深入Java集合类
2016-05-21 23:18
417 查看
最近想吧Java的底层爬得深一些,一方面是为了在日后使用的时候能够选择最合适的方法,二来也是为了能对Java有更加深厚的理解。在研究的过程中,会将所研究得成果写成博客记录起来,也是对自己的学习进行总结。已经有了提纲。接下来需要做的就是循序渐进了。
首先说下Java的集合:
比较常用的集合我整理成了xmind。如下图:
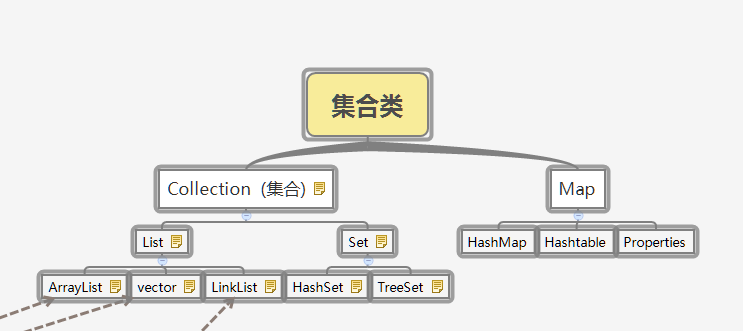
其中Collection 表示一组对象,这些对象也称为 collection 的元素。我们最常使用的Collection对象是List和Set。
接下来探探几个List实现类和Set实现类:
该类不同步(即线程不安全),允许包括null在内的所有元素。
底层实现:
ArrayList带有一个底层的Object[]数组,这个Object[]数组用来保存元素。当数组的大小不够时,会通过调用ensureCapacity()方法来将数组的大小扩大100%,代码如下:
可以看见这个方法通过数组复制的方法进行了数组扩张。
由于ArrayList的底层是一个Object[],所以当通过索引访问元素时,只需简单地通过索引访问内部数组的元素,这是十分高效的,因为除了判断index的值是否合法外,并不需要其他开销,它的时间复杂度是O(1)。get(index)方法的实现如下:
同理,当在集合末尾添加一个对象时,只要不是数组的大小不够了,时间复杂度依旧是O(1),可以说是一步操作,完成奇迹~实现如下:
这一点可以说是ArryList的优势。但是ArryList也有他的短板。比如在指定位置插入一个对象时,同样由于底层是一个Object[],所以插入点之上的所有数组元素都必须向前移动一个位置,然后才能进行赋值(当数组长度不够时,便需要进行两次数组复制操作)。具体的实现方法如下:
插入元素和删除元素总是要进行数组复制(当数组先必须进行扩展时,需要两次复制)。被复制元素的数量和[size-index]成比例,即和插入/删除点到集合中最后索引位置之间的距离成比例。对于插入操作,把元素插入到集合最前面(索引0)时性能最差,插入到集合最后面时(最后一个现有元素之后)时性能最好。随着集合规模的增大,数组复制的开销也迅速增加,因为每次插入操作必须复制的元素数量增加了。可以说,ArryList的指定位置插入和删除对于他的获取操作来说的确是短板。
值得注意的是ArryList是不同步的,除了两个只用于串行化的方法,没有一个ArrayList的方法具有同步执行的能力。而另一个与ArryList十分相似的类:Vector类恰恰相反,Vector的大多数方法具有同步能力,或直接或间接。因此,Vector是线程安全的,但ArrayList不是。这使得ArrayList要比Vector快速。但是对于一些最新的JVM,两个类在速度上的差异可以忽略不计:严格地说,对于这些JVM,这两个类在速度上的差异小于比较这些类性能的测试所显示的时间差异。
b.LinkList
与ArryList和Vector不同,LinkList的底层是一个双向链表。它同样是不同步的。
由于LinkList的底层是一个双向链表,所以当想要get一个指定位置的对象时,就需要通过索引访问元素,你必须查找所有节点,直至找到目标节点,这无疑是比ArrayList低效的。他的实现如下:
但是他较之ArryList优秀的在于他的插入和删除,因为他只用在找到要插入的节点后,新建一个节点便可,不像ArrayList需要进行数组复制,他的插入的时间复杂度是固定的O(i+1),i为要插入的节点位置距离节点末尾的距离。这点在大多数情况下是比ArryList要好的。他的具体实现如下:
当想获得同步的List时,可以使用Collections.synchronizedlist()方法,例如
首先,必须实现HashCode和equals方法
HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null。
hashCode和equal()是HashMap用的, 因为无需排序所以只需要关注定位和唯一性即可. (HashSet就是HashMap的键)
a. hashCode是用来计算hash值的,hash值是用来确定hash表索引的.
b. hash表中的一个索引处存放的是一张链表, 所以还要通过equal方法循环比较链上的每一个对象
才可以真正定位到键值对应的Entry.
c. put时,如果hash表中没定位到,就在链表前加一个Entry,如果定位到了,则更换Entry中的value,并返回旧value
HashSet的重点就在于是哈希实现。无序的。
B.TreeSet
必须实现equals()方法,和Comparator接口
由于TreeMap需要排序,所以需要一个Comparator为键值进行大小比较.当然也是用Comparator定位的. (TreeSet就是TreeMap的键)
a. Comparator可以在创建TreeMap时指定
b. 如果创建时没有确定,那么就会使用key.compareTo()方法,这就要求key必须实现Comparable接口.
c. TreeMap是使用Tree数据结构实现的,所以使用compare接口就可以完成定位了。
TreeMap的重点就在于有序。
其实Map中的HashMap和TreeMap也在这里说清楚了。其实这里面还有很复杂的Hash算法与equals。等日后出一篇专门的博客研究这方面。
首先说下Java的集合:
比较常用的集合我整理成了xmind。如下图:
其中Collection 表示一组对象,这些对象也称为 collection 的元素。我们最常使用的Collection对象是List和Set。
一、List与Set的区别
List与Set都实现和Collection接口。其中List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。和Set不同,List允许有相同的元素。而Set的一个重要标志便是不可重复:因此使用Set的对象必须实现HashCode()方法和equals()方法。由于List是可重复的,所以适合经常追加数据,插入,删除数据。但随即取数效率比较低。而Set是不可重复的,所以适合经常地随即储存,插入,删除。但是在遍历时效率比较低。接下来探探几个List实现类和Set实现类:
1.List
a.ArrayList:该类不同步(即线程不安全),允许包括null在内的所有元素。
底层实现:
ArrayList带有一个底层的Object[]数组,这个Object[]数组用来保存元素。当数组的大小不够时,会通过调用ensureCapacity()方法来将数组的大小扩大100%,代码如下:
public void ensureCapacity(int minCapacity) {
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = Math.max(oldCapacity * 2, minCapacity);
elementData = new Object[newCapacity];
System.arraycopy(oldData, 0, elementData, 0, size);
}
}可以看见这个方法通过数组复制的方法进行了数组扩张。
由于ArrayList的底层是一个Object[],所以当通过索引访问元素时,只需简单地通过索引访问内部数组的元素,这是十分高效的,因为除了判断index的值是否合法外,并不需要其他开销,它的时间复杂度是O(1)。get(index)方法的实现如下:
public Object get(int index)
{
//首先检查index是否合法...此处不显示这部分代码
return elementData[index];
}同理,当在集合末尾添加一个对象时,只要不是数组的大小不够了,时间复杂度依旧是O(1),可以说是一步操作,完成奇迹~实现如下:
public boolean add(Object o)
{
ensureCapacity(size + 1);
elementData[size++] = o;
return true;
}这一点可以说是ArryList的优势。但是ArryList也有他的短板。比如在指定位置插入一个对象时,同样由于底层是一个Object[],所以插入点之上的所有数组元素都必须向前移动一个位置,然后才能进行赋值(当数组长度不够时,便需要进行两次数组复制操作)。具体的实现方法如下:
public void add(int index, Object element) {
//首先检查index是否合法...此处不显示这部分代码
ensureCapacity(size+1);
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}插入元素和删除元素总是要进行数组复制(当数组先必须进行扩展时,需要两次复制)。被复制元素的数量和[size-index]成比例,即和插入/删除点到集合中最后索引位置之间的距离成比例。对于插入操作,把元素插入到集合最前面(索引0)时性能最差,插入到集合最后面时(最后一个现有元素之后)时性能最好。随着集合规模的增大,数组复制的开销也迅速增加,因为每次插入操作必须复制的元素数量增加了。可以说,ArryList的指定位置插入和删除对于他的获取操作来说的确是短板。
值得注意的是ArryList是不同步的,除了两个只用于串行化的方法,没有一个ArrayList的方法具有同步执行的能力。而另一个与ArryList十分相似的类:Vector类恰恰相反,Vector的大多数方法具有同步能力,或直接或间接。因此,Vector是线程安全的,但ArrayList不是。这使得ArrayList要比Vector快速。但是对于一些最新的JVM,两个类在速度上的差异可以忽略不计:严格地说,对于这些JVM,这两个类在速度上的差异小于比较这些类性能的测试所显示的时间差异。
b.LinkList
与ArryList和Vector不同,LinkList的底层是一个双向链表。它同样是不同步的。
由于LinkList的底层是一个双向链表,所以当想要get一个指定位置的对象时,就需要通过索引访问元素,你必须查找所有节点,直至找到目标节点,这无疑是比ArrayList低效的。他的实现如下:
public Object get(intindex) {
//首先检查index是否合法...此处不显示这部分代码
Entry e = header; //开始节点
//向前或者向后查找,具体由哪一个方向距离较近决定
if (index < size/2) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
}但是他较之ArryList优秀的在于他的插入和删除,因为他只用在找到要插入的节点后,新建一个节点便可,不像ArrayList需要进行数组复制,他的插入的时间复杂度是固定的O(i+1),i为要插入的节点位置距离节点末尾的距离。这点在大多数情况下是比ArryList要好的。他的具体实现如下:
public void add(int index, Object element) {
//首先检查index是否合法...此处不显示这部分代码
Entry e = header; //starting node
//向前或者向后查找,具体由哪一个方向距离较
//近决定
if (index < size/2) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
Entry newEntry = new Entry(element, e, e.previous);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
}当想获得同步的List时,可以使用Collections.synchronizedlist()方法,例如
Collections.synchronizedlist(new ArrayList())但是虽然这样可以得到一个同步的集合,但是会降低很多性能。
2.Set
A.HashSet:首先,必须实现HashCode和equals方法
HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null。
hashCode和equal()是HashMap用的, 因为无需排序所以只需要关注定位和唯一性即可. (HashSet就是HashMap的键)
a. hashCode是用来计算hash值的,hash值是用来确定hash表索引的.
b. hash表中的一个索引处存放的是一张链表, 所以还要通过equal方法循环比较链上的每一个对象
才可以真正定位到键值对应的Entry.
c. put时,如果hash表中没定位到,就在链表前加一个Entry,如果定位到了,则更换Entry中的value,并返回旧value
HashSet的重点就在于是哈希实现。无序的。
B.TreeSet
必须实现equals()方法,和Comparator接口
由于TreeMap需要排序,所以需要一个Comparator为键值进行大小比较.当然也是用Comparator定位的. (TreeSet就是TreeMap的键)
a. Comparator可以在创建TreeMap时指定
b. 如果创建时没有确定,那么就会使用key.compareTo()方法,这就要求key必须实现Comparable接口.
c. TreeMap是使用Tree数据结构实现的,所以使用compare接口就可以完成定位了。
TreeMap的重点就在于有序。
其实Map中的HashMap和TreeMap也在这里说清楚了。其实这里面还有很复杂的Hash算法与equals。等日后出一篇专门的博客研究这方面。

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树