决策树ID3 Java程序
2016-05-26 10:59
393 查看
决策树基本概念
ID3算法,利用信息增益进行分类属性
经典数据集
下面测试数据时候只用到@data下面的部分
下面介绍程序流程
定义结点:TreeNode类
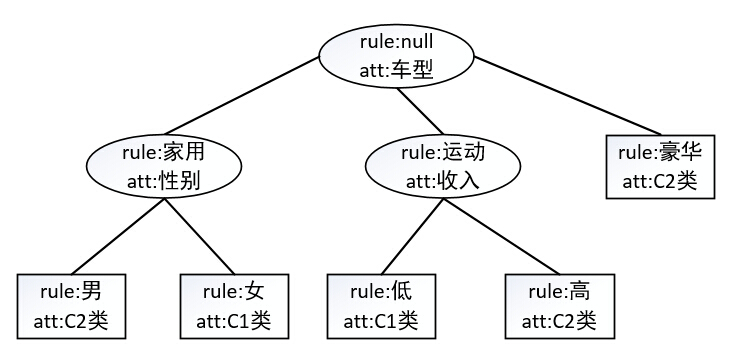
attribute:表示下一个结点分裂时候用到的属性
rule:表示分裂该结点时候属性的取值,主要这个属性是其父结点可能的取值
显然根结点的rule是空
叶子结点的attribute是分类标号
举个例子,如下图所示
数据存储方式:ArrayList<String[]>,每个String数组是一个样本,数据的标签在最后一列,ArrayList中是所有的训练数据
LoadData类
DecisionTree类
计算信息熵
log(p)
计算信息增益,需要计算条件熵

根据上面的公式,需要计算属性不同取值的子数据集的熵
为了,方便计算,我将子数据集取出在计算子数据集的熵,子数据集的格式也是ArrayList<String[]>,只不过是String[]的大小是2,String[0],是该属性的某一维的取值,如上面说的a2,String[1]是类别标签,这样就可以根据上面信息熵的计算程序,计算联合分布的熵,根据属性取值的概率,进而计算条件熵
划分子数据集
根据index,取值该index对于的某个属性和其类别
计算条件熵
输入数据的该属性下的所有数据,每个String数组只有两维,第一维是该属性,第二维是类别
这个输入的数据是经过原始数据集提取某个属性和类别组成的,也就是上面函数的输出
下面需要在所有的属性中寻找最优的分裂属性
返回最优属性的ID
下面就是建树的过程
伪代码:
空树,返回
子数据都是一类,返回该子数据的类别,停止建树
其他:
遍历寻找最优分类属性
根据该属性的不同取值,构建子结点
子结点 对于数据 递归建树
这里已经说完
下面输出构建的决策树
level:用来定义空格的数量,输出树形的格式
上面数据集输出结果:
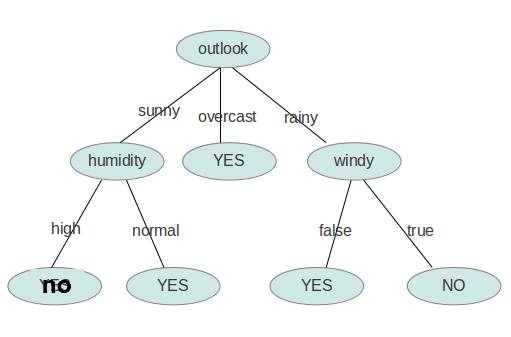
贴个图
构建好了决策树,我们的任务是分类,当然还要有预测分类的程序
只需要从根结点开始向下走,走到叶子结点就是答案
利用上面的数据进行预测,准确率当然是100%了
贴上Test类
这个博客中买电脑数据集
属性
输出决策树和自我预测结果
数据没有噪声,当然预测效果比较好了
ID3算法,利用信息增益进行分类属性
经典数据集
@relation weather.symbolic
@attribute outlook {sunny, overcast, rainy}
@attribute temperature {hot, mild, cool}
@attribute humidity {high, normal}
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
@data
sunny,hot,high,FALSE,no
sunny,hot,high,TRUE,no
overcast,hot,high,FALSE,yes
rainy,mild,high,FALSE,yes
rainy,cool,normal,FALSE,yes
rainy,cool,normal,TRUE,no
overcast,cool,normal,TRUE,yes
sunny,mild,high,FALSE,no
sunny,cool,normal,FALSE,yes
rainy,mild,normal,FALSE,yes
sunny,mild,normal,TRUE,yes
overcast,mild,high,TRUE,yes
overcast,hot,normal,FALSE,yes
rainy,mild,high,TRUE,no下面测试数据时候只用到@data下面的部分
下面介绍程序流程
定义结点:TreeNode类
import java.util.ArrayList;
public class TreeNode {
String attribute;//属性
String rule;// 规则:属性的取值
ArrayList<TreeNode> children ;// 如果定义成HashMap 的形式,key表示该孩子结点的attribute值,而value是该孩子结点
boolean isLeaf = false;//默认不是叶子结点
public TreeNode(){
children = new ArrayList<TreeNode>();
}
public TreeNode(String attribute){
this.attribute = attribute;
children = new ArrayList<TreeNode>();
}
public TreeNode(String value,String rule){
this.attribute = value;
this.rule = rule;
children = new ArrayList<TreeNode>();
}
public TreeNode(String value,String rule,ArrayList<TreeNode> children){
this.attribute = value;
this.rule = rule;
children = new ArrayList<TreeNode>();
}
public TreeNode(String value,ArrayList<TreeNode> children){
this.attribute = value;
this.children = children;
}
public void addChildren(TreeNode child){
children.add(child);
}
public ArrayList<TreeNode> getChildren(){
return children;
}
}attribute:表示下一个结点分裂时候用到的属性
rule:表示分裂该结点时候属性的取值,主要这个属性是其父结点可能的取值
显然根结点的rule是空
叶子结点的attribute是分类标号
举个例子,如下图所示
数据存储方式:ArrayList<String[]>,每个String数组是一个样本,数据的标签在最后一列,ArrayList中是所有的训练数据
LoadData类
package decisionTree;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
public class LoadData {
public ArrayList<String[]> readData(String fileName){
File file = new File(fileName);
FileReader fr = null;
try {
fr = new FileReader(file);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
BufferedReader br = new BufferedReader(fr);
ArrayList<String[]> data = new ArrayList<String[]>();
String row = new String();
try {
while((row=br.readLine())!=null){
data.add(row.split(","));
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return data;
}
}DecisionTree类
计算信息熵
/**
* 计算信息熵
* @param subData
* @return
*/
public double Ent(ArrayList<String[]> subData){
HashMap<String,Integer> map = new HashMap<String,Integer>();
double ent = 0.0;
String[] samp = subData.get(0);
int len = samp.length;
String label = "";
double p=0.0;
for(int i=0;i<subData.size();i++){
label = subData.get(i)[len-1];
if(map.containsKey(label)){
map.put(label, map.get(label) + 1);
}else{
map.put(label, 1);
}
}
Collection<Integer> values = map.values();
for(Integer value:values){
p = value*1.0/subData.size();
ent+=p*log2(p);
}
return -ent;
}log(p)
/**
* log2(val)
* @param val
* @return
*/
public double log2(double val){
if(val==0)
return 0;
return Math.log(val)/Math.log(2);
}计算信息增益,需要计算条件熵
根据上面的公式,需要计算属性不同取值的子数据集的熵
为了,方便计算,我将子数据集取出在计算子数据集的熵,子数据集的格式也是ArrayList<String[]>,只不过是String[]的大小是2,String[0],是该属性的某一维的取值,如上面说的a2,String[1]是类别标签,这样就可以根据上面信息熵的计算程序,计算联合分布的熵,根据属性取值的概率,进而计算条件熵
划分子数据集
根据index,取值该index对于的某个属性和其类别
/**
* splitData 划分后 String[] 是二维形式,某个属性,类别
* @param subData
* @param index
* @return
*/
public ArrayList<String[]> splitDataSet(ArrayList<String[]> subData,int index){
ArrayList<String[]> splitData = new ArrayList<String[]>();
String[] samp = subData.get(0);
int len = samp.length;
for(int i =0;i<subData.size();i++){
samp = subData.get(i);
splitData.add(new String[]{samp[index],samp[len-1]});
}
return splitData;
}计算条件熵
输入数据的该属性下的所有数据,每个String数组只有两维,第一维是该属性,第二维是类别
这个输入的数据是经过原始数据集提取某个属性和类别组成的,也就是上面函数的输出
/**
* 计算条件熵
* @param splitData 第一维是特征的取值,这个取值是所有可能的取值,每个List 是 二维数组
* @return
*/
public double findConditionalEntropy(ArrayList<String[]> splitData){
Set<String> features = new TreeSet<String>();
double condEnt = 0.0;
// 该特征的取值可能
for(int i =0;i<splitData.size();i++){
features.add(splitData.get(i)[0]);
}
// 对每个特征,计算该特征下面的熵
for(String feature:features){
ArrayList<String[]> subData = new ArrayList<String[]>();
for(int j =0;j<splitData.size();j++){
if( splitData.get(j)[0].equals(feature)){
subData.add(splitData.get(j));
}
}
condEnt += (subData.size() /splitData.size()) * Ent(subData);
}
return condEnt;
}下面需要在所有的属性中寻找最优的分裂属性
返回最优属性的ID
/**
* 利用信息增益,选取最好的划分特征的下标 最后一维是类别
* @param subData
* @return
*/
public int findBestSplit(ArrayList<String[]> subData){
double ent = Ent(subData);
if(Math.abs(ent)==0) // 类别都是同一类
return -1;
double condEnt = 0.0;
double bestInforGain = Double.MIN_NORMAL;
double inforGain = 0;
int bestFeatureId = 0;
String[] samp = subData.get(0);
int len = samp.length;//特征 大小
ArrayList<String[]> subSplitData = new ArrayList<String[]>();
for(int j=0;j<len-1;j++){
subSplitData = splitDataSet(subData,j);// 特征,类别 ,下面需要计算每个特征下面的信息熵
condEnt = findConditionalEntropy(subSplitData);// 计算条件熵
inforGain = ent - condEnt;// 计算信息增益
if(inforGain > bestInforGain){// 寻找最大的信息增益
bestInforGain = inforGain;
bestFeatureId = j; // 特征对于的ID
}
}
return bestFeatureId;
}下面就是建树的过程
伪代码:
空树,返回
子数据都是一类,返回该子数据的类别,停止建树
其他:
遍历寻找最优分类属性
根据该属性的不同取值,构建子结点
子结点 对于数据 递归建树
/**
* 递归构建决策树
*
* @param data 数据集
* @param attributes 属性名称
* @return
*/
public TreeNode treeGrowth(ArrayList<String[]> data,ArrayList<String> attributes){
if(data == null){// 空
return new TreeNode("end");
}
String[] samp = data.get(0);
int len = samp.length;
String label = samp[len-1];
if(data.size()==1){// 只有一个样本数据
TreeNode node = new TreeNode(label);
node.isLeaf = true;
return node;
}
// 寻找最优的划分属性的ID
int bestFeatureId = findBestSplit(data);
Set<String> featureValues = new TreeSet<String>();
// 同一类的情况
if(bestFeatureId == -1){
TreeNode node = new TreeNode(label);
node.isLeaf = true;
return node;
}
// 该特征的取值可能 bestFeatureId 对应特征的取值
for(int i =0;i<data.size();i++){
featureValues.add(data.get(i)[bestFeatureId]);
}
TreeNode tree = new TreeNode();
String att = attributes.get(bestFeatureId);
tree.attribute = att;
// 去除这个属性
attributes.remove(bestFeatureId);
// 以这个属性的值,划分成不同的子数据集,每个子数据集是孩子结点
for(String value:featureValues){
ArrayList<String[]> subData = new ArrayList<String[]>();
for(int j =0;j<data.size();j++){
// 取出最优分裂属性不同取值对应的数据,构建子树
if( data.get(j)[bestFeatureId].equals(value)){
String[] subStr = new String[len-1];
int i=0;
for(int k=0;k<len;k++){
if(k!=bestFeatureId){ // 去除这一维
subStr[i++] = data.get(j)[k];
}
}
subData.add(subStr);
}
}
// 对每个孩子结点递归遍历,注意需要新建一个ArrayList加入到该新建的ArrayList,否则这个attribute是全局遍历,修改子孩子会影响到其他孩子
TreeNode node = treeGrowth(subData,new ArrayList<String>(attributes));
node.rule = value;// 结点对应规则,父结点属性取值
tree.addChildren(node);// 添加孩子结点
}
return tree;
}这里已经说完
下面输出构建的决策树
level:用来定义空格的数量,输出树形的格式
/**
* 将决策树输出到标准输出
*/
public void outputDecisionTree(TreeNode node,int level) {
if(!node.isLeaf){
for(int i=0;i<level;i++)
System.out.print("\t");
System.out.println(node.rule+" : "+node.attribute);
ArrayList<TreeNode> children = node.getChildren();
for(int i=0;i<children.size();i++){
outputDecisionTree(children.get(i),level+1);
}
}else{
for(int i=0;i<level;i++){
System.out.print("\t");
}
System.out.println(node.rule+" : "+node.attribute);
}
}上面数据集输出结果:
null : outlook overcast : yes rainy : temperature cool : windy FALSE : yes TRUE : no mild : humidity high : windy FALSE : yes TRUE : no normal : yes sunny : temperature cool : yes hot : no mild : humidity high : no normal : yes
贴个图
构建好了决策树,我们的任务是分类,当然还要有预测分类的程序
只需要从根结点开始向下走,走到叶子结点就是答案
public String predict(TreeNode tree,String[] test,ArrayList<String> attributes){
if(tree == null){
return "null1";
}
String att = tree.attribute;
if(tree.isLeaf){
return tree.attribute;
}
int id = -1;
// 找到那个属性
for(int i=0;i<attributes.size();i++){
if(attributes.get(i).equals(att)){
id = i;
break;
}
}
// 找不到了,应该 以这个结点下面的孩子,对于原始子训练集最大的类返回答案,下面我直接返回null
if(id==-1 || id == attributes.size()){
return "null";
}
// 去除已经使用过的属性
attributes.remove(id);
String rule = test[id];// 找到规则值
ArrayList<TreeNode> children = tree.getChildren();
String[] nextTest = new String[test.length-1];
int j=0;
for(int i=0;i<test.length;i++){
if(i!=id)
nextTest[j++] = test[i];
}
for(int i=0;i<children.size();i++){
String r = children.get(i).rule;
if(r.equals(rule)){
return predict(children.get(i),nextTest,new ArrayList<String>(attributes));
}
}
return "null";
}利用上面的数据进行预测,准确率当然是100%了
predict class no no no no yes yes yes yes yes yes no no yes yes no no yes yes yes yes yes yes yes yes yes yes no no
贴上Test类
import java.util.ArrayList;
public class Test {
public static void main(String [] args){
DecisionTree dt = new DecisionTree();
ArrayList<String[]> data;
String fileName ;
fileName = "weather.nominal.arff";
LoadData loadData = new LoadData();
data = loadData.readData(fileName);
ArrayList<String> attributes = new ArrayList<String>();
attributes.add("outlook");
attributes.add("temperature");
attributes.add("humidity");
attributes.add("windy");
TreeNode tree = dt.treeGrowth(data,new ArrayList<String>(attributes));
dt.outputDecisionTree(tree,0);
System.out.println("predict"+"\t"+"class");
for(String[] test:data){
String pre = dt.predict(tree, test, new ArrayList<String>(attributes));
System.out.println(pre+"\t"+test[test.length-1]);
}
}
}这个博客中买电脑数据集
青少年,高,否,一般,否 青少年,高,否,良好,否 中年,高,否,一般,是 老年,中,否,一般,是 老年,低,是,一般,是 老年,低,是,良好,否 中年,低,是,良好,是 青少年,中,否,一般,否 青少年,低,是,一般,是 老年,中,是,一般,是 青少年,中,是,良好,是 中年,中,否,良好,是 中年,高,是,一般,是 老年,中,否,良好,否
属性
attributes.add("年龄");
attributes.add("层次");
attributes.add("学生");
attributes.add("信用");输出决策树和自我预测结果
null : 年龄 中年 : 是 老年 : 层次 中 : 学生 否 : 信用 一般 : 是 良好 : 否 是 : 是 低 : 信用 一般 : 是 良好 : 否 青少年 : 层次 中 : 学生 否 : 否 是 : 是 低 : 是 高 : 否 predict class 否 否 否 否 是 是 是 是 是 是 否 否 是 是 否 否 是 是 是 是 是 是 是 是 是 是 否 否
数据没有噪声,当然预测效果比较好了

相关文章推荐
- 关于final修饰符你不知道的事
- Java调用Windows内cmd命令
- Java开发人员学习路线
- Java中的多线程你只要看这一篇就够了
- spring 学习中 遇到的那些坑
- (Java实现) HDOJ 2068 RPG的错排 错排及组合
- Eclipse上GIT插件EGIT使用手册
- JAVA打印输出整数
- Spring MVC Controller单例陷阱
- java并发编程实践(2)线程安全性
- Java--内部类
- Java-线程池
- 完美解决java.lang.IllegalArgumentException: pointerIndex out of range
- RxJava操作符repeatWhen()和retryWhen()
- spring+resteasy(JSF)搭建接口
- 关于Spring的xsd文件版本号的问题
- Spring MVC Ajax请求加载更多
- Java基本类型数组转ArrayList
- Java将时间戳转换成指定格式日期
- Java 里面 final 与 static