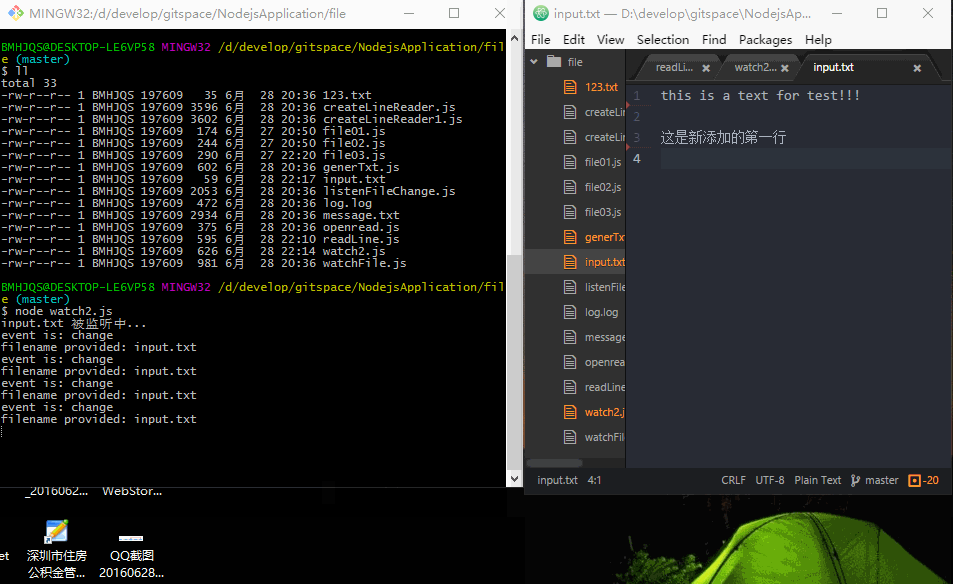
只要是文件被修改后保存,程序会立即检测到(这里我有个疑问,我修改文件保存后,为什么会打印两遍?)
ReadLine的功能就是按行读取文件,相关代码如下:
对于没有用过nodejs但想学nodejs的人来说,我建议先把菜鸟学校里的教程看一遍,我接触nodejs的当天晚上就把上面的教程过了一遍。这样再深入的话会很快。跑题了。。。
上面代码的结果如图:

有了这两段代码,我很快有了方案
程序开始使用readline将原有内容逐行读取并处理;
处理完后使用watch监听文件;
文件变动再次使用readline读文件内容,依次放在一个数组里,然后获取最后一个;
然而并非我想象的那样,如果一次插入多条内容,那我这个方案就不行了。
我想找有关file的第三方库,然而并没有我想要的,还是要自己写!
最后发现了watch里有个回调函数
请注意这两个参数curr,prev,我试着把curr的内容打印出来,如下:
我注意到里面有个size,这难道是文件的字节数?答案是的,那这样问题就解决了,新的方案出来了:
使用readline先逐行获取内容并解析
使用watchfile监控文件,当文件有内容添加使用curr和prev里的size来读取添加的内容
得到新的内容,通过’\n\r’或’\n’将其截取成数组,这样就得到了一行一行的内容
这里需要用到fs的open和read
两个方法真的是绝配啊~~~看看中文api,很详细,配合的代码如下:
每次文件改动(这里主要指文件有新的内容追加上,没有考虑删除修改等情况),就将上一状态的大小作为本次读文件的起始位置
position—>prev.size
offset—>0 //在新建buffer的其实位置开始写入
length—>(curr.size - prev.size)
完整的代码如下:
运行结果如下:

代码我先上传到这里
我这样写只是完成了我当前的需求,在接下来学习nodejs的过程中,我会对其进行优化,最后能将其打包上传到npm上!
nodejs有点让我抓狂了,我开始喜欢上它了~~~
现在有个需求是这样:
“某个应用会产生日志文件,使用nodejs开发程序完成对日志的操作:当程序启动的时候首先获取日志所有内容并作相关处理,然后对日志监控,如果有新的内容添加进来,立即获取到最新内容继续做处理”。当然,这里我把需求简化了,主要就是下面酱紫:
接触nodejs不到8小时,只有从nodejs的中文api找切入点,分别找到了两个模块
fs、ReadLine
watch和watchFile实现文件的监听,代码如下(watch):
var fs = require('fs');// 引入fs 模块
var filePath = 'input.txt';
fs.watch(filePath, function (event, filename) {
console.log('event is: ' + event);
if (filename) {
console.log('filename provided: ' + filename);
//readTxt();
} else {
console.log('filename not provided');
}
}
});
console.log(filePath + ' 被监听中...');效果图如下:
只要是文件被修改后保存,程序会立即检测到(这里我有个疑问,我修改文件保存后,为什么会打印两遍?)
ReadLine的功能就是按行读取文件,相关代码如下:
var fs = require('fs');
var readline = require('readline');// 引入readline模块
var filename = 'input.txt';
var rl = readline.createInterface({
input: fs.createReadStream(filename,{
enconding:'utf8'
}),
output: null
});
rl.on('line', function(line) {
if (line) {
console.log(line.toString());
}
}).on('close', function() {
console.log('读文件结束!');
});对于没有用过nodejs但想学nodejs的人来说,我建议先把菜鸟学校里的教程看一遍,我接触nodejs的当天晚上就把上面的教程过了一遍。这样再深入的话会很快。跑题了。。。
上面代码的结果如图:
有了这两段代码,我很快有了方案
程序开始使用readline将原有内容逐行读取并处理;
处理完后使用watch监听文件;
文件变动再次使用readline读文件内容,依次放在一个数组里,然后获取最后一个;
然而并非我想象的那样,如果一次插入多条内容,那我这个方案就不行了。
我想找有关file的第三方库,然而并没有我想要的,还是要自己写!
最后发现了watch里有个回调函数
fs.watchFile('input.text', function (curr, prev) {
console.log('the current mtime is: ' + curr.mtime);
console.log('the previous mtime was: ' + prev.mtime);
});请注意这两个参数curr,prev,我试着把curr的内容打印出来,如下:
{ dev: 997878,
mode: 33206,
nlink: 1,
uid: 0,
gid: 0,
rdev: 0,
blksize: undefined,
ino: 844424930190818,
size: 175,
blocks: undefined,
atime: Tue Jun 28 2016 20:36:43 GMT+0800 (中国标准时间),
mtime: Tue Jun 28 2016 22:53:46 GMT+0800 (中国标准时间),
ctime: Tue Jun 28 2016 22:53:46 GMT+0800 (中国标准时间),
birthtime: Mon Jun 27 2016 20:36:56 GMT+0800 (中国标准时间) }我注意到里面有个size,这难道是文件的字节数?答案是的,那这样问题就解决了,新的方案出来了:
使用readline先逐行获取内容并解析
使用watchfile监控文件,当文件有内容添加使用curr和prev里的size来读取添加的内容
得到新的内容,通过’\n\r’或’\n’将其截取成数组,这样就得到了一行一行的内容
这里需要用到fs的open和read
fs.open(path, flags, [mode], callback) fs.read(fd, buffer, offset, length, position, callback)
两个方法真的是绝配啊~~~看看中文api,很详细,配合的代码如下:
fs.open(filePath,'a+',function(error,fd){
var buffer;
var remainder = null;
fs.watchFile(filePath,{
persistent: true,
interval: 1000
},function(curr, prev){
//console.log(curr);
if(curr.mtime>prev.mtime){
//文件内容有变化,那么通知相应的进程可以执行相关操作。例如读物文件写入数据库等
buffer = new Buffer(curr.size - prev.size);// 创建一个缓冲,长度为(当前文件大小-文件上一个状态的大小)
fs.read(fd,buffer,0,(curr.size - prev.size),prev.size,function(err, bytesRead, buffer){
console.log(buffer.toString());//新增加的内容
});
}else{
console.log('文件读取错误');
}
});
});每次文件改动(这里主要指文件有新的内容追加上,没有考虑删除修改等情况),就将上一状态的大小作为本次读文件的起始位置
position—>prev.size
offset—>0 //在新建buffer的其实位置开始写入
length—>(curr.size - prev.size)
完整的代码如下:
var fs = require('fs');
var readline = require('readline');
var filename = 'input.txt';
var logsArr = new Array();
var listenArr = new Array();
function init(){
sendHisLogs(filename, listenLogs);
}
function sendHisLogs(filename,listenLogs){
var rl = readline.createInterface({
input: fs.createReadStream(filename,{
enconding:'utf8'
}),
output: null,
terminal: false //这个参数很重要
});
rl.on('line', function(line) {
if (line) {
logsArr.push(line.toString());
}
}).on('close', function() {
for(var i = 0 ;i<logsArr.length;i++){
console.log('发送历史信号: ' + logsArr[i]);
//generateLog(logsArr[i])
}
listenLogs(filename);
});
}
function generateLog(str){
var regExp = /(\[.+?\])/g;//(\\[.+?\\])
var res = str.match(regExp);
console.log(res);
for(i=0;i<res.length;i++){
res[i] = res[i].replace('[','').replace(']',''); //发送历史日志
}
}
var listenLogs = function(filePath){
console.log('日志监听中...');
var fileOPFlag="a+";
fs.open(filePath,fileOPFlag,function(error,fd){
var buffer;
var remainder = null;
fs.watchFile(filePath,{
persistent: true,
interval: 1000
},function(curr, prev){
console.log(curr);
if(curr.mtime>prev.mtime){
//文件内容有变化,那么通知相应的进程可以执行相关操作。例如读物文件写入数据库等
buffer = new Buffer(curr.size - prev.size);
fs.read(fd,buffer,0,(curr.size - prev.size),prev.size,function(err, bytesRead, buffer){
generateTxt(buffer.toString())
});
}else{
console.log('文件读取错误');
}
});
function generateTxt(str){ // 处理新增内容的地方
var temp = str.split('\r\n');
for(var s in temp){
console.log(temp[s]);
}
}
});
}
function getNewLog(path){
console.log('做一些解析操作');
}
init();运行结果如下:
代码我先上传到这里
我这样写只是完成了我当前的需求,在接下来学习nodejs的过程中,我会对其进行优化,最后能将其打包上传到npm上!
nodejs有点让我抓狂了,我开始喜欢上它了~~~

相关文章推荐
- CVP认证学习笔记--李天宇018spriteBatchNode使用
- CVP认证学习笔记--李天宇013在Node的生命周期和图层种处理触摸
- CVP认证学习笔记--李天宇013在Node的生命周期和图层种处理触摸
- Nodejs基础中间件Connect
- 如何在Ubuntu14.04服务器上安装NodeJS
- Node线上部署管理器PM2
- 237. Delete Node in a Linked List
- 【node.js】本地模式安装express:'express' 不是内部或外部命令,也不是可运行的程序或批处理文件。
- node 安装 卸载 版本控制
- Leetcode 117. Populating Next Right Pointers in Each Node II
- 237. Delete Node in a Linked List
- Leetcode 116. Populating Next Right Pointers in Each Node
- nodejs 使用npm install express报错解决方案
- Node.js~sails.js~package.json的作用
- nodejs require本地模块的一些细节笔记
- NodeJS UDP 客户端
- NodeJS UPD服务器
- node.js request and response related
- Node.js express不是内部或外部命令,也不是可运行的程序或批处理文件
- 在node.js下浅谈文件上传的方法