读《数据结构》1-4章[线性结构]
2016-06-12 10:14
459 查看
2016.06.07 – 06.30
读《数据结构》(严蔚敏 吴伟明)“1-4章”的个人笔记。
06.07
例 – 线性链表。
用LinkList定义一个数据对象(变量)就得到一个数据元素,用LinkList定义多个数据对象就得到数据元素的集合;组织各个数据元素在内存中的存储关系(在内存中连续或者不连续存储)及各个数据元素间(被操作)的联系(如pn指向另外一个数据元素)就得到了各个数据元素之间的关系。
算法。算法是对特定问题求解步骤的一种描述。算法效率的度量需通过依据该算法编制的程序在计算机上运行(时)所消耗的时间来度量[代码的时间复杂度可作为算法执行效率的一种参考]。
时间复杂度。一般情况下,算法中基本操作重复执行的次数是问题规模n的一个函数f(n),算法的复杂度记作T(n) = O(f(n)),表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率是相同。
06.08
f(n)的计算。对于不同的输入该算法有不同的执行次数时,可用平均值作为f(n)的值;有时各种输入数据输入的概率难以确定,所以更可行的方法是使用该算法最坏执行次数的值作为f(n)的值。
算法的存储空间 复杂度。空间复杂度S(n) = O(f(n)),其中n为问题规模。一个上机执行程序除了需要存储空间来寄存本身所用指令、常数、变量和输入数据外,也需要一些对数据进行操作的工作单元和存储一些为实现计算所需信息的存储空间。若输入数据所占空间只取决于问题本身,和算法无关,则只需要分析除输入和程序之外的额外空间。
例 - 用C语言来实现一个简单的顺序表。先为顺序表动态分配以元素大小为单位的n个空间单元;若往顺序表中插入一个元素时若超过了当前所分配的空间则往当前空间中追加m个空间单元。
06.14
[1] 代码简单实现
sequence_list.c
06.15
-man realloc-
原型。void *realloc(void *ptr, size_t size);
功能。realloc函数将ptr所指向的内存块的大小改为size字节大小(原内容不会被改变)。如果新的大小大于原来的大小,新增的内存块不会被初始化。如果ptr为NULL,那么realloc相当于malloc(size);如果size等于0并且ptr不为NULL,则该调用相当于free(ptr)。除非ptr为NULL,否则ptr必须是之前malloc(),calloc()或realloc()的返回值。如果指向的区域被移动,则原来的内存区域会被自动的free(ptr)。
返回值。realloc()函数返回一个指向新内存区域的指针,若请求失败则返回NULL。如果size等于0,NULL或者传递给free()函数过后的指针将被返回。如果realloc()失败,则原来的内存块将不变;它不会被释放或移除。
[2] 算法复杂度分析
insert_elem2sq_list具有重复(循环)的是元素的移动操作,最坏的情况是将元素插入到表中的第一个元素之前(需要移动n个元素 – 假设表具有n个元素)。insert_elem2sq_list的复杂度可用O(n)来表示。同理,合并俩链表的操作的时间复杂度也为O(n)。[《CSAPP》中有更细致的分析]
线性表的特点是逻辑关系相邻的两个数据元素在内存中存储位置也是相邻关系,因此可以用一个简单的、直观的公式来表示(在C语言中也能够用简单的方式访问,如下标、偏移)。然而这种存储结构也有一个弱点:在作插入或删除操作时,需要移动大量元素。
链表的结点。为了表示线性链表中ai与ai+1元素之间的逻辑关系(ai+1为ai的后继元素),ai除了要存储本身的信息外,还要存储ai+1的地址信息(指针域),ai中的这两部分信息被称为结点。
例 – 用C语言实现一个简单的单链表。
06.17
[1] 代码简单实现
single_link_list.c
在shell下编译并运行single_link_list.c得以下结果:

[2] 复杂度分析
同顺序表,单链表的插入操作的时间复杂度为O(n)。合并单链表的时间复杂度也为O(n)。
例 — 用C语言实现一个简单的双向链表。
06.22
double_link_list.c
运行double_link_list.c得以下结果:


06.23
一般来说,在初始化设空栈时不应限定栈的最大容量。一个较合理的做法是:先为栈分配一个基本容量,然后在应用过程中,当栈的空间不够使用时在逐段扩大。
[1] 描述栈的结构体类型
其中,stacksize指示栈的当前可使用的最大容量。栈的初始化操作为:按设定的初始分配量进行第一次分配,base为栈底指针,在顺序栈中,它始终指向栈底的位置,若base的值为NULL,则表明栈结构不存在。称top为栈顶指针,其初值指向栈底,即top=base可作为栈空的标记,每当插入新的栈顶元素时,指针top增1;删除栈顶元素时,指针top减1,因此,非空栈中的栈顶指针始终在栈顶元素的下一个位置上。
[2] 跟栈相关的基本操作
06.26
stack_basic.c
在shell中运行该程序,得到以下测试结果:

[还相差甚远]
[1] 数制转换

[2] 括号匹配的检验

[3] 行编辑程序

[4] 迷宫求解

[5] 表达式求值

[…如汉诺塔、八皇后问题…]
…
06.09
串定长顺序存储表示。用一组地址连续的内存单元存储串值的字符序列。
堆分配存储表示。仍以一组地址连续的内存单元存储串值的字符序列,但它们的存储空间是在程序执行过程中动态分配的。
串的块链存储表示。以结点方式存储各个串。
06.30
例 – 用C语言编写一个简单的关于串(顺序存储方式)的程序。(串比较、串连接、求串长度、串模式匹配等)[串相关的操作无须涉及任何与内核交互,《TCPL》等书涉及关于串函数的一些编写内容,本书中的模式匹配算法可以值得(因为没怎么看过)一看]。。


[2016.06.12 - 10:15]
读《数据结构》(严蔚敏 吴伟明)“1-4章”的个人笔记。
06.07
1 与数据结构相关的理解
对数据结构的理解(编程语言层面)。数据结构是相互之间存在一种或多种特定关系的数据元素的集合。例 – 线性链表。
/* 描述数据元素的类型 */
typedef struct _link_list {
char ch;
int i;
struct _link_list *pn;
}LinkList;
/* 描述数据元素之间关系的代码 */
...用LinkList定义一个数据对象(变量)就得到一个数据元素,用LinkList定义多个数据对象就得到数据元素的集合;组织各个数据元素在内存中的存储关系(在内存中连续或者不连续存储)及各个数据元素间(被操作)的联系(如pn指向另外一个数据元素)就得到了各个数据元素之间的关系。
算法。算法是对特定问题求解步骤的一种描述。算法效率的度量需通过依据该算法编制的程序在计算机上运行(时)所消耗的时间来度量[代码的时间复杂度可作为算法执行效率的一种参考]。
时间复杂度。一般情况下,算法中基本操作重复执行的次数是问题规模n的一个函数f(n),算法的复杂度记作T(n) = O(f(n)),表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率是相同。
06.08
f(n)的计算。对于不同的输入该算法有不同的执行次数时,可用平均值作为f(n)的值;有时各种输入数据输入的概率难以确定,所以更可行的方法是使用该算法最坏执行次数的值作为f(n)的值。
算法的存储空间 复杂度。空间复杂度S(n) = O(f(n)),其中n为问题规模。一个上机执行程序除了需要存储空间来寄存本身所用指令、常数、变量和输入数据外,也需要一些对数据进行操作的工作单元和存储一些为实现计算所需信息的存储空间。若输入数据所占空间只取决于问题本身,和算法无关,则只需要分析除输入和程序之外的额外空间。
Part-I 线性结构
线性结构的特点:在数据元素的非空有限集合中,(1) 存在唯一的一个被称做“第一个”的数据元素;(2) 存在唯一的一个被称做“最后一个”的数据元素;(3) 除了第一个外,集合中的每个数据元素均只有一个前驱;(4) 除最后一个外,集合中每个数据元素均只有一个后继。2 线性表
线性表。一个线性表是n个数据元素(记录,可以有若干个数据项)的有限序列,其长度可变。[含有大量记录的线性表被称为文件]2.1 顺序表
线性表的顺序表示 – 顺序表。线性表的顺序表示指的是用一组地址连续的存储单元依次存储线性表的数据元素。例 - 用C语言来实现一个简单的顺序表。先为顺序表动态分配以元素大小为单位的n个空间单元;若往顺序表中插入一个元素时若超过了当前所分配的空间则往当前空间中追加m个空间单元。
06.14
[1] 代码简单实现
sequence_list.c
/* sequence_list.c
* 实现一个满足线性表的顺序表的定义的顺序表及一些相关的简单操作
* 2016.06.13 - 06.14
*/
#include <stdio.h>
#include <stdlib.h>
/* 函数退出状态 */
#define MALLOCFAILE -1 // 分配空间失败
#define OK 0 // 程序正常返回值
#define FAILE 1 // 函数返回失败
/* 线性表的顺序表动态分配顺序存储结构 */
#define LIST_INIT_SIZE 100 // 线性表存储空间的初始分配量
#define LIST_INCREMENT 10 // 线性表存储空间的分配增量
typedef char ElemType;
typedef struct {
ElemType *pelem; // 线性表存储空间基址
int len; // 线性表长度
int lsize; // 线性表当前分配的存储空间
}SqList;
/* 为线性表的顺序表创建存储空间 */
int malloc_sq_list(SqList *psql)
{
if (!psql) return FAILE;
// 构造一个空(无值)的线性表
psql->pelem = (ElemType *)malloc(LIST_INIT_SIZE * sizeof(ElemType));
if (!psql->pelem) exit(MALLOCFAILE);
psql->len = 0;
psql->lsize = LIST_INIT_SIZE;
return OK;
}
/* 释放线性表的顺序表的存储空间 */
void free_sq_list(SqList *psql)
{
if (!psql || !psql->pelem) return ;
free(psql->pelem);
psql->pelem = NULL;
psql->len = 0;
psql->lsize = 0;
}
/* 往线性表的顺序表中插入一个元素 */
int insert_elem2sq_list(SqList *psql, int i, ElemType elem)
{
ElemType *newbase, *p, *q;
if (!psql || !psql->pelem) return FAILE;
// 在顺序线性表psql第i个位置之前插入新的元素elem
if (i < 1 || i > psql->len + 1) return FAILE;
if (psql->len >= psql->lsize) {
newbase = (ElemType *)realloc(psql->pelem, \
(psql->lsize + LIST_INCREMENT) * sizeof(ElemType));
if (!newbase) exit(MALLOCFAILE);
psql->pelem = newbase;
psql->lsize += LIST_INCREMENT;
}
q = &psql->pelem[i - 1]; // 插入位置
for (p = &psql->pelem[psql->len - 1]; p >= q; --p) {
*(p + 1) = *q; // 插入位置及之后的元素后移
}
*q = elem;
++psql->len;
return OK;
}
/* 将两个顺序表合并到另一个顺序表中 */
void merge_sq_list(SqList *psqla, SqList *psqlb, SqList *psqlc)
{
// 已知顺序线性表psqla,psqlb的元素按值非递减排列
// 归并psqla, psqlb得到的新顺序线性表psqlc的元素也按值非递减排列
ElemType *pa, *pb, *pc;
ElemType *pa_last, *pb_last;
if (!psqla || !psqlb || !psqla->pelem || !psqlb->pelem) return ;
pa = psqla->pelem;
pb = psqlb->pelem;
psqlc->lsize = psqlc->len = psqla->len + psqlb->len;
pc = psqlc->pelem = (ElemType *)malloc(psqlc->lsize * sizeof(ElemType));
if (!pc) exit(MALLOCFAILE);
pa_last = psqla->pelem + psqla->len - 1;
pb_last = psqlb->pelem + psqlb->len - 1;
while (pa <= pa_last && pb <= pb_last) {
if (*pa <= *pb) *pc++ = *pa++;
else *pc++ = *pb++;
}
while (pa <= pa_last) *pc++ = *pa++;
while (pb <= pb_last) *pc++ = *pb++;
}
/* 简单测试以上各个函数 */
int main(void)
{
int i, rv;
ElemType elem;
SqList psqla, psqlb, psqlc;
i = 1;
elem = 1;
// 创建顺序线性表空间
if ((rv = malloc_sq_list(&psqla)) != OK || \
(rv = malloc_sq_list(&psqlb)) != OK ) {
fprintf(stderr, "Create sequence list failed\n");
exit(FAILE);
}
// 往顺序线性表中插入值
insert_elem2sq_list(&psqla, i++, elem++);
insert_elem2sq_list(&psqlb, i, elem);
printf("%d %d\n", *psqla.pelem, psqlb.pelem[--i]);
// 合并两个线性表
merge_sq_list(&psqla, &psqlb, &psqlc);
printf("%d %d\n", *psqlc.pelem, psqlc.pelem[i]);
// 释放顺序线性表
free_sq_list(&psqla);
free_sq_list(&psqlb);
free_sq_list(&psqlc);
return 0;
}06.15
-man realloc-
原型。void *realloc(void *ptr, size_t size);
功能。realloc函数将ptr所指向的内存块的大小改为size字节大小(原内容不会被改变)。如果新的大小大于原来的大小,新增的内存块不会被初始化。如果ptr为NULL,那么realloc相当于malloc(size);如果size等于0并且ptr不为NULL,则该调用相当于free(ptr)。除非ptr为NULL,否则ptr必须是之前malloc(),calloc()或realloc()的返回值。如果指向的区域被移动,则原来的内存区域会被自动的free(ptr)。
返回值。realloc()函数返回一个指向新内存区域的指针,若请求失败则返回NULL。如果size等于0,NULL或者传递给free()函数过后的指针将被返回。如果realloc()失败,则原来的内存块将不变;它不会被释放或移除。
[2] 算法复杂度分析
insert_elem2sq_list具有重复(循环)的是元素的移动操作,最坏的情况是将元素插入到表中的第一个元素之前(需要移动n个元素 – 假设表具有n个元素)。insert_elem2sq_list的复杂度可用O(n)来表示。同理,合并俩链表的操作的时间复杂度也为O(n)。[《CSAPP》中有更细致的分析]
线性表的特点是逻辑关系相邻的两个数据元素在内存中存储位置也是相邻关系,因此可以用一个简单的、直观的公式来表示(在C语言中也能够用简单的方式访问,如下标、偏移)。然而这种存储结构也有一个弱点:在作插入或删除操作时,需要移动大量元素。
2.2 链表
(1) 线性链表
线性链表。线性链表的存储结构特点是各个逻辑关系相邻的数据元素既可以用连续的内存单元存储也可以用非连续的内存单元存储。[见链表的结点 —— 因为每个结点中只含有一个指针域,故而称这样的链表为线性链表或单链表]链表的结点。为了表示线性链表中ai与ai+1元素之间的逻辑关系(ai+1为ai的后继元素),ai除了要存储本身的信息外,还要存储ai+1的地址信息(指针域),ai中的这两部分信息被称为结点。
例 – 用C语言实现一个简单的单链表。
06.17
[1] 代码简单实现
single_link_list.c
/* signle_link_list.c
* 单链表线性表的简单表示和实现
* 2016.06.15 - 06.17
*/
#include <stdlib.h>
#include <stdio.h>
/* 函数返回值 */
#define NK -1 // 函数未正常返回
#define OK 0 // 函数正常返回
#define NP 1 // 函数参数不合法
#define ME 2 // 空间分配失败
/* 描述单链表的结构体类型 */
typedef char ElemType;
typedef struct _single_link_list_node {
ElemType data; // 数据域
struct _single_link_list_node *next; // 指针域
}SLNode, SLHead;
/* 创建一个包含n个结点的单链表,每个结点的数据域为创建时结点的顺序 */
SLHead *create_single_link_list(unsigned n)
{
unsigned i;
SLHead *head;
SLNode *pcn, *pln;
i = 0;
if (n < 1) return NULL;
// 头结点
if (NULL == (head = (SLNode *)malloc(sizeof(SLNode)))) {
fprintf(stderr, "head of link list malloc failed\n");
exit(ME); // 退出本进程,进程用户空间被回收从而堆空间自然被回收
}
head->data = 0;
head->next = NULL;
pln = head;
// 单链表中的结点
while (n--) {
if (NULL == (pcn = (SLNode *)malloc(sizeof(SLNode)))) {
fprintf(stderr, "%d th node malloc failed\n", ++i);
exit(ME);
}
pcn->next = NULL;
pcn->data = ++i;
pln->next = pcn;
pln = pcn;
}
return head;
}
/* 释放具有n个结点的单链表 */
void free_single_link_list(SLHead *head)
{
SLNode *pcn, *pnn;
pcn = pnn = head;
while (pcn) {
pnn = pnn->next;
free(pcn);
pcn = pnn;
}
}
/* 往单链表中的第i个结点前插入一个元素 */
int insert_node2link_list(SLHead *head, unsigned i, ElemType e)
{
int j;
SLNode *pcn, *pnewn;
if (!head) return NP;
j = 0;
pcn = head;
while (pcn && j < i - 1) { // 寻找i - 1个结点
pcn = pcn->next;
++j;
}
if (!pcn || j > i - 1) return NK;
if ((pnewn = (SLNode *)malloc(sizeof(SLNode))) == NULL) {
fprintf(stderr, "insert %d element failed\n", e);
return NK;
}
pnewn->data = e;
pnewn->next = pcn->next;
pcn->next = pnewn;
return OK;
}
/* 合并两个单链表 */
/* 已知两个单链表元素按值非减排列 */
/* 归并两个链表得到新链表,新链表也按照值非递减排列 */
SLHead *merge_link_list(SLHead *heada, SLHead *headb)
{
SLNode *la, *lb, *lc, *headc;
if (!heada || !headb) return ;
la = heada->next;
lb = headb->next;
headc = lc = heada;
while (la && lb) {
if (la->data <= lb->data) {
lc->next = la;
lc = la;
la = la->next;
} else {
lc->next = lb;
lc = lb;
lb = lb->next;
}
}
lc->next = la ? la : lb;
free(headb);
return headc;
}
/* 输出单链表的所有元素 */
void print_link_list_node_value(SLHead *head)
{
SLNode *p;
if (!head) return;
p = head->next;
while (p) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}
/* 简单测试单链表 */
int main(void)
{
int i;
SLHead *ha, *hb, *hc;
unsigned la_len, lb_len;
la_len = lb_len = 7;
if (NULL != (ha = create_single_link_list(la_len)))
print_link_list_node_value(ha);
if (NULL != (hb = create_single_link_list(lb_len)))
print_link_list_node_value(hb);
hc = merge_link_list(ha, hb);
print_link_list_node_value(hc);
for (i = 1; i < 15; ++i)
insert_node2link_list(hc, i, i);
print_link_list_node_value(hc);
free_single_link_list(hc);
return 0;
}在shell下编译并运行single_link_list.c得以下结果:
[2] 复杂度分析
同顺序表,单链表的插入操作的时间复杂度为O(n)。合并单链表的时间复杂度也为O(n)。
(2) 循环链表
循环链表。循环链表的最后一个数据元素指向第一个数据元素(其他同线性链表)。(3) 双向链表
双向链表。双向链表的结点中有两个指针域,该结点中的一个指针域指向后驱元素,一个指针域指向前趋元素。例 — 用C语言实现一个简单的双向链表。
06.22
double_link_list.c
/* double_link_list.c
* 双向链表的简单描述
* 2016.06.17 - 06.22
*/
#include <stdio.h>
#include <stdlib.h>
/* 函数返回值 */
#define NK -1 // 函数非正常返回
#define OK 0 // 函数正常返回
#define EP 1 // 参数不合法
typedef char ElemType; // 双向链表中数据域中的数据类型
/* 描述双向链表的结构体 */
typedef struct _DulNode {
ElemType dt;
struct _DulNode *pr;
struct _DulNode *pn;
unsigned nm;
}DulNode, *DuLinkList;
/* 创建双向链表 */
/* 结点中的数据域的值为结点被创建时的个数 */
DuLinkList create_dul_link_list(unsigned n)
{
int i;
DuLinkList head, ps, nt;
if (NULL == (ps = (DulNode *)malloc(sizeof(DulNode)))) {
exit(NK);
}
i = 1;
ps->pr = NULL;
ps->pn = NULL;
ps->dt = i;
head = ps;
ps->nm = i;
while (--n) {
if (NULL == (nt = (DulNode *)malloc(sizeof(DulNode)))) {
exit(NK);
}
ps->pn = nt;
nt->pr = ps;
nt->dt = ++i;
ps = nt;
head->nm++;
}
ps->pn = head;
head->pr = ps;
return head;
}
/* 释放双向链表 */
void free_dul_link_list(DuLinkList dl)
{
int i;
unsigned n;
DuLinkList pr, pn;
if (!dl) return;
n = dl->nm;
pr = dl;
pn = dl->pn;
for (i = 1; i <= n; ++i) {
if (pr) {
free(pr);
pr = pn;
pn = pn->pn;
}
}
}
/* 合并俩双向链表 */
DuLinkList merge_dul_link_list(DuLinkList dla, DuLinkList dlb)
{
// 已知双向链表dla和dlb按值递增排列
// 将dla和dlb合并成一个双向链表(递增排列)
unsigned dla_nm, dlb_nm;
DuLinkList dlc, head, tail;
if (!dla || !dlb) return NULL;
dla_nm = dla->nm;
dlb_nm = dlb->nm;
if (dla->dt <= dlb->dt) {
dlc = head = dla;
dla = dla->pn;
dla_nm--;
} else {
dlc = head = dlb;
dlb = dlb->pn;
dlb_nm--;
}
head->nm = dla_nm + dlb_nm + 1;
while (dla_nm && dlb_nm) {
if (dla->dt <= dlb->dt) {
dlc->pn = dla;
dla->pr = dlc;
dlc = dla;
dla = dla->pn;
dla_nm--;
} else {
dlc->pn = dlb;
dlb->pr = dlc;
dlc = dlb;
dlb = dlb->pn;
dlb_nm--;
}
}
tail = dla_nm ? dla : dlb;
dlc->pn = tail;
tail->pr = dlc;
dlc = tail;
dlc->pn = head;
head->pr = dlc;
return head;
}
/* 打印双向链表中的内容 - 验证 */
void print_dul_node_value(DuLinkList dl)
{
unsigned i, n;
if (!dl) return ;
i = 1;
n = dl->nm;
for (i = 1; i <= n; ++i) {
printf("%d ", dl->dt);
dl = dl->pn;
}
printf("\n");
}
/* 简单测试双向链表 */
int main(void)
{
unsigned dl_len;
DuLinkList dla, dlb, dlc;
dl_len = 7;
dla = create_dul_link_list(dl_len);
dlb = create_dul_link_list(dl_len);
print_dul_node_value(dla);
print_dul_node_value(dlb);
dlc = merge_dul_link_list(dla, dlb);
print_dul_node_value(dlc);
//free_dul_link_list(dlc);
return 0;
}运行double_link_list.c得以下结果:
2.3 一元多项式的表示及相加
06.233 栈和队列
3.1 栈及栈的简单应用
栈。栈是限定仅在表尾进行插入或删除操作的线性表。表尾端称为栈顶,表头端称为栈底。顺序栈即利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,同时设置一个指向栈顶元素的指针。[链栈的各个数据元素的存储单元不一定连续](1) 顺序栈
例 – 用C实现一个简单的顺序栈。06.23
一般来说,在初始化设空栈时不应限定栈的最大容量。一个较合理的做法是:先为栈分配一个基本容量,然后在应用过程中,当栈的空间不够使用时在逐段扩大。
[1] 描述栈的结构体类型
/* 描述栈的结构体类型 */
typedef SElemType int;
typedef struct _SqStack{
SElemType *base;
SElemType *top;
int stacksize;
}SqStack;其中,stacksize指示栈的当前可使用的最大容量。栈的初始化操作为:按设定的初始分配量进行第一次分配,base为栈底指针,在顺序栈中,它始终指向栈底的位置,若base的值为NULL,则表明栈结构不存在。称top为栈顶指针,其初值指向栈底,即top=base可作为栈空的标记,每当插入新的栈顶元素时,指针top增1;删除栈顶元素时,指针top减1,因此,非空栈中的栈顶指针始终在栈顶元素的下一个位置上。
[2] 跟栈相关的基本操作
06.26
stack_basic.c
/* stack_basic.c
* 栈的简单描述与实现
* 2016.06.23 - 06.26
*/
#include <stdio.h>
#include <stdlib.h>
#define STACK_INIT_SIZE 100 // 栈空间初始分配大小
#define STACKINCREMENT 10 // 栈空间分配增量
#define OK 0 // 函数正常返回
#define NK 11 // 函数非正常返回
#define NP 22 // 函数参数无效
/* 描述栈的结构体类型 */
typedef int SElemType;
typedef struct _SqStack{
SElemType *base;
SElemType *top;
int stacksize;
}SqStack;
/* 基本操作 */
// 构造一个空栈 - 为栈分配空间,指向栈顶与栈底的变量都指向栈底
int init_stack(SqStack *stack)
{
if (!stack) return NP;
stack->base = (SElemType *)malloc(STACK_INIT_SIZE * sizeof(SElemType));
if (!stack->base) return NK;
stack->top = stack->base;
stack->stacksize = STACK_INIT_SIZE;
return OK;
}
// 销毁栈 - 释放为栈分配的空间
void destroy_stack(SqStack *stack)
{
if (!stack) return;
if (stack->base) {
stack->stacksize = 0;
free(stack->base);
stack->base = NULL;
stack->top = NULL;
}
}
// 将栈设为空栈 - 将指向栈顶的变量指向栈底
void clear_stack(SqStack *stack)
{
if (!stack) return;
if (stack->top && stack->base)
stack->top = stack->base;
}
// 判断是否为空栈
int is_stack_empty(SqStack *stack)
{
if (stack && stack->base && stack->top)
return (stack->base == stack->top);
else
return NP;
}
// 获取栈的长度
int get_stack_length(SqStack *stack)
{
if (stack) return stack->stacksize;
else return NP;
}
// 获取栈顶元素
SElemType get_top(SqStack *stack)
{
SElemType *top;
if (stack && stack->top && stack->base && \
stack->top != stack->base) {
top = stack->top - 1;
return *top;
}
return NP;
}
// 往栈顶中插入一个元素
int push(SqStack *stack, SElemType e)
{
int status;
SElemType *base;
status = is_stack_empty(stack);
if (NP != status) {
if (stack->top - stack->base < stack->stacksize) { // 栈未满
*stack->top = e;
stack->top++;
return OK;
} else { // 栈已满
base = (SElemType *)realloc(stack->base, (stack->stacksize + STACKINCREMENT) * sizeof(SElemType));
if (base) return (NK);
stack->base = base;
stack->stacksize += STACKINCREMENT;
*stack->top = e;
stack->top++;
return OK;
}
}
return NP;
}
// 删除栈顶元素
int pop(SqStack *stack)
{
int status;
status = is_stack_empty(stack);
if (NP != status && !status) {
stack->top--;
return OK;
}
return NK;
}
// 遍历栈
void traverse_stack(SqStack *stack)
{
int status;
SElemType *pe;
status = is_stack_empty(stack);
if (NP != status && !status) {
pe = stack->top - 1;
while (pe - stack->base) {
printf("%d ", *pe--); // int
}
printf("%d\n", *pe);
}
}
/* 简单测试栈 - 部分函数 */
int main(void)
{
int i, rv;
SqStack stack;
if ((rv = init_stack(&stack)) != OK) // 初始化栈
exit(NK);
for (i = 0; i < STACK_INIT_SIZE; ++i) // 入栈
push(&stack, i);
traverse_stack(&stack); // 遍历栈
destroy_stack(&stack); // 销毁栈
return 0;
}在shell中运行该程序,得到以下测试结果:
(2) 栈的简单应用
06.27[还相差甚远]
[1] 数制转换
[2] 括号匹配的检验
[3] 行编辑程序
[4] 迷宫求解
[5] 表达式求值
3.2 栈与递归的实现
06.28[…如汉诺塔、八皇后问题…]
3.3 队列
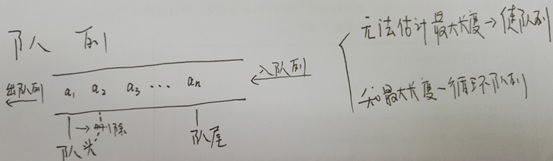
队列。队列是一种先进先出的线性表。它只允许在表的一端(队尾)进行插入,而在另一端(队头)删除元素。(1) 链队列
!例 – 用C语言实现一个简单的链队列程序。…
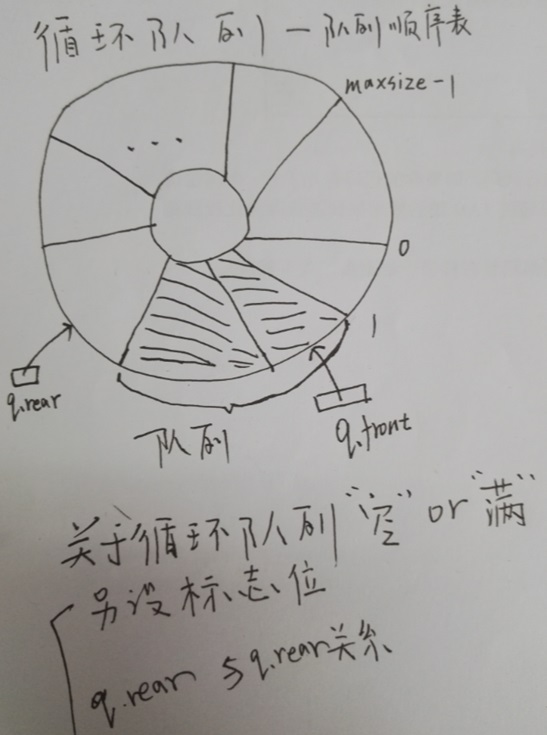
(2) 循环队列
3.4 离散事件模拟
[..银行业务模拟程序..]06.09
4 串
4.1 串的基本操作
串(字符串)。串是由零个或多个字符组成的有限序列。串定长顺序存储表示。用一组地址连续的内存单元存储串值的字符序列。
堆分配存储表示。仍以一组地址连续的内存单元存储串值的字符序列,但它们的存储空间是在程序执行过程中动态分配的。
串的块链存储表示。以结点方式存储各个串。
06.30
例 – 用C语言编写一个简单的关于串(顺序存储方式)的程序。(串比较、串连接、求串长度、串模式匹配等)[串相关的操作无须涉及任何与内核交互,《TCPL》等书涉及关于串函数的一些编写内容,本书中的模式匹配算法可以值得(因为没怎么看过)一看]。。
4.2 串的简单应用
06.29(1) 文本编辑
(2) 建立词索引表
信息检索主要操作。在大量存放的磁盘上的信息中查询一个特定的信息(为了提高查询效率,一个重要的问题就是建立一个好的索引系统)。[2016.06.12 - 10:15]

相关文章推荐
- 数据结构(树链剖分,线段树):SDOI 2016 游戏
- 数据结构 Merge合并排序
- 万山千山都是情,你说行我就行之大型数据结构纪录篇之顺序
- HDUOJ_1166_敌兵布阵_线段树
- SDUTACM数据结构上机测试2-1:单链表操作A
- c/c++数据结构 栈和队列
- [python]修改SQL返回值数据结构
- 编程就是算法和数据结构,算法和数据结构是编程的灵魂。
- 优先级队列之堆实现
- 数据结构与算法之七 栈
- 数据结构与算法之七 栈
- 数据结构与算法之七 栈
- 【数据结构】二叉搜索树
- 【数据结构】AVL树
- 【数据结构】常见的7种比较排序算法2
- 【数据结构】非比较排序算法(实现计数排序和基数排序)
- 【数据结构】常见的7种比较排序算法1
- 树的相关必备理论
- 数据结构与算法之六 双向链表和循环链表
- 数据结构与算法之六 双向链表和循环链表