Mongodb中数据聚合之基本聚合函数count、distinct、group
2016-05-21 13:26
751 查看
在之前的文章<Mongodb中数据聚合之MapReduce>中,我们提到过Mongodb中进行数据聚合操作的一种方式——MapReduce,但是在大多数日常使用过程中,我们并不需要使用MapReduce来进行操作,不然有点杀鸡用牛刀的感觉

,在这边文章中,我们就简单说说用自带的聚合函数进行数据聚合操作的实现。
Mongodb中自带的基本聚合函数有三种:count、distinct和group。下面我们分别来讲述一下这三个基本聚合函数。
(1)count
作用:简单统计集合中符合某种条件的文档数量。
使用方式:db.collection.count(<query>)或者db.collection.find(<query>).count()
参数说明:其中<query>是用于查询的目标条件。如果出了想限定查出来的最大文档数,或者想统计后跳过指定条数的文档,则还需要借助于limit,skip。
举例:
db.collection.find(<query>).limit();
db.collection.find(<query>).skip();
(2)distinct
作用:用于对集合中的文档针进行去重处理
使用方式:db,collection.distinct(field,query)
参数说明:field是去重字段,可以是单个的字段名,也可以是嵌套的字段名;query是查询条件,可以为空;
举例:
db.collection.distinct("user",{“age":{$gt:28}});//用于查询年龄age大于28岁的不同用户名
除了上面的用法外,还可以使用下面的另外一种方法:
db.runCommand({"distinct":"collectionname","key":"distinctfied","query":<query>})
collectionname:去重统计的集合名,distinctfield:去重字段,,<query>是可选的限制条件;
举例:
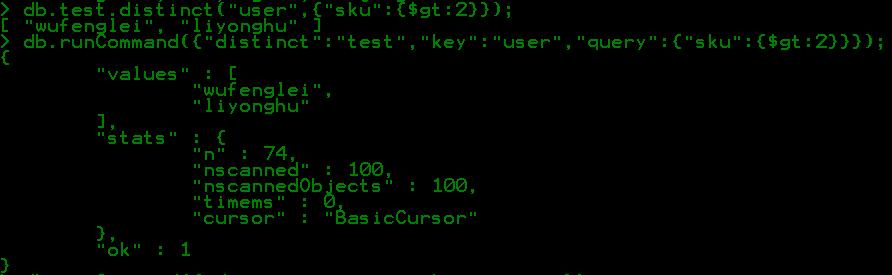
这两种方式的区别:第一种方法是对第二种方法的封装,第一种只返回去重统计后的字段值集合,但第二种方式既返回字段值集合也返回统计时的细节信息。
(3)group
作用:用于提供比count、distinct更丰富的统计需求,可以使用js函数控制统计逻辑
使用方式:db.collection.group(key,reduce,initial[,keyf][,cond][,finalize])
备注说明:在2.2版本之前,group操作最多只能返回10000条分组记录,但是从2.2版本之后到2.4版本,mongodb做了优化,能够支持返回20000条分组记录返回,如果分组记录的条数大于20000条,那么可能你就需要其他方式进行统计了,比如聚合管道或者MapReduce;
上面对Mongodb中自带的三种三种聚合函数进行了简单的描述,并对需要注意的地方进行了简单的说明,如果需要深入使用,可以进入Mongodb官网查看相关细节信息,谢谢。
,在这边文章中,我们就简单说说用自带的聚合函数进行数据聚合操作的实现。
Mongodb中自带的基本聚合函数有三种:count、distinct和group。下面我们分别来讲述一下这三个基本聚合函数。
(1)count
作用:简单统计集合中符合某种条件的文档数量。
使用方式:db.collection.count(<query>)或者db.collection.find(<query>).count()
参数说明:其中<query>是用于查询的目标条件。如果出了想限定查出来的最大文档数,或者想统计后跳过指定条数的文档,则还需要借助于limit,skip。
举例:
db.collection.find(<query>).limit();
db.collection.find(<query>).skip();
(2)distinct
作用:用于对集合中的文档针进行去重处理
使用方式:db,collection.distinct(field,query)
参数说明:field是去重字段,可以是单个的字段名,也可以是嵌套的字段名;query是查询条件,可以为空;
举例:
db.collection.distinct("user",{“age":{$gt:28}});//用于查询年龄age大于28岁的不同用户名
除了上面的用法外,还可以使用下面的另外一种方法:
db.runCommand({"distinct":"collectionname","key":"distinctfied","query":<query>})
collectionname:去重统计的集合名,distinctfield:去重字段,,<query>是可选的限制条件;
举例:
这两种方式的区别:第一种方法是对第二种方法的封装,第一种只返回去重统计后的字段值集合,但第二种方式既返回字段值集合也返回统计时的细节信息。
(3)group
作用:用于提供比count、distinct更丰富的统计需求,可以使用js函数控制统计逻辑
使用方式:db.collection.group(key,reduce,initial[,keyf][,cond][,finalize])
备注说明:在2.2版本之前,group操作最多只能返回10000条分组记录,但是从2.2版本之后到2.4版本,mongodb做了优化,能够支持返回20000条分组记录返回,如果分组记录的条数大于20000条,那么可能你就需要其他方式进行统计了,比如聚合管道或者MapReduce;
上面对Mongodb中自带的三种三种聚合函数进行了简单的描述,并对需要注意的地方进行了简单的说明,如果需要深入使用,可以进入Mongodb官网查看相关细节信息,谢谢。

相关文章推荐
- 分享微信开发Html5轻游戏中的几个坑
- Android之获取手机上的图片和视频缩略图thumbnails
- 如何在 Fedora 上安装 MongoDB 服务器
- PHP添加yaf xhprof mongodb 同理
- mongodb安装
- 数据库链接字符串查询网站
- 如何在 Ubuntu 上安装 MongoDB
- DB2实例管理
- DB2实例管理
- 保障MySQL数据安全的14个最佳方法
- mysql问答汇集
- 信息安全聚合 Sec-News 的重构之路
- 第三章 数据库备份和还原
- 创建一个空的IBM DB2 ECO数据库的方法
- Access 2000 数据库 80 万记录通用快速分页类
- 开通一个数据库失败的原因的和解决办法
- 一个简单的asp数据库操作类
- CentOS下DB2数据库安装过程详解
- EasyASP v1.5发布(包含数据库操作类,原clsDbCtrl.asp)第1/2页