meta标签有毒
2016-05-29 15:41
363 查看
今天要完成的一项工作是:从 html文件中提取,title标签
原本以为是很简单的工作呢。可是一个素食网站里面,像这些http://www.chinavegan.com/2015/05/2015051718461747.html
网页,当我用 httpclient下载页面,然后用jsoup进行解析的时候,发现,document对象里面,title标签,h1标签统统都没有了。可是,我再去下载好的网页时看,咦,title、h1标签都是存在的啊。
怎么回事?
后俩比较一下 如下的两个网页:
http://www.chinavegan.com/2015/05/2015051718461747.htm
(抽不出 title、h1标签内容,因为jsoup解析的时候,documnet里面根本没有 这两类标签)
http://www.chinavegan.com/
(可以抽出 title、h1标签内容)
原因是:


看到没,下面那张图片里面少了:
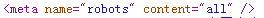
~~~~~~~~~~~~~~~~~~~~
my god,我笨,我调了那么长时间,终于找到了错误。
然后:
我首先采取,手工 输入这句话,果然 普通页面也可以提取title了。
接着,我天真的以为,
方法一:可以通过 文件 读写的方式,来给每个 普通网页在title标签之前,加上
这句话。结果各种错误,说明这样使不可行的
方法二:
我采用 jsoup的各种方式,企图向head标签后面加入
事实证明是无用的。title标签依旧不在jsoup中。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
以上两种方法,都没有抓住源头,源头的错误,应该是出现在下载网页的时候。方正,最后我参考了这篇文章,采用java的url,全部读取网页内容,然后使用正则表达式,终于搞定了,成功提取title.
参考的帖子:http://blog.csdn.net/yuyuyuyuy/article/details/6547430
总结:jsoup+httpclient,虽然方便,
但是关键时刻还是得靠 正则表达式+java.url
原本以为是很简单的工作呢。可是一个素食网站里面,像这些http://www.chinavegan.com/2015/05/2015051718461747.html
网页,当我用 httpclient下载页面,然后用jsoup进行解析的时候,发现,document对象里面,title标签,h1标签统统都没有了。可是,我再去下载好的网页时看,咦,title、h1标签都是存在的啊。
怎么回事?
后俩比较一下 如下的两个网页:
http://www.chinavegan.com/2015/05/2015051718461747.htm
(抽不出 title、h1标签内容,因为jsoup解析的时候,documnet里面根本没有 这两类标签)
http://www.chinavegan.com/
(可以抽出 title、h1标签内容)
原因是:
看到没,下面那张图片里面少了:
~~~~~~~~~~~~~~~~~~~~
my god,我笨,我调了那么长时间,终于找到了错误。
然后:
我首先采取,手工 输入这句话,果然 普通页面也可以提取title了。
接着,我天真的以为,
方法一:可以通过 文件 读写的方式,来给每个 普通网页在title标签之前,加上
这句话。结果各种错误,说明这样使不可行的
方法二:
我采用 jsoup的各种方式,企图向head标签后面加入
事实证明是无用的。title标签依旧不在jsoup中。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
以上两种方法,都没有抓住源头,源头的错误,应该是出现在下载网页的时候。方正,最后我参考了这篇文章,采用java的url,全部读取网页内容,然后使用正则表达式,终于搞定了,成功提取title.
参考的帖子:http://blog.csdn.net/yuyuyuyuy/article/details/6547430
package catchhtml;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetHtmlTitle {
public GetHtmlTitle(String htmlUrl){
System.out.println("/n------------开始读取网页(" + htmlUrl + ")-----------");
String htmlSource = "";
htmlSource = getHtmlSource(htmlUrl);//获取htmlUrl网址网页的源码
System.out.println("------------读取网页(" + htmlUrl + ")结束-----------/n");
System.out.println("------------分析(" + htmlUrl + ")结果如下-----------/n");
String title = getTitle(htmlSource);
System.out.println("网站标题: " + title);
}
/**
* 根据网址返回网页的源码
* @param htmlUrl
* @return
*/
public String getHtmlSource(String htmlUrl){
URL url;
StringBuffer sb = new StringBuffer();
try{
url = new URL(htmlUrl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));//读取网页全部内容
String temp;
while ((temp = in.readLine()) != null)
{
sb.append(temp);
}
in.close();
}catch (MalformedURLException e) {
System.out.println("你输入的URL格式有问题!请仔细输入");
}catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* 从html源码(字符串)中去掉标题
* @param htmlSource
* @return
*/
public String getTitle(String htmlSource){
List<String> list = new ArrayList<String>();
String title = "";
//Pattern pa = Pattern.compile("<title>.*?</title>", Pattern.CANON_EQ);也可以
Pattern pa = Pattern.compile("<title>.*?</title>");//源码中标题正则表达式
Matcher ma = pa.matcher(htmlSource);
while (ma.find())//寻找符合el的字串
{
list.add(ma.group());//将符合el的字串加入到list中
}
for (int i = 0; i < list.size(); i++)
{
title = title + list.get(i);
}
return outTag(title);
}
/**
* 去掉html源码中的标签
* @param s
* @return
*/
public String outTag(String s)
{
return s.replaceAll("<.*?>", "");
}
public static void main(String[] args) {
String htmlUrl = "http://www.157buy.com";
new GetHtmlTitle(htmlUrl);
}
}总结:jsoup+httpclient,虽然方便,
但是关键时刻还是得靠 正则表达式+java.url

相关文章推荐
- 在Windows 8.1的IE 11中屏蔽双击放大功能
- HTML5调用摄像头实例
- Apple官网研究之使用Justify布局导航
- 关于前端的思考与感悟
- 通过Mootools 1.2来操纵HTML DOM元素
- jQuery Html控件基本操作(日常收集整理)
- WEB标准网页布局中尽量不要使用的HTML标签
- Flash 与 html 的一些实用技巧
- html工作中表格<tbody>标签的使用技巧
- HTML 向 XHTML1.0 兼容性指导
- C#自写的一个HTML解析类(类似XElement语法)
- 没有文件大小限制并免费的PDF到HTML转换工具
- JavaScript与HTML结合的基本使用方法整理
- Ruby编写HTML脚本替换小程序的实例分享
- css实现气泡框效果(实例加图解)
- html链接与文本标签们
- html活用软字符连接符
- 浅谈html中id和name的区别实例代码
- HTML <!DOCTYPE> 标签