概率图模型:贝叶斯网络与朴素贝叶斯网络
2016-05-23 10:54
316 查看
http://blog.csdn.net/pipisorry/article/details/51471222

虽然未知,但最起码是一个确定的值。比如如果问那时的人们一个问题:“有一个袋子,里面装着若干个白球和黑球,请问从袋子中取得白球的概率
是多少?”他们会立马告诉你,取出白球的概率
就是1/2,要么取到白球,要么取不到白球,即θ只能有一个值,而且不论你取了多少次,取得白球的概率θ始终都是1/2,即不随观察结果X
的变化而变化。这种频率派的观点长期统治着人们的观念,直到后来一个名叫Thomas Bayes的人物出现。频率派把需要推断的参数θ看做是固定的未知常数,即概率
虽然是未知的,但最起码是确定的一个值,同时,样本X 是随机的,所以频率派重点研究样本空间,大部分的概率计算都是针对样本X 的分布;最大似然估计(MLE)和最大后验估计(MAP)都是把待估计的参数看作一个拥有固定值的变量,只是取值未知。通常估计的方法都是找使得相应的函数最大时的参数;由于MAP相比于MLE会考虑先验分布的影响,所以MAP也会有超参数,它的超参数代表的是一种信念(belief),会影响推断(inference)的结果。比如说抛硬币,如果我先假设是公平的硬币,这也是一种归纳偏置(bias),那么最终推断的结果会受我们预先假设的影响。 回到上面的例子:“有一个袋子,里面装着若干个白球和黑球,请问从袋子中取得白球的概率θ是多少?”贝叶斯认为取得白球的概率
回到上面的例子:“有一个袋子,里面装着若干个白球和黑球,请问从袋子中取得白球的概率θ是多少?”贝叶斯认为取得白球的概率
是个不确定的值,因为其中含有机遇的成分。比如,一个朋友创业,你明明知道创业的结果就两种,即要么成功要么失败,但你依然会忍不住去估计他创业成功的几率有多大?你如果对他为人比较了解,而且有方法、思路清晰、有毅力、且能团结周围的人,你会不由自主的估计他创业成功的几率可能在80%以上。这种不同于最开始的“非黑即白、非0即1”的思考方式,便是贝叶斯式的思考方式。贝叶斯派既然把
看做是一个随机变量,所以要计算
的分布,便得事先知道
的无条件分布,即在有样本之前(或观察到X之前),
有着怎样的分布呢?比如往台球桌上扔一个球,这个球落会落在何处呢?如果是不偏不倚的把球抛出去,那么此球落在台球桌上的任一位置都有着相同的机会,即球落在台球桌上某一位置的概率
服从均匀分布。这种在实验之前定下的属于基本前提性质的分布称为先验分布,或
的无条件分布。贝叶斯派认为待估计的参数
是随机变量,服从一定的分布,而样本X 是固定的,由于样本是固定的,所以他们重点研究的是参数
的分布。

+ 样本信息


后验分布
 上述思考模式意味着,新观察到的样本信息将修正人们以前对事物的认知。换言之,在得到新的样本信息之前,人们对
上述思考模式意味着,新观察到的样本信息将修正人们以前对事物的认知。换言之,在得到新的样本信息之前,人们对

的认知是先验分布
,在得到新的样本信息
后,人们对
的认知为
。其中,先验信息一般来源于经验跟历史资料。比如林丹跟某选手对决,解说一般会根据林丹历次比赛的成绩对此次比赛的胜负做个大致的判断。再比如,某工厂每天都要对产品进行质检,以评估产品的不合格率θ,经过一段时间后便会积累大量的历史资料,这些历史资料便是先验知识,有了这些先验知识,便在决定对一个产品是否需要每天质检时便有了依据,如果以往的历史资料显示,某产品的不合格率只有0.01%,便可视为信得过产品或免检产品,只每月抽检一两次,从而省去大量的人力物力。而后验分布
一般也认为是在给定样本
的情况下
的条件分布,而使
达到最大的值

称为最大后验估计。
 联合概率表示两个事件共同发生的概率。A与B的联合概率表示为
联合概率表示两个事件共同发生的概率。A与B的联合概率表示为

或者

。边缘概率(又称先验概率)是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中那些不需要的事件通过合并成它们的全概率,而消去它们(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率),这称为边缘化(marginalization),比如A的边缘概率表示为P(A),B的边缘概率表示为P(B)。贝叶斯定理贝叶斯定理是关于随机事件A和B的条件概率和边缘概率的一则定理。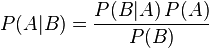 在参数估计中可以写成下面这样:
在参数估计中可以写成下面这样:
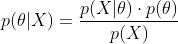
这个公式也称为逆概率公式,可以将后验概率转化为基于似然函数和先验概率的计算表达式,即
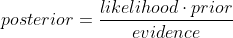
在贝叶斯定理中,每个名词都有约定俗成的名称:P(A)是A的先验概率或边缘概率。之所以称为"先验"是因为它不考虑任何B方面的因素。P(A|B)是已知B发生后A的条件概率(在B发生的情况下A发生的可能性),也由于得自B的取值而被称作A的后验概率。P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。P(B)是B的先验概率或边缘概率,也作标准化常量(normalized constant).按这些术语,Bayes定理可表述为:后验概率 = (相似度*先验概率)/标准化常量,也就是说,后验概率与先验概率和相似度的乘积成正比。
另外,比例P(B|A)/P(B)也有时被称作标准相似度(standardised likelihood),Bayes定理可表述为:后验概率 = 标准相似度*先验概率
然后看到5个男生后重新估计男女比例,其实就是求P(比例7:1|5个男生)= ?,P(比例1:7|5个男生) = ?
用贝叶斯公式

,可得:P(比例7:1|5个男生) = P(比例7:1)*P(5个男生|比例7:1) / P(5个男生),P(5个男生)是5个男生的先验概率,与学校无关,所以是个常数;类似的,P(比例1:7|5个男生) = P((比例1:7)*P(5个男生|比例1:7)/P(5个男生)。
最后将上述两个等式比一下,可得:P(比例7:1|5个男生)/P(比例1:7|5个男生) = {P((比例7:1)*P(5个男生|比例7:1)} / { P(比例1:7)*P(5个男生|比例1:7)}。 Note: n个变量的联合分布,每个x对应两个值,共n个x,且所有概率总和为1,则联合分布需要2^n-1个参数。
Note: n个变量的联合分布,每个x对应两个值,共n个x,且所有概率总和为1,则联合分布需要2^n-1个参数。

,它们可以是可观察到的变量,或隐变量、未知参数等。认为有因果关系(或非条件独立)的变量或命题则用箭头来连接。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(children)”,两节点就会产生一个条件概率值。总而言之,连接两个节点的箭头代表此两个随机变量是具有因果关系,或非条件独立。例如,假设节点E直接影响到节点H,即E→H,则用从E指向H的箭头建立结点E到结点H的有向弧(E,H),权值(即连接强度)用条件概率P(H|E)来表示,如下图所示: 简言之,把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。其主要用来描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)。
简言之,把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。其主要用来描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)。 则称X为相对于一有向无环图G 的贝叶斯网络,其中,
则称X为相对于一有向无环图G 的贝叶斯网络,其中,

表示节点i之“因”,或称pa(i)是i的parents(父母)。
此外,对于任意的随机变量,其联合概率可由各自的局部条件概率分布相乘而得出:
 因为a导致b,a和b导致c,所以有
因为a导致b,a和b导致c,所以有
 1. x1,x2,…x7的联合分布为
1. x1,x2,…x7的联合分布为 2. x1和x2独立(对应head-to-head);3. x6和x7在x4给定的条件下独立(对应tail-to-tail)。
2. x1和x2独立(对应head-to-head);3. x6和x7在x4给定的条件下独立(对应tail-to-tail)。 有P(a,b,c) = P(a)*P(b)*P(c|a,b),积分c后可得:
有P(a,b,c) = P(a)*P(b)*P(c|a,b),积分c后可得: 即在c未知的条件下,a、b被阻断(blocked),是独立的,称之为head-to-head( 因 为 它 连 接 了 两 个 箭 头 的 头)条件独立。
即在c未知的条件下,a、b被阻断(blocked),是独立的,称之为head-to-head( 因 为 它 连 接 了 两 个 箭 头 的 头)条件独立。
 考虑c未知,跟c已知这两种情况:在c未知的时候,有:P(a,b,c)=P(c)*P(a|c)*P(b|c),此时,没法得出P(a,b) = P(a)P(b),即c未知时,a、b不独立。在c已知的时候,有:P(a,b|c)=P(a,b,c)/P(c),然后将P(a,b,c)=P(c)*P(a|c)*P(b|c)带入式子中,得到:P(a,b|c)=P(a,b,c)/P(c) = P(c)*P(a|c)*P(b|c) / P(c) = P(a|c)*P(b|c),即c已知时,a、b独立。所以,在c给定的条件下,a,b被阻断(blocked),是独立的,称之为tail-to-tail条件独立。Any node is d-seperated from its non-descendants given its parents.父节点已知后,其它节点就不能通过父节点影响该节点的值了。
考虑c未知,跟c已知这两种情况:在c未知的时候,有:P(a,b,c)=P(c)*P(a|c)*P(b|c),此时,没法得出P(a,b) = P(a)P(b),即c未知时,a、b不独立。在c已知的时候,有:P(a,b|c)=P(a,b,c)/P(c),然后将P(a,b,c)=P(c)*P(a|c)*P(b|c)带入式子中,得到:P(a,b|c)=P(a,b,c)/P(c) = P(c)*P(a|c)*P(b|c) / P(c) = P(a|c)*P(b|c),即c已知时,a、b独立。所以,在c给定的条件下,a,b被阻断(blocked),是独立的,称之为tail-to-tail条件独立。Any node is d-seperated from its non-descendants given its parents.父节点已知后,其它节点就不能通过父节点影响该节点的值了。
 还是分c未知跟c已知这两种情况:c未知时,有:P(a,b,c)=P(a)*P(c|a)*P(b|c),但无法推出P(a,b) = P(a)P(b),即c未知时,a、b不独立。c已知时,有:P(a,b|c)=P(a,b,c)/P(c),且根据P(a,c) = P(a)*P(c|a) = P(c)*P(a|c),可化简得到:
还是分c未知跟c已知这两种情况:c未知时,有:P(a,b,c)=P(a)*P(c|a)*P(b|c),但无法推出P(a,b) = P(a)P(b),即c未知时,a、b不独立。c已知时,有:P(a,b|c)=P(a,b,c)/P(c),且根据P(a,c) = P(a)*P(c|a) = P(c)*P(a|c),可化简得到: 所以,在c给定的条件下,a,b被阻断(blocked),是独立的,称之为head-to-tail条件独立。head-to-tail其实就是一个链式网络:
所以,在c给定的条件下,a,b被阻断(blocked),是独立的,称之为head-to-tail条件独立。head-to-tail其实就是一个链式网络:

 head-to-tail,给定 T 时,A 和 X 独立;tail-to-tail,给定S时,L和B独立;head-to-head,未给定D时,L和B独立。
head-to-tail,给定 T 时,A 和 X 独立;tail-to-tail,给定S时,L和B独立;head-to-head,未给定D时,L和B独立。

。我们考虑从
A 中任意结点到 B 中任意结点的所有可能的路径。我们说这样的路径被“阻隔”,如果它包含一个结点满足下面两个性质中的任何一个:• 路径上的箭头以头到尾或者尾到尾的方式交汇于这个结点,且这个结点在集合 C 中,也就是A和B的“head-to-tail型”和“tail-to-tail型”路径都通过C。• 箭头以头到头的方式交汇于这个结点,且这个结点和它的所有后继都不在集合 C 中,也就是A和B的“head-to-head型”路径不通过C以及C的子孙。如果所有的路径都被“阻隔”(上面两个条件均满足),那么我们说 C 把 A 从 B 中 d -划分开,且图中所有变量上的联合概率分布将会满足
。Note: 这里C是已知的,A和B的“head-to-tail型”和“tail-to-tail型”路径都通过C则AB条件独立;A和B的“head-to-head型”路径不通过C以及C的子孙,否则根据1在C已知的情况下AB就不独立了。皮皮blog








 Note:对应上面的学生示例,就是说,当类变量C(示例中就是智商I)确定时,类的feature(示例中的Grade和SAT)之间就是独立的(其实就是贝叶斯网的tail-to-tail结构形式)。
Note:对应上面的学生示例,就是说,当类变量C(示例中就是智商I)确定时,类的feature(示例中的Grade和SAT)之间就是独立的(其实就是贝叶斯网的tail-to-tail结构形式)。
 朴素贝叶斯模型的贝叶斯网络:
朴素贝叶斯模型的贝叶斯网络:

 也就是说朴素贝叶斯分类器主要是训练参数p(c){每个独立的p(ci)}和p(x|c){每个独立的p(xi|ci)=num(xi=i, ci=i)/num(ci=i)}(这些参数可以通过训练数据是直接通过频率计算出来的(MLE方法)),通过取最大的p(c|new_x)来预测new_x的类别。
也就是说朴素贝叶斯分类器主要是训练参数p(c){每个独立的p(ci)}和p(x|c){每个独立的p(xi|ci)=num(xi=i, ci=i)/num(ci=i)}(这些参数可以通过训练数据是直接通过频率计算出来的(MLE方法)),通过取最大的p(c|new_x)来预测new_x的类别。

朴素贝叶斯方法不需要进行结构学习,建立网络结构非常简单,实验结果和实践证明,它的分类效果比较好。但在实际的应用领域中,朴素贝叶斯网络分类器具有较强的限定条件即各个属性相互独立的假设很难成立。我们应该广义地理解这种独立性,即属性变量之间的条件独立性是指:属性变量之间的依赖相对于属性变量与类变量之间的依赖是可以忽略的,这就是为什么朴素贝叶斯网络分类器应用的最优范围比想象的要大得多的一个主要原因。朴素贝叶斯分类器以简单的结构和良好的性能受到人们的关注,它是最优秀的分类器之一。在理论上它在满足其限定条件下是最优的,但它有较强的限定条件,可以尝试减弱它的限定条件以扩大最优范围,产生更好的分类器。朴素贝叫斯分类器可以进行扩展为广义朴素贝叶斯分类器。 from:
from:
/article/11852808.htmlref: 《数理统计学简史》《统计决策论及贝叶斯分析 James O.Berger著》贝叶斯网络 - 维基百科贝叶斯网络简介贝叶斯网络简介算法杂货铺——分类算法之贝叶斯网络(Bayesian networks)概率图模型 原理与技术[(美)科勒,(以)弗里德曼著]*机器学习之用Python从零实现贝叶斯分类器
贝叶斯与频率派思想
频率派思想
长久以来,人们对一件事情发生或不发生,只有固定的0和1,即要么发生,要么不发生,从来不会去考虑某件事情发生的概率有多大,不发生的概率又是多大。而且事情发生或不发生的概率虽然未知,但最起码是一个确定的值。比如如果问那时的人们一个问题:“有一个袋子,里面装着若干个白球和黑球,请问从袋子中取得白球的概率
是多少?”他们会立马告诉你,取出白球的概率
就是1/2,要么取到白球,要么取不到白球,即θ只能有一个值,而且不论你取了多少次,取得白球的概率θ始终都是1/2,即不随观察结果X
的变化而变化。这种频率派的观点长期统治着人们的观念,直到后来一个名叫Thomas Bayes的人物出现。频率派把需要推断的参数θ看做是固定的未知常数,即概率
虽然是未知的,但最起码是确定的一个值,同时,样本X 是随机的,所以频率派重点研究样本空间,大部分的概率计算都是针对样本X 的分布;最大似然估计(MLE)和最大后验估计(MAP)都是把待估计的参数看作一个拥有固定值的变量,只是取值未知。通常估计的方法都是找使得相应的函数最大时的参数;由于MAP相比于MLE会考虑先验分布的影响,所以MAP也会有超参数,它的超参数代表的是一种信念(belief),会影响推断(inference)的结果。比如说抛硬币,如果我先假设是公平的硬币,这也是一种归纳偏置(bias),那么最终推断的结果会受我们预先假设的影响。
贝叶斯思想
回到上面的例子:“有一个袋子,里面装着若干个白球和黑球,请问从袋子中取得白球的概率θ是多少?”贝叶斯认为取得白球的概率是个不确定的值,因为其中含有机遇的成分。比如,一个朋友创业,你明明知道创业的结果就两种,即要么成功要么失败,但你依然会忍不住去估计他创业成功的几率有多大?你如果对他为人比较了解,而且有方法、思路清晰、有毅力、且能团结周围的人,你会不由自主的估计他创业成功的几率可能在80%以上。这种不同于最开始的“非黑即白、非0即1”的思考方式,便是贝叶斯式的思考方式。贝叶斯派既然把
看做是一个随机变量,所以要计算
的分布,便得事先知道
的无条件分布,即在有样本之前(或观察到X之前),
有着怎样的分布呢?比如往台球桌上扔一个球,这个球落会落在何处呢?如果是不偏不倚的把球抛出去,那么此球落在台球桌上的任一位置都有着相同的机会,即球落在台球桌上某一位置的概率
服从均匀分布。这种在实验之前定下的属于基本前提性质的分布称为先验分布,或
的无条件分布。贝叶斯派认为待估计的参数
是随机变量,服从一定的分布,而样本X 是固定的,由于样本是固定的,所以他们重点研究的是参数
的分布。
贝叶斯及贝叶斯派思考问题的固定模式
先验分布+ 样本信息
后验分布
上述思考模式意味着,新观察到的样本信息将修正人们以前对事物的认知。换言之,在得到新的样本信息之前,人们对的认知是先验分布
,在得到新的样本信息
后,人们对
的认知为
。其中,先验信息一般来源于经验跟历史资料。比如林丹跟某选手对决,解说一般会根据林丹历次比赛的成绩对此次比赛的胜负做个大致的判断。再比如,某工厂每天都要对产品进行质检,以评估产品的不合格率θ,经过一段时间后便会积累大量的历史资料,这些历史资料便是先验知识,有了这些先验知识,便在决定对一个产品是否需要每天质检时便有了依据,如果以往的历史资料显示,某产品的不合格率只有0.01%,便可视为信得过产品或免检产品,只每月抽检一两次,从而省去大量的人力物力。而后验分布
一般也认为是在给定样本
的情况下
的条件分布,而使
达到最大的值
称为最大后验估计。
贝叶斯定理
条件概率条件概率(又称后验概率)就是事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在B条件下A的概率”。联合概率表示两个事件共同发生的概率。A与B的联合概率表示为或者
。边缘概率(又称先验概率)是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中那些不需要的事件通过合并成它们的全概率,而消去它们(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率),这称为边缘化(marginalization),比如A的边缘概率表示为P(A),B的边缘概率表示为P(B)。贝叶斯定理贝叶斯定理是关于随机事件A和B的条件概率和边缘概率的一则定理。
在参数估计中可以写成下面这样:这个公式也称为逆概率公式,可以将后验概率转化为基于似然函数和先验概率的计算表达式,即
在贝叶斯定理中,每个名词都有约定俗成的名称:P(A)是A的先验概率或边缘概率。之所以称为"先验"是因为它不考虑任何B方面的因素。P(A|B)是已知B发生后A的条件概率(在B发生的情况下A发生的可能性),也由于得自B的取值而被称作A的后验概率。P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。P(B)是B的先验概率或边缘概率,也作标准化常量(normalized constant).按这些术语,Bayes定理可表述为:后验概率 = (相似度*先验概率)/标准化常量,也就是说,后验概率与先验概率和相似度的乘积成正比。
另外,比例P(B|A)/P(B)也有时被称作标准相似度(standardised likelihood),Bayes定理可表述为:后验概率 = 标准相似度*先验概率
贝叶斯估计的例子
假设中国的大学只有两种:理工科和文科,这两种学校数量的比例是1:1,其中,理工科男女比例7:1,文科男女比例1:7。某天你被外星人随机扔到一个校园,问你该学校可能的男女比例是多少?然后,你实际到该校园里逛了一圈,看到的5个人全是男的,这时候再次问你这个校园的男女比例是多少?因为刚开始时,有先验知识,所以该学校的男女比例要么是7:1,要么是1:7,即P(比例为7:1) = 1/2,P(比例为1:7) = 1/2。然后看到5个男生后重新估计男女比例,其实就是求P(比例7:1|5个男生)= ?,P(比例1:7|5个男生) = ?
用贝叶斯公式
,可得:P(比例7:1|5个男生) = P(比例7:1)*P(5个男生|比例7:1) / P(5个男生),P(5个男生)是5个男生的先验概率,与学校无关,所以是个常数;类似的,P(比例1:7|5个男生) = P((比例1:7)*P(5个男生|比例1:7)/P(5个男生)。
最后将上述两个等式比一下,可得:P(比例7:1|5个男生)/P(比例1:7|5个男生) = {P((比例7:1)*P(5个男生|比例7:1)} / { P(比例1:7)*P(5个男生|比例1:7)}。
频率派与贝叶斯派的区别
频率派把需要推断的参数θ看做是固定的未知常数,即概率虽然是未知的,但最起码是确定的一个值,同时,样本X 是随机的,所以频率派重点研究样本空间,大部分的概率计算都是针对样本X 的分布;贝叶斯派的观点则截然相反,他们认为参数是随机变量,而样本X 是固定的,由于样本是固定的,所以他们重点研究的是参数的分布。两者的本质区别
根据贝叶斯法则:posterior=likelihood⋅priorevidence即
p(ϑ|X)=p(X|ϑ)⋅p(ϑ)p(X)在MLE和MAP中,由于是要求函数最大值时的参数,所以都不会考虑evidence。但在贝叶斯估计中,不再直接取极值,所以还会考虑evidence,下面的这个积分也是通常贝叶斯估计中最难处理的部分:
p(X)=∫ϑ∈Θp(X|ϑ)p(ϑ)dϑevidence相当于对所有的似然概率积分或求和(离散时),所以也称作边界似然。
估计未知参数所采用的思想不同的例子
我去一朋友家:按照频率派的思想,我估计他在家的概率是1/2,不在家的概率也是1/2,是个定值。按照贝叶斯派的思想,他在家不在家的概率不再认为是个定值1/2,而是随机变量。比如按照我们的经验(比如当天周末),猜测他在家的概率是0.6,但这个0.6不是说就是完全确定的,也有可能是0.7。如此,贝叶斯派没法确切给出参数的确定值(0.3,0.4,0.6,0.7,0.8,0.9都有可能),但至少明白哪些取值(0.6,0.7,0.8,0.9)更有可能,哪些取值(0.3,0.4) 不太可能。进一步,贝叶斯估计中,参数的多个估计值服从一定的先验分布,而后根据实践获得的数据(例如周末不断跑他家),不断修正之前的参数估计,从先验分布慢慢过渡到后验分布。各种参数估计方法可以参考Heinrich论文的第二部分。[各种参数估计方法的论述:Gregor Heinrich.Parameter estimation for text analysis*]皮皮blog贝叶斯网络
why贝叶斯网络
Note: n个变量的联合分布,每个x对应两个值,共n个x,且所有概率总和为1,则联合分布需要2^n-1个参数。贝叶斯网络
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型(directed acyclic graphical model),是一种概率图模型,于1985年由Judea Pearl首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(DAG)。贝叶斯网络的有向无环图中的节点表示随机变量,它们可以是可观察到的变量,或隐变量、未知参数等。认为有因果关系(或非条件独立)的变量或命题则用箭头来连接。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(children)”,两节点就会产生一个条件概率值。总而言之,连接两个节点的箭头代表此两个随机变量是具有因果关系,或非条件独立。例如,假设节点E直接影响到节点H,即E→H,则用从E指向H的箭头建立结点E到结点H的有向弧(E,H),权值(即连接强度)用条件概率P(H|E)来表示,如下图所示:
简言之,把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。其主要用来描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)。联合概率的表示
令G = (I,E)表示一个有向无环图(DAG),其中I代表图形中所有的节点的集合,而E代表有向连接线段的集合,且令X = (Xi)i ∈ I为其有向无环图中的某一节点i所代表的随机变量,若节点X的联合概率可以表示成:则称X为相对于一有向无环图G 的贝叶斯网络,其中,表示节点i之“因”,或称pa(i)是i的parents(父母)。
此外,对于任意的随机变量,其联合概率可由各自的局部条件概率分布相乘而得出:
简单贝叶斯网络的示例
因为a导致b,a和b导致c,所以有贝叶斯网络的3种结构形式
对于下面的贝叶斯网络:1. x1,x2,…x7的联合分布为2. x1和x2独立(对应head-to-head);3. x6和x7在x4给定的条件下独立(对应tail-to-tail)。D-Separation(D-分离)
D-Separation是一种用来判断变量是否条件独立的图形化方法。换言之,对于一个DAG(有向无环图)E,D-Separation方法可以快速的判断出两个节点之间是否是条件独立的。形式1 head-to-head
有P(a,b,c) = P(a)*P(b)*P(c|a,b),积分c后可得:即在c未知的条件下,a、b被阻断(blocked),是独立的,称之为head-to-head( 因 为 它 连 接 了 两 个 箭 头 的 头)条件独立。形式2 tail-to-tail
考虑c未知,跟c已知这两种情况:在c未知的时候,有:P(a,b,c)=P(c)*P(a|c)*P(b|c),此时,没法得出P(a,b) = P(a)P(b),即c未知时,a、b不独立。在c已知的时候,有:P(a,b|c)=P(a,b,c)/P(c),然后将P(a,b,c)=P(c)*P(a|c)*P(b|c)带入式子中,得到:P(a,b|c)=P(a,b,c)/P(c) = P(c)*P(a|c)*P(b|c) / P(c) = P(a|c)*P(b|c),即c已知时,a、b独立。所以,在c给定的条件下,a,b被阻断(blocked),是独立的,称之为tail-to-tail条件独立。Any node is d-seperated from its non-descendants given its parents.父节点已知后,其它节点就不能通过父节点影响该节点的值了。形式3 head-to-tail
还是分c未知跟c已知这两种情况:c未知时,有:P(a,b,c)=P(a)*P(c|a)*P(b|c),但无法推出P(a,b) = P(a)P(b),即c未知时,a、b不独立。c已知时,有:P(a,b|c)=P(a,b,c)/P(c),且根据P(a,c) = P(a)*P(c|a) = P(c)*P(a|c),可化简得到:所以,在c给定的条件下,a,b被阻断(blocked),是独立的,称之为head-to-tail条件独立。head-to-tail其实就是一个链式网络:马尔科夫链(Markov chain)
根据head-to-tail,在xi给定的条件下,xi+1的分布和x1,x2…xi-1条件独立。意味着xi+1的分布状态只和xi有关,和其他变量条件独立。也就是当前状态只跟上一状态有关,跟之前的状态无关。这种顺次演变的随机过程,就叫做马尔科夫链(Markov chain)。也就是:D-Separation的3种情况的总结
{即贝叶斯网络的3种结构形式}head-to-tail,给定 T 时,A 和 X 独立;tail-to-tail,给定S时,L和B独立;head-to-head,未给定D时,L和B独立。有向图d-划分性质的一般叙述
考虑一个一般的有向图,其中 A, B, C 是任意无交集的结点集合(它们的并集可能比图中结点的完整集合要小)。我们希望弄清楚,一个有向无环图是否暗示了一个特定的条件依赖表述。我们考虑从
A 中任意结点到 B 中任意结点的所有可能的路径。我们说这样的路径被“阻隔”,如果它包含一个结点满足下面两个性质中的任何一个:• 路径上的箭头以头到尾或者尾到尾的方式交汇于这个结点,且这个结点在集合 C 中,也就是A和B的“head-to-tail型”和“tail-to-tail型”路径都通过C。• 箭头以头到头的方式交汇于这个结点,且这个结点和它的所有后继都不在集合 C 中,也就是A和B的“head-to-head型”路径不通过C以及C的子孙。如果所有的路径都被“阻隔”(上面两个条件均满足),那么我们说 C 把 A 从 B 中 d -划分开,且图中所有变量上的联合概率分布将会满足
。Note: 这里C是已知的,A和B的“head-to-tail型”和“tail-to-tail型”路径都通过C则AB条件独立;A和B的“head-to-head型”路径不通过C以及C的子孙,否则根据1在C已知的情况下AB就不独立了。皮皮blog
朴素贝叶斯模型naive Bayes
朴素贝叶斯模型的学生示例
{这个示例很好的阐述了什么是朴素贝叶斯网络模型,后面将讲到其一般化模型和分类的应用实例}问题描述
模型的因子表示
符号表示:I表示智商;S(AT)代表SAT成绩;G(rade)代表某些课程成绩。因子表示的优点
朴素贝叶斯一般模型
朴素贝叶斯模型的一般化定义
Note:对应上面的学生示例,就是说,当类变量C(示例中就是智商I)确定时,类的feature(示例中的Grade和SAT)之间就是独立的(其实就是贝叶斯网的tail-to-tail结构形式)。朴素贝叶斯模型的贝叶斯网络:朴素贝叶斯模型的因子分解及参数
使用朴素贝叶斯模型进行分类
也就是说朴素贝叶斯分类器主要是训练参数p(c){每个独立的p(ci)}和p(x|c){每个独立的p(xi|ci)=num(xi=i, ci=i)/num(ci=i)}(这些参数可以通过训练数据是直接通过频率计算出来的(MLE方法)),通过取最大的p(c|new_x)来预测new_x的类别。朴素贝叶斯分类算法的优缺点
优点:在数据较少的情况下依然有效,可以处理多类别问题缺点:对输入数据的准备方式敏感适用数据类型:标称型数据朴素贝叶斯方法不需要进行结构学习,建立网络结构非常简单,实验结果和实践证明,它的分类效果比较好。但在实际的应用领域中,朴素贝叶斯网络分类器具有较强的限定条件即各个属性相互独立的假设很难成立。我们应该广义地理解这种独立性,即属性变量之间的条件独立性是指:属性变量之间的依赖相对于属性变量与类变量之间的依赖是可以忽略的,这就是为什么朴素贝叶斯网络分类器应用的最优范围比想象的要大得多的一个主要原因。朴素贝叶斯分类器以简单的结构和良好的性能受到人们的关注,它是最优秀的分类器之一。在理论上它在满足其限定条件下是最优的,但它有较强的限定条件,可以尝试减弱它的限定条件以扩大最优范围,产生更好的分类器。朴素贝叫斯分类器可以进行扩展为广义朴素贝叶斯分类器。
朴素贝叶斯分类算法的python实现
#!/usr/bin/env python# -*- coding: utf-8 -*-"""__title__ = '朴素贝叶斯算法(亦适用于多类分类)'__author__ = 'pika'__mtime__ = '16-5-23'__email__ = 'pipisorry@126.com'# code is far away from bugs with the god animal protectingI love animals. They taste delicious."""import numpy as npTRAIN_FILE = r'./trainingData.txt'TEST_FILE = r'./testingData.txt'def train_naive_bayes(x, y):'''训练参数:p(c){包含每个独立的p(ci)}和p(x|c){包含每个独立的p(xi|ci)}'''p_c = {} # p(c) = {ci : p(ci)}p_x_cond_c = {} # p(x|c) = {ci : [p(xi|ci)]}for l in np.unique(y):# label l下, x=1 [xi = 1]时的概率array[p(xi=1|c=l)]; 则1-array[p(xi=1|c=l)]就是array[p(xi=0|c=l)]p_x_cond_c[l] = x[y == l].sum(0) / (y == l).sum()p_c[l] = (y == l).sum() / len(y) # p(c=l)的概率print("θC: {}\n".format(p_c))print("θA1=0|C: {}\n".format({a[0]: 1 - a[1][0] for a in p_x_cond_c.items()}))print("θA1=1|C: {}\n".format({a[0]: a[1][0] for a in p_x_cond_c.items()}))return p_c, p_x_cond_cdef predict_naive_bayes(p_c, p_x_cond_c, new_x):'''预测每个新来单个的x的label,返回一个label单值'''# new_x在类别l下的概率arrayp_l = [(l, p_c[l] * (np.multiply.reduce(p_x_cond_c[l] * new_x + (1 - p_x_cond_c[l]) * (1 - new_x)))) for l inp_c.keys()]p_l.sort(key=lambda x: x[1], reverse=True) # new_x在类别l下的概率array按照概率大小排序return p_l[0][0] # 返回概率最大对应的labelif __name__ == '__main__':tdata = np.loadtxt(TRAIN_FILE, dtype=int)x, y = tdata[:, 1:], tdata[:, 0]p_c, p_x_cond_c = train_naive_bayes(x, y)tdata = np.loadtxt(TEST_FILE, dtype=int)x, y = tdata[:, 1:], tdata[:, 0]predict = [predict_naive_bayes(p_c, p_x_cond_c, xi) for xi, yi in zip(x, y)]error = (y != predict).sum() / len(y)print("test error: {}\n".format(error))[机器学习经典算法详解及Python实现---朴素贝叶斯分类及其在文本分类、垃圾邮件检测中的应用]皮皮blog贝叶斯网络的其它应用
from:/article/11852808.htmlref: 《数理统计学简史》《统计决策论及贝叶斯分析 James O.Berger著》贝叶斯网络 - 维基百科贝叶斯网络简介贝叶斯网络简介算法杂货铺——分类算法之贝叶斯网络(Bayesian networks)概率图模型 原理与技术[(美)科勒,(以)弗里德曼著]*机器学习之用Python从零实现贝叶斯分类器

相关文章推荐
- 【转】HTTP 头部解释,HTTP 头部详细分析,最全HTTP头部信息
- kvm基本操作命令详解
- Http协议与TCP协议理解(转载的)
- 判断用户是否有网络, wifi or moblie network
- Volley框架的基本解读(一)
- 有效的利用清晨时间【网络转…
- HTTP Live Streaming直播(iOS直播)技术分析与实现
- TCP、UDP、IP 协议分析
- java 从网络Url中下载文件
- Httpclient请求数据
- 深度学习_caffe (4) 基于mnist实例搭建新的神经网络&在caffe中添加层(续1)
- php----http协议 Cookie个人总结
- HTTPS加密传输数据,加强P2P平台网络安全和信任
- 端口映射的实现方法之花生壳动态域名详解
- 封装了okhttp的网络框架,支持大文件上传下载,上传进度...
- TCP协议详解
- 网络与通信:网络设备(概念)
- IP:网际协议
- HTTPS加密传输数据,加强P2P平台网络安全和信任
- 二进制传输 文本传输