使用scrapy-redis构建简单的分布式爬虫
2016-06-11 03:41
627 查看
前言
scrapy是python界出名的一个爬虫框架。Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。虽然scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘。有能人改变了scrapy的队列调度,将起始的网址从start_urls里分离出来,改为从redis读取,多个客户端可以同时读取同一个redis,从而实现了分布式的爬虫。就算在同一台电脑上,也可以多进程的运行爬虫,在大规模抓取的过程中非常有效。
准备
既然这么好能实现分布式爬取,那都需要准备什么呢?需要准备的东西比较多,都有:
- scrapy
- scrapy-redis
- redis
- mysql
- python的mysqldb模块
- python的redis模块
为什么要有mysql呢?是因为我们打算把收集来的数据存放到mysql中
1. scrapy安装
pip install scrapy
也可以clone下相应的github地址https://github.com/scrapy/scrapy/tree/1.1
2. scrapy-redis安装
pip install scrapy-redis
同样可以clone下相应的github地址https://github.com/rolando/scrapy-redis
他俩具体有什么区别呢?https://www.zhihu.com/question/32302268/answer/55724369有知乎大神的回答
3.redis
redis本身只提供了在类linux环境中安装,不支持windows,官网http://redis.io/,如果需要在windows下做练习的朋友,可以参考我的这篇http://blog.csdn.net/howtogetout/article/details/515202544.mysql
因为我们打算用mysql来存储数据,所以mysql的配置是不可或缺的。下载地址http://dev.mysql.com/downloads/5.mysqldb模块和redis模块
为什么需要这2个呢,是因为python不能直接操作数据库,需要通过库来支持。而这2个就是相应数据库的支持库。mysqldb:https://sourceforge.net/projects/mysql-python/files/mysql-python/1.2.3/,windows环境下可以直接下.exe来快速安装
redis:
pip install redis
这样就是最简单的了。
动工
先来看下scrapy-redis的一些不同的地方。
首先就是class的父对象变了,变成了特有的RedisSpider,这是scrapy-redis里面自己定义的新的爬虫类型。其次就是不再有start_urls了,取而代之的是redis_key,scrapy-redis将key从list中pop出来成为请求的url地址。
我们这次选取的对象是58同城的平板电脑信息。
首先来看一下架构信息。

scrapy.cfg文件我们可以不管,readme.rst文件也不管(这个是github上有用的,scrapy创建项目的时候并没有)
pbdnof58文件夹内的结构:

items定义文件,settings设置文件,pipelines处理文件以及spiders文件夹。
spiders文件夹盛放着我们编写的具体爬虫:
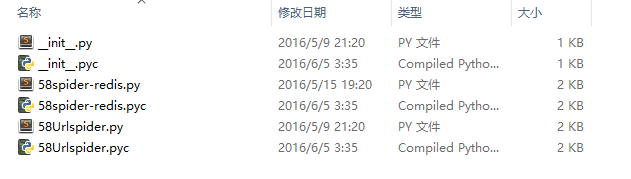
可以看到里面有2个爬虫,一个是用来爬所有的url地址,并将其传递给redis。而另外一个则是根据爬取出来的地址处理具体的商品信息。
具体来看。首先是settings.py文件。
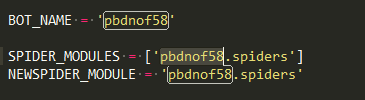
跟scrapy一样,写明spider的位置。
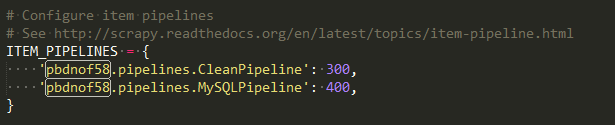
2个处理数据的pipeline中的类,数字越小优先执行。
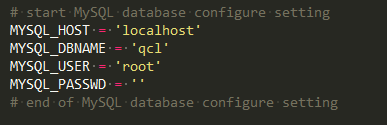
因为数据要存放在mysql中,所以需要配置下mysql的信息。而redis是默认采用本地的,所以并没有配置信息,如果是连接别的主机的话,需要配置下redis的连接地址。
item.py文件
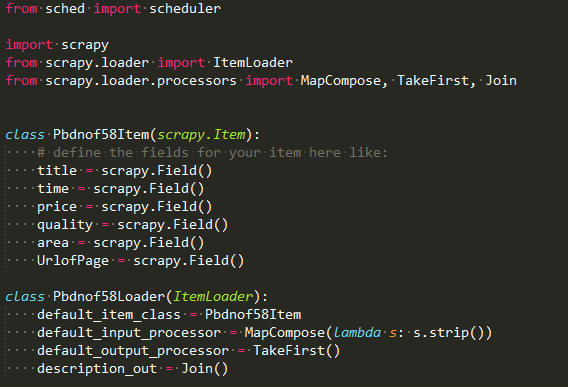
与scrapy相比多了个调度文件,多了个ItemLoader类,照着做就好了,ItemLoader类后面会用到的。
pipeline.py文件
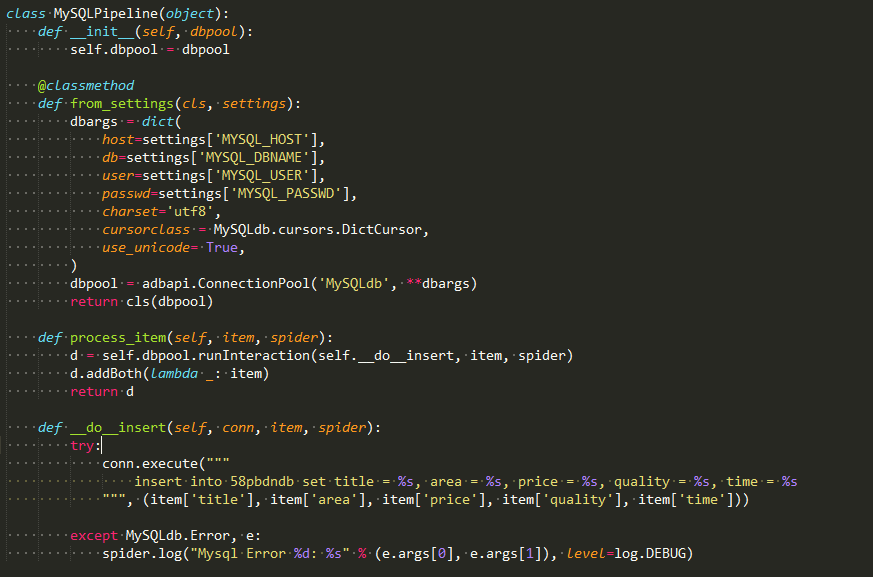
最重要的是这个将结果存储到mysql中。
要在一个名为qcl的数据库之中建一个名叫58pbdndb的表。qcl对应settings的配置。
create table 58pbdndb( id INT NOT NULL AUTO_INCREMENT, title VARCHAR(100) NOT NULL, price VARCHAR(40) NOT NULL, quality VARCHAR(40), area VARCHAR(40), time VARCHAR(40) NOT NULL, PRIMARY KEY ( id ) )DEFAULT CHARSET=utf8;
注意:我并没有在表的一开始检查字段是否存在,如果你在调试过程中不止一次的话,你可能需要多次删除表中数据。
58Urlspider.py文件
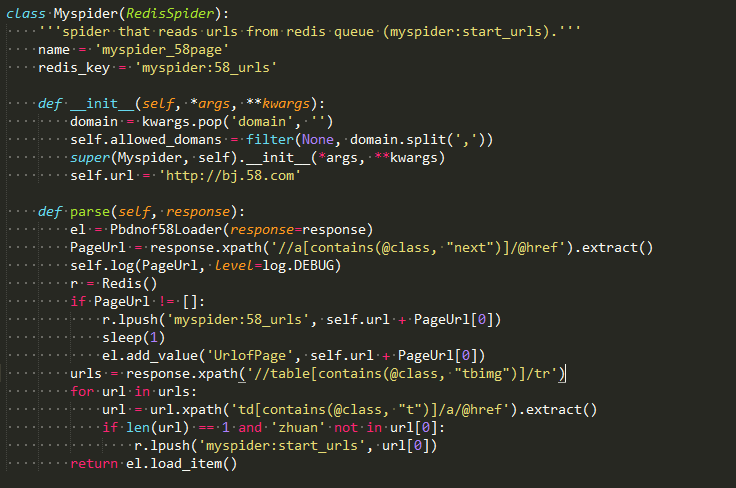
这个爬虫实现了2个功能。1是如果next(也就是下一页)存在,则把下一页的地址压进redis的myspider:58_urls的这个list中,供自己继续爬取。2是提取出想要爬取的商品具体网址,压进redis的myspider:start_urls的list中,供另一个爬虫爬取。
58spider-redis.py文件
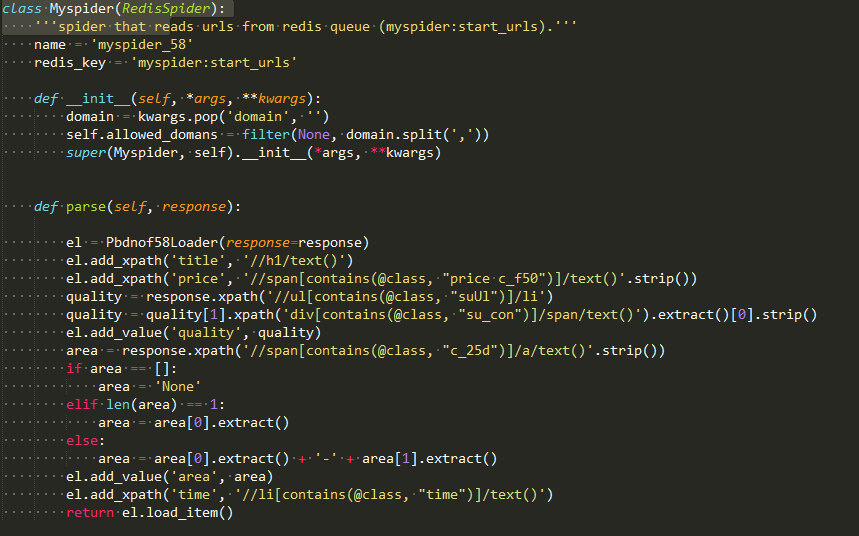
这个爬虫是用来抓取具体的商品信息。可以看到ItemLoader类的add_path和add_value方法的使用。
最后
运行方法跟scrapy相同,就是进入pbdnof58文件夹下(注意下面是只有spiders文件夹的那个).输入scrapy crawl myspider_58page和scrapy crawl myspider_58
可以输入多个来观察多进程的效果。。打开了爬虫之后你会发现爬虫处于等待爬取的状态,是因为2个list此时都为空。所以需要
lpush myspider:58_urls http://hz.58.com/pbdn/0/
来设置一个初始地址,好啦,这样就可以愉快的看到所有的爬虫都动起来啦。
最后来张数据库的图
本文相对比较简单,只是scrapy-redis的基本应用。本人也比较小白,刚刚开始学习,如有什么问题,欢迎提出来共同进步。
ps:本文的github地址:https://github.com/qcl643062/spider/tree/master/pbdnof58

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- redis安装问题小结
- 爬虫笔记
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用