[初探爬虫框架: DotnetSpider] 一 采集博客园
2016-05-25 22:08
411 查看
今天ModestMT.Zou发布了DotnetSpider爬虫第二章节,内容简单明了,基本看懂了,于是想自己试试看,直接就拿博客园开刀了。
这里有最基本的使用方式,本文章不介绍
这里用的是VS2015,因为此项目有些C#6.0语法糖
先引用两个Dll类库
Java2Dotnet.Spider.Core.dll
Newtonsoft.Json.dll
如果你编译DotnetSpider成功的话,可以在output目录中找到
关于XPath,可以到这里学习http://www.w3school.com.cn/xpath/,我也是下午刚看了一遍,因为有XML/HTML基础,基本没压力
关于XPath表达式如何写,我觉得用谷歌审核元素就足够了,可以复制XPath。也有一款谷歌XPath插件,因我翻不了墙,就没安装。
如下图://*[@id="post_list"]/div[20]/div[2]/h3/a,然后再按需改改

接下来在Program的Main方法中写运行代码
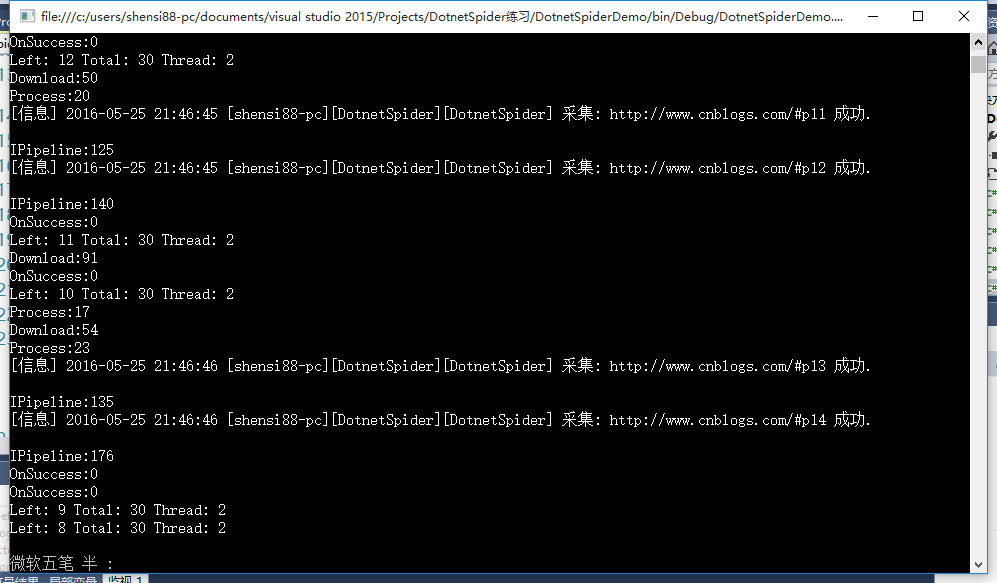

这样每一页信息就被保存起来了,但到这里还没完,一般情况不仅仅是采集列表页,也会采集详细页,于是我又添加了两个类,暂时我是这样实现的,但感觉有点慢
添加页面详细数据处理器
再添加页面详细数据保存
修改ListPipeline这个类RequestDetail方法,我的想法是列表数据保存一次就请求一次详细页,然后再保存详细页
所有详细页都保存在details这个目录下
其它代码保持不变,运行程序,现在已经能保存详细页内容了
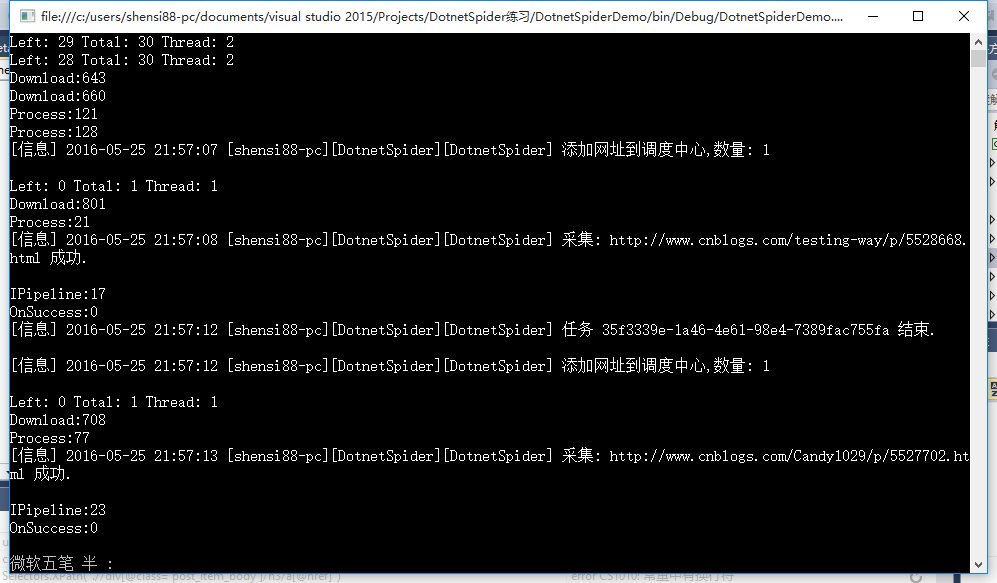
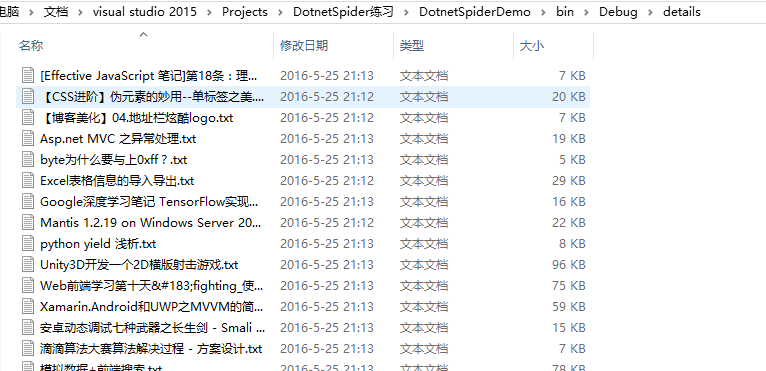
最后,程序运行下来没什么大问题,但就是在采集详细页时比较慢,我的想法是把所有详细页一起加到调度中心,然后开多个线程去运行,这个有待学习。
今天把上面的问题解决了,修改ListPipeline类,这样就可一次把所有详细页都加到调度中心,然后开多个线程去请求。
PageDetailProcessor类也更改了,加入标题、url获取
Demo下载
这里有最基本的使用方式,本文章不介绍
[开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [二] 最基本,最自由的使用方式
这里我已经从https://github.com/zlzforever/DotnetSpider上下载代码并编译通过这里用的是VS2015,因为此项目有些C#6.0语法糖
首先,用VS2015新建一个控件台程序,命名为DotnetSpiderDemo
新建一个数据对象
public class Cnblog
{
public string Title { get; set; }
public string Url { get; set; }
public string Author { get; set; }
public string Conter { get; set; }
}先引用两个Dll类库
Java2Dotnet.Spider.Core.dll
Newtonsoft.Json.dll
如果你编译DotnetSpider成功的话,可以在output目录中找到
现在来写数据处理器,实现 IPageProcessor 这个接口
/// <summary>
/// 页面列表处理器
/// </summary>
public class PageListProcessor : IPageProcessor
{
public Site Site{get; set; }
public void Process(Page page)
{
var totalCnblogElements = page.Selectable.SelectList(Selectors.XPath("//div[@class='post_item']")).Nodes();
List<Cnblog> results = new List<Cnblog>();
foreach (var cnblogElement in totalCnblogElements)
{
var cnblog = new Cnblog();
cnblog.Title = cnblogElement.Select(Selectors.XPath(".//div[@class='post_item_body']/h3/a")).GetValue();
cnblog.Url = cnblogElement.Select(Selectors.XPath(".//div[@class='post_item_body']/h3")).Links().GetValue();
cnblog.Author = cnblogElement.Select(Selectors.XPath(".//div[@class='post_item_foot']/a[1]")).GetValue();
results.Add(cnblog);
}
page.AddResultItem("Result", results);
}
}关于XPath,可以到这里学习http://www.w3school.com.cn/xpath/,我也是下午刚看了一遍,因为有XML/HTML基础,基本没压力
关于XPath表达式如何写,我觉得用谷歌审核元素就足够了,可以复制XPath。也有一款谷歌XPath插件,因我翻不了墙,就没安装。
如下图://*[@id="post_list"]/div[20]/div[2]/h3/a,然后再按需改改
数据存取
需要实现 IPipeline这个接口,然后你想保存到文件或数据库就自己选择public class ListPipeline : IPipeline
{
private string _path;
public ListPipeline(string path)
{
if (string.IsNullOrEmpty(path))
{
throw new Exception("文件名不能为空!");
}
_path = path;
if (!File.Exists(_path))
{
File.Create(_path);
}
}
public void Dispose()
{
}
public void Process(ResultItems resultItems, ISpider spider)
{
lock (this)
{
foreach (Cnblog entry in resultItems.Results["Result"])
{
File.AppendAllText(_path, JsonConvert.SerializeObject(entry));
}
}
}接下来在Program的Main方法中写运行代码
class Program
{
static void Main(string[] args)
{
var site = new Site() { EncodingName = "UTF-8" };
for (int i = 1; i <= 30; i++)//30页
{
site.AddStartUrl(
$"http://www.cnblogs.com/p{i}");//已更正去掉#号,本来是"http://www.cnblogs.com/#p{i}",这样发现请求的是http://www.cnblogs.com
}
Spider spider = Spider.Create(site, new PageListProcessor(), new QueueDuplicateRemovedScheduler()).AddPipeline(new ListPipeline("test.json")).SetThreadNum(2);//两个线程
spider.Run();
Console.Read();
}
}这样每一页信息就被保存起来了,但到这里还没完,一般情况不仅仅是采集列表页,也会采集详细页,于是我又添加了两个类,暂时我是这样实现的,但感觉有点慢
添加页面详细数据处理器
/// <summary>
/// 页面详细处理器
/// </summary>
public class PageDetailProcessor : IPageProcessor
{
private Cnblog cnblog;
public PageDetailProcessor(Cnblog _cnblog)
{
cnblog = _cnblog;
}
public Site Site { get; set; }
public void Process(Page page)
{
cnblog.Conter=page.Selectable.Select(Selectors.XPath("//*[@id='cnblogs_post_body']")).GetValue();
page.AddResultItem("detail",cnblog);
}
}再添加页面详细数据保存
public class DetailPipeline : IPipeline
{
private string path;
public DetailPipeline(string _path)
{
if (string.IsNullOrEmpty(_path))
{
throw new Exception("路径不能为空!");
}
path = _path;
if (!Directory.Exists(_path))
{
Directory.CreateDirectory(_path);
}
}
public void Dispose()
{
}
public void Process(ResultItems resultItems, ISpider spider)
{
Cnblog cnblog=resultItems.Results["detail"];
FileStream fs=File.Create(path + "\\" + cnblog.Title + ".txt");
byte[] bytes=UTF8Encoding.UTF8.GetBytes("Url:"+cnblog.Url+Environment.NewLine+cnblog.Conter);
fs.Write(bytes,0,bytes.Length);
fs.Flush();
fs.Close();
}
}修改ListPipeline这个类RequestDetail方法,我的想法是列表数据保存一次就请求一次详细页,然后再保存详细页
所有详细页都保存在details这个目录下
public class ListPipeline : IPipeline
{
private string _path;
public ListPipeline(string path)
{
if (string.IsNullOrEmpty(path))
{
throw new Exception("文件名不能为空!");
}
_path = path;
if (!File.Exists(_path))
{
File.Create(_path);
}
}
public void Dispose()
{
}
public void Process(ResultItems resultItems, ISpider spider)
{
lock (this)
{
foreach (Cnblog entry in resultItems.Results["Result"])
{
File.AppendAllText(_path, JsonConvert.SerializeObject(entry));
RequestDetail(entry);
}
}
}
/// <summary>
/// 请求详细页
/// </summary>
/// <param name="entry"></param>
private static void RequestDetail(Cnblog entry)
{
ISpider spider;
var site = new Site() {EncodingName = "UTF-8"};
site.AddStartUrl(entry.Url);
spider =
Spider.Create(site, new PageDetailProcessor(entry), new QueueDuplicateRemovedScheduler())
.AddPipeline(new DetailPipeline("details"))
.SetThreadNum(1);
spider.Run();
}
}其它代码保持不变,运行程序,现在已经能保存详细页内容了
最后,程序运行下来没什么大问题,但就是在采集详细页时比较慢,我的想法是把所有详细页一起加到调度中心,然后开多个线程去运行,这个有待学习。
今天把上面的问题解决了,修改ListPipeline类,这样就可一次把所有详细页都加到调度中心,然后开多个线程去请求。
public void Process(ResultItems resultItems, ISpider spider)
{
lock (this)
{
var site = new Site() { EncodingName = "UTF-8" };
foreach (Cnblog entry in resultItems.Results["Result"])
{
File.AppendAllText(_path, JsonConvert.SerializeObject(entry));
site.AddStartUrl(entry.Url);
}
RequestDetail(site);
}
}
/// <summary>
/// 请求详细页
/// </summary>
/// <param name="site"></param>
private static void RequestDetail(Site site)
{
ISpider spider =
Spider.Create(site, new PageDetailProcessor(), new QueueDuplicateRemovedScheduler())
.AddPipeline(new DetailPipeline("details"))
.SetThreadNum(3);
spider.Run();
}PageDetailProcessor类也更改了,加入标题、url获取
public void Process(Page page)
{
Cnblog cnblog=new Cnblog();
cnblog.Title = page.Selectable.Select(Selectors.XPath("//a[@id='cb_post_title_url']")).GetValue();
cnblog.Conter=page.Selectable.Select(Selectors.XPath("//*[@id='cnblogs_post_body']")).GetValue();
cnblog.Url = page.Url;
page.AddResultItem("detail",cnblog);
}Demo下载

相关文章推荐
- 随机获取Mysql数据表的一条或多条记录
- C#Winform实现高效率导入和导出Excel文件
- linux mysql5.5安装与配置
- Win10系统总是提示"在商店中查找应用"的关闭方法
- SharedPreferences使用介绍
- 深入总结 Spring MVC
- hdu 4751 Divide Groups bfs/dfs 连通性的问题 种子染色法
- 格子刷油漆(DP)
- 在idea中运行tinysample的websample为何会报404错
- 新的开始 春光明媚
- Tomcat启动:A fatal error has been detected by the Java Runtime Environment(JVM Crash分析及相关资料)
- Java 之类的加载顺序
- Eclipse中的Maven插件运行项目中的Goals设置
- 利用 ACE 来实现 UDP 通讯
- how to improve working efficency
- 设计模式的学习——工厂模式
- JAVA泛型 一
- AsyncTask出现RejectExcetionExcetion原因
- Java Object
- 配置java 和tomacat环境过程