JAVA设计模式(22):行为型-解释器模式(Interpreter)
2016-05-19 22:09
871 查看
虽然目前计算机编程语言有好几百种,但有时候我们还是希望能用一些简单的语言来实现一些特定的操作,我们只要向计算机输入一个句子或文件,它就能够按照预先定义的文法规则来对句子或文件进行解释,从而实现相应的功能。例如提供一个简单的加法/减法解释器,只要输入一个加法/减法表达式,它就能够计算出表达式结果,如图1所示,当输入字符串表达式为“1
+ 2 + 3 – 4 + 1”时,将输出计算结果为3。

图1 加法/减法解释器示意图
我们知道,像C++、Java和C#等语言无法直接解释类似“1+
2 + 3 – 4 + 1”这样的字符串(如果直接作为数值表达式时可以解释),我们必须自己定义一套文法规则来实现对这些语句的解释,即设计一个自定义语言。在实际开发中,这些简单的自定义语言可以基于现有的编程语言来设计,如果所基于的编程语言是面向对象语言,此时可以使用解释器模式来实现自定义语言。
Sunny软件公司开发人员决定自定义一个简单的语言来解释机器人控制指令,根据上述需求描述,用形式化语言来表示该简单语言的文法规则如下:
上述语言一共定义了五条文法规则,对应五个语言单位,这些语言单位可以分为两类,一类为终结符(也称为终结符表达式),例如direction、action和distance,它们是语言的最小组成单位,不能再进行拆分;另一类为非终结符(也称为非终结符表达式),例如expression和composite,它们都是一个完整的句子,包含一系列终结符或非终结符。
我们根据上述规则定义出的语言可以构成很多语句,计算机程序将根据这些语句进行某种操作。为了实现对语句的解释,可以使用解释器模式,在解释器模式中每一个文法规则都将对应一个类,扩展、改变文法以及增加新的文法规则都很方便,下面就让我们正式进入解释器模式的学习,看看使用解释器模式如何来实现对机器人控制指令的处理。
解释器模式描述了如何为简单的语言定义一个文法,如何在该语言中表示一个句子,以及如何解释这些句子。在正式分析解释器模式结构之前,我们先来学习如何表示一个语言的文法规则以及如何构造一棵抽象语法树。
在前面所提到的加法/减法解释器中,每一个输入表达式,例如“1 + 2 + 3 – 4 + 1”,都包含了三个语言单位,可以使用如下文法规则来定义:
该文法规则包含三条语句,第一条表示表达式的组成方式,其中value和operation是后面两个语言单位的定义,每一条语句所定义的字符串如operation和value称为语言构造成分或语言单位,符号“::=”表示“定义为”的意思,其左边的语言单位通过右边来进行说明和定义,语言单位对应终结符表达式和非终结符表达式。如本规则中的operation是非终结符表达式,它的组成元素仍然可以是表达式,可以进一步分解,而value是终结符表达式,它的组成元素是最基本的语言单位,不能再进行分解。
在文法规则定义中可以使用一些符号来表示不同的含义,如使用“|”表示或,使用“{”和“}”表示组合,使用“*”表示出现0次或多次等,其中使用频率最高的符号是表示“或”关系的“|”,如文法规则“boolValue
::= 0 | 1”表示终结符表达式boolValue的取值可以为0或者1。
除了使用文法规则来定义一个语言,在解释器模式中还可以通过一种称之为抽象语法树(Abstract Syntax Tree, AST)的图形方式来直观地表示语言的构成,每一棵抽象语法树对应一个语言实例,如加法/减法表达式语言中的语句“1+
2 + 3 – 4 + 1”,可以通过如图2所示抽象语法树来表示:
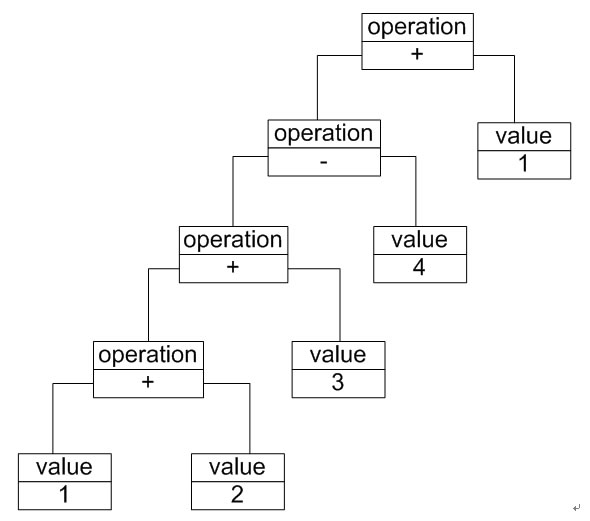
图22-2 抽象语法树示意图
在该抽象语法树中,可以通过终结符表达式value和非终结符表达式operation组成复杂的语句,每个文法规则的语言实例都可以表示为一个抽象语法树,即每一条具体的语句都可以用类似图22-2所示的抽象语法树来表示,在图中终结符表达式类的实例作为树的叶子节点,而非终结符表达式类的实例作为非叶子节点,它们可以将终结符表达式类的实例以及包含终结符和非终结符实例的子表达式作为其子节点。抽象语法树描述了如何构成一个复杂的句子,通过对抽象语法树的分析,可以识别出语言中的终结符类和非终结符类。
解释器模式是一种使用频率相对较低但学习难度较大的设计模式,它用于描述如何使用面向对象语言构成一个简单的语言解释器。在某些情况下,为了更好地描述某一些特定类型的问题,我们可以创建一种新的语言,这种语言拥有自己的表达式和结构,即文法规则,这些问题的实例将对应为该语言中的句子。此时,可以使用解释器模式来设计这种新的语言。对解释器模式的学习能够加深我们对面向对象思想的理解,并且掌握编程语言中文法规则的解释过程。
解释器模式定义如下:
由于表达式可分为终结符表达式和非终结符表达式,因此解释器模式的结构与组合模式的结构有些类似,但在解释器模式中包含更多的组成元素,它的结构如图3所示:
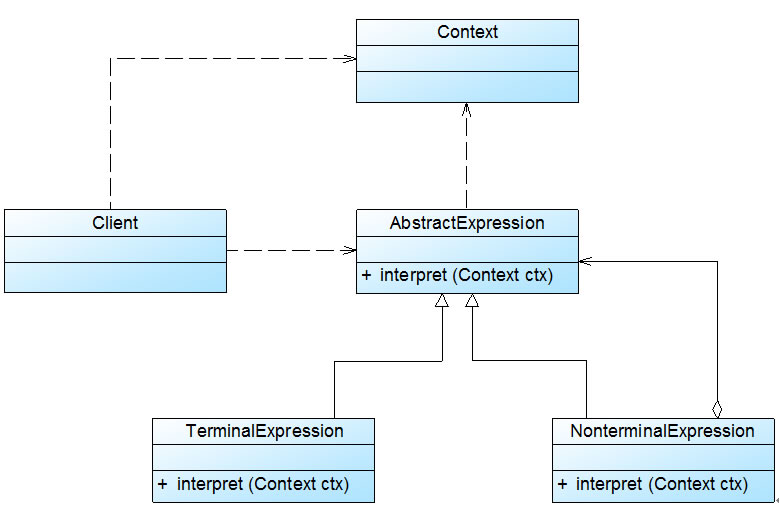
图3 解释器模式结构图
在解释器模式结构图中包含如下几个角色:
● AbstractExpression(抽象表达式):在抽象表达式中声明了抽象的解释操作,它是所有终结符表达式和非终结符表达式的公共父类。
● TerminalExpression(终结符表达式):终结符表达式是抽象表达式的子类,它实现了与文法中的终结符相关联的解释操作,在句子中的每一个终结符都是该类的一个实例。通常在一个解释器模式中只有少数几个终结符表达式类,它们的实例可以通过非终结符表达式组成较为复杂的句子。
● NonterminalExpression(非终结符表达式):非终结符表达式也是抽象表达式的子类,它实现了文法中非终结符的解释操作,由于在非终结符表达式中可以包含终结符表达式,也可以继续包含非终结符表达式,因此其解释操作一般通过递归的方式来完成。
● Context(环境类):环境类又称为上下文类,它用于存储解释器之外的一些全局信息,通常它临时存储了需要解释的语句。
在解释器模式中,每一种终结符和非终结符都有一个具体类与之对应,正因为使用类来表示每一条文法规则,所以系统将具有较好的灵活性和可扩展性。对于所有的终结符和非终结符,我们首先需要抽象出一个公共父类,即抽象表达式类,其典型代码如下所示:
终结符表达式和非终结符表达式类都是抽象表达式类的子类,对于终结符表达式,其代码很简单,主要是对终结符元素的处理,其典型代码如下所示:
对于非终结符表达式,其代码相对比较复杂,因为可以通过非终结符将表达式组合成更加复杂的结构,对于包含两个操作元素的非终结符表达式类,其典型代码如下:
除了上述用于表示表达式的类以外,通常在解释器模式中还提供了一个环境类Context,用于存储一些全局信息,通常在Context中包含了一个HashMap或ArrayList等类型的集合对象(也可以直接由HashMap等集合类充当环境类),存储一系列公共信息,如变量名与值的映射关系(key/value)等,用于在进行具体的解释操作时从中获取相关信息。其典型代码片段如下:
当系统无须提供全局公共信息时可以省略环境类,可根据实际情况决定是否需要环境类。
为了能够解释机器人控制指令,Sunny软件公司开发人员使用解释器模式来设计和实现机器人控制程序。针对五条文法规则,分别提供五个类来实现,其中终结符表达式direction、action和distance对应DirectionNode类、ActionNode类和DistanceNode类,非终结符表达式expression和composite对应SentenceNode类和AndNode类。
我们可以通过抽象语法树来表示具体解释过程,例如机器人控制指令“down run 10 and left move 20”对应的抽象语法树如图4所示:
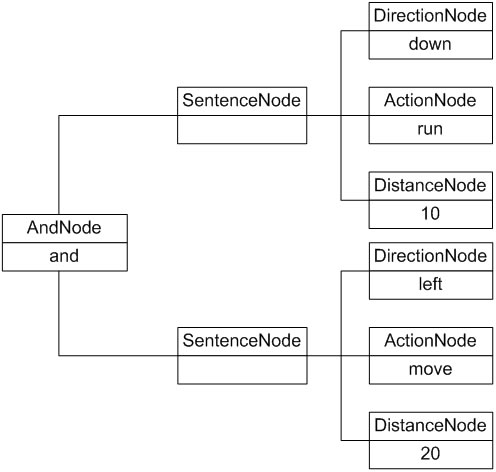
图4 机器人控制程序抽象语法树实例
机器人控制程序实例基本结构如图5所示:
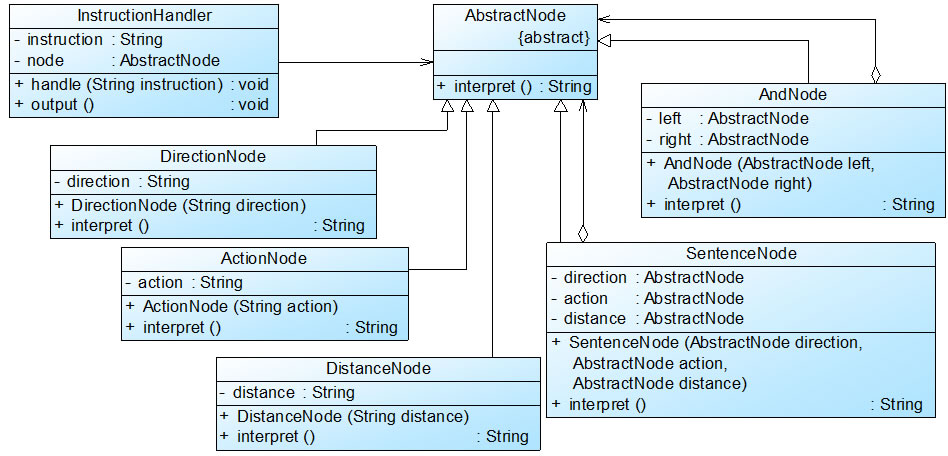
图22-5 机器人控制程序结构图
在图22-5中,AbstractNode充当抽象表达式角色,DirectionNode、ActionNode和DistanceNode充当终结符表达式角色,AndNode和SentenceNode充当非终结符表达式角色。完整代码如下所示:
工具类InstructionHandler用于对输入指令进行处理,将输入指令分割为字符串数组,将第1个、第2个和第3个单词组合成一个句子,并存入栈中;如果发现有单词“and”,则将“and”后的第1个、第2个和第3个单词组合成一个新的句子作为“and”的右表达式,并从栈中取出原先所存句子作为左表达式,然后组合成一个And节点存入栈中。依此类推,直到整个指令解析结束。
编写如下客户端测试代码:
编译并运行程序,输出结果如下:
在解释器模式中,环境类Context用于存储解释器之外的一些全局信息,它通常作为参数被传递到所有表达式的解释方法interpret()中,可以在Context对象中存储和访问表达式解释器的状态,向表达式解释器提供一些全局的、公共的数据,此外还可以在Context中增加一些所有表达式解释器都共有的功能,减轻解释器的职责。
在上面的机器人控制程序实例中,我们省略了环境类角色,下面再通过一个简单实例来说明环境类的用途:
Sunny软件公司开发人员通过分析,根据该格式化指令中句子的组成,定义了如下文法规则:
根据以上文法规则,通过进一步分析,绘制如图6所示结构图:
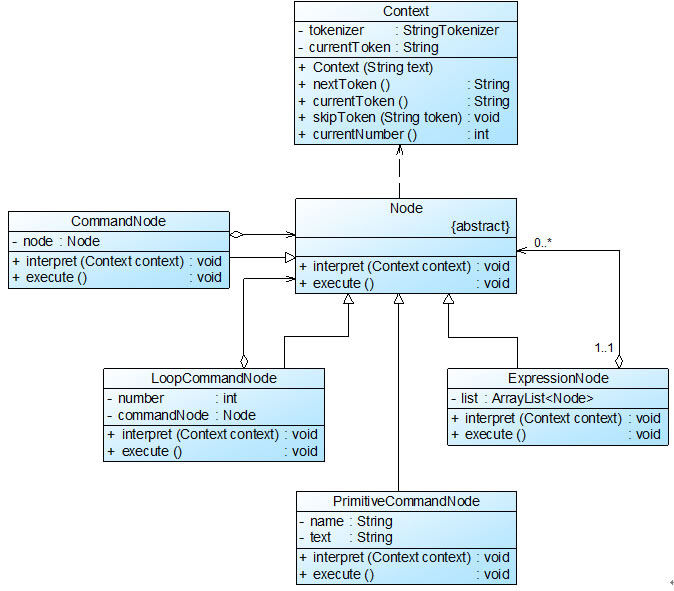
图6 格式化指令结构图
在图6中,Context充当环境角色,Node充当抽象表达式角色,ExpressionNode、CommandNode和LoopCommandNode充当非终结符表达式角色,PrimitiveCommandNode充当终结符表达式角色。完整代码如下所示:
在本实例代码中,环境类Context类似一个工具类,它提供了用于处理指令的方法,如nextToken()、currentToken()、skipToken()等,同时它存储了需要解释的指令并记录了每一次解释的当前标记(Token),而具体的解释过程交给表达式解释器类来处理。我们还可以将各种解释器类包含的公共方法移至环境类中,更好地实现这些方法的重用和扩展。
针对本实例代码,我们编写如下客户端测试代码:
编译并运行程序,输出结果如下:
解释器模式为自定义语言的设计和实现提供了一种解决方案,它用于定义一组文法规则并通过这组文法规则来解释语言中的句子。虽然解释器模式的使用频率不是特别高,但是它在正则表达式、XML文档解释等领域还是得到了广泛使用。与解释器模式类似,目前还诞生了很多基于抽象语法树的源代码处理工具,例如Eclipse中的Eclipse
AST,它可以用于表示Java语言的语法结构,用户可以通过扩展其功能,创建自己的文法规则。
1. 主要优点
解释器模式的主要优点如下:
(1) 易于改变和扩展文法。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。
(2) 每一条文法规则都可以表示为一个类,因此可以方便地实现一个简单的语言。
(3) 实现文法较为容易。在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂,还可以通过一些工具自动生成节点类代码。
(4) 增加新的解释表达式较为方便。如果用户需要增加新的解释表达式只需要对应增加一个新的终结符表达式或非终结符表达式类,原有表达式类代码无须修改,符合“开闭原则”。
2. 主要缺点
解释器模式的主要缺点如下:
(1) 对于复杂文法难以维护。在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护,此时可以考虑使用语法分析程序等方式来取代解释器模式。
(2) 执行效率较低。由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦。
3. 适用场景
在以下情况下可以考虑使用解释器模式:
(1) 可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。
(2) 一些重复出现的问题可以用一种简单的语言来进行表达。
(3) 一个语言的文法较为简单。
(4) 执行效率不是关键问题。【注:高效的解释器通常不是通过直接解释抽象语法树来实现的,而是需要将它们转换成其他形式,使用解释器模式的执行效率并不高。】
解释器模式可以说是所有设计模式中难度较大、使用频率较低的一个模式,如果您能够静下心来把这几篇文章都看完,我相信您对解释器模式应该有了一个较为全面的了解,欢迎大家与我交流和讨论。
感谢您能够坚持看完这六篇关于解释器模式的文章,

!
+ 2 + 3 – 4 + 1”时,将输出计算结果为3。
图1 加法/减法解释器示意图
我们知道,像C++、Java和C#等语言无法直接解释类似“1+
2 + 3 – 4 + 1”这样的字符串(如果直接作为数值表达式时可以解释),我们必须自己定义一套文法规则来实现对这些语句的解释,即设计一个自定义语言。在实际开发中,这些简单的自定义语言可以基于现有的编程语言来设计,如果所基于的编程语言是面向对象语言,此时可以使用解释器模式来实现自定义语言。
1 机器人控制程序
| Sunny软件公司欲为某玩具公司开发一套机器人控制程序,在该机器人控制程序中包含一些简单的英文控制指令,每一个指令对应一个表达式(expression),该表达式可以是简单表达式也可以是复合表达式,每一个简单表达式由移动方向(direction),移动方式(action)和移动距离(distance)三部分组成,其中移动方向包括上(up)、下(down)、左(left)、右(right);移动方式包括移动(move)和快速移动(run);移动距离为一个正整数。两个表达式之间可以通过与(and)连接,形成复合(composite)表达式。 用户通过对图形化的设置界面进行操作可以创建一个机器人控制指令,机器人在收到指令后将按照指令的设置进行移动,例如输入控制指令:up move 5,则“向上移动5个单位”;输入控制指令:down run 10 and left move 20,则“向下快速移动10个单位再向左移动20个单位”。 |
| expression ::= direction action distance | composite //表达式 composite ::= expression 'and' expression //复合表达式 direction ::= 'up' | 'down' | 'left' | 'right' //移动方向 action ::= 'move' | 'run' //移动方式 distance ::= an integer //移动距离 |
我们根据上述规则定义出的语言可以构成很多语句,计算机程序将根据这些语句进行某种操作。为了实现对语句的解释,可以使用解释器模式,在解释器模式中每一个文法规则都将对应一个类,扩展、改变文法以及增加新的文法规则都很方便,下面就让我们正式进入解释器模式的学习,看看使用解释器模式如何来实现对机器人控制指令的处理。
2 文法规则和抽象语法树
解释器模式描述了如何为简单的语言定义一个文法,如何在该语言中表示一个句子,以及如何解释这些句子。在正式分析解释器模式结构之前,我们先来学习如何表示一个语言的文法规则以及如何构造一棵抽象语法树。在前面所提到的加法/减法解释器中,每一个输入表达式,例如“1 + 2 + 3 – 4 + 1”,都包含了三个语言单位,可以使用如下文法规则来定义:
| expression ::= value | operation operation ::= expression '+' expression | expression '-' expression value ::= an integer //一个整数值 |
在文法规则定义中可以使用一些符号来表示不同的含义,如使用“|”表示或,使用“{”和“}”表示组合,使用“*”表示出现0次或多次等,其中使用频率最高的符号是表示“或”关系的“|”,如文法规则“boolValue
::= 0 | 1”表示终结符表达式boolValue的取值可以为0或者1。
除了使用文法规则来定义一个语言,在解释器模式中还可以通过一种称之为抽象语法树(Abstract Syntax Tree, AST)的图形方式来直观地表示语言的构成,每一棵抽象语法树对应一个语言实例,如加法/减法表达式语言中的语句“1+
2 + 3 – 4 + 1”,可以通过如图2所示抽象语法树来表示:
图22-2 抽象语法树示意图
在该抽象语法树中,可以通过终结符表达式value和非终结符表达式operation组成复杂的语句,每个文法规则的语言实例都可以表示为一个抽象语法树,即每一条具体的语句都可以用类似图22-2所示的抽象语法树来表示,在图中终结符表达式类的实例作为树的叶子节点,而非终结符表达式类的实例作为非叶子节点,它们可以将终结符表达式类的实例以及包含终结符和非终结符实例的子表达式作为其子节点。抽象语法树描述了如何构成一个复杂的句子,通过对抽象语法树的分析,可以识别出语言中的终结符类和非终结符类。
3 解释器模式概述
解释器模式是一种使用频率相对较低但学习难度较大的设计模式,它用于描述如何使用面向对象语言构成一个简单的语言解释器。在某些情况下,为了更好地描述某一些特定类型的问题,我们可以创建一种新的语言,这种语言拥有自己的表达式和结构,即文法规则,这些问题的实例将对应为该语言中的句子。此时,可以使用解释器模式来设计这种新的语言。对解释器模式的学习能够加深我们对面向对象思想的理解,并且掌握编程语言中文法规则的解释过程。解释器模式定义如下:
| 解释器模式(Interpreter Pattern):定义一个语言的文法,并且建立一个解释器来解释该语言中的句子,这里的“语言”是指使用规定格式和语法的代码。解释器模式是一种类行为型模式。 |
图3 解释器模式结构图
在解释器模式结构图中包含如下几个角色:
● AbstractExpression(抽象表达式):在抽象表达式中声明了抽象的解释操作,它是所有终结符表达式和非终结符表达式的公共父类。
● TerminalExpression(终结符表达式):终结符表达式是抽象表达式的子类,它实现了与文法中的终结符相关联的解释操作,在句子中的每一个终结符都是该类的一个实例。通常在一个解释器模式中只有少数几个终结符表达式类,它们的实例可以通过非终结符表达式组成较为复杂的句子。
● NonterminalExpression(非终结符表达式):非终结符表达式也是抽象表达式的子类,它实现了文法中非终结符的解释操作,由于在非终结符表达式中可以包含终结符表达式,也可以继续包含非终结符表达式,因此其解释操作一般通过递归的方式来完成。
● Context(环境类):环境类又称为上下文类,它用于存储解释器之外的一些全局信息,通常它临时存储了需要解释的语句。
在解释器模式中,每一种终结符和非终结符都有一个具体类与之对应,正因为使用类来表示每一条文法规则,所以系统将具有较好的灵活性和可扩展性。对于所有的终结符和非终结符,我们首先需要抽象出一个公共父类,即抽象表达式类,其典型代码如下所示:
abstract class AbstractExpression {
public abstract void interpret(Context ctx);
}终结符表达式和非终结符表达式类都是抽象表达式类的子类,对于终结符表达式,其代码很简单,主要是对终结符元素的处理,其典型代码如下所示:
class TerminalExpression extends AbstractExpression {
public void interpret(Context ctx) {
//终结符表达式的解释操作
}
}对于非终结符表达式,其代码相对比较复杂,因为可以通过非终结符将表达式组合成更加复杂的结构,对于包含两个操作元素的非终结符表达式类,其典型代码如下:
class NonterminalExpression extends AbstractExpression {
private AbstractExpression left;
private AbstractExpression right;
public NonterminalExpression(AbstractExpression left,AbstractExpression right) {
this.left=left;
this.right=right;
}
public void interpret(Context ctx) {
//递归调用每一个组成部分的interpret()方法
//在递归调用时指定组成部分的连接方式,即非终结符的功能
}
}除了上述用于表示表达式的类以外,通常在解释器模式中还提供了一个环境类Context,用于存储一些全局信息,通常在Context中包含了一个HashMap或ArrayList等类型的集合对象(也可以直接由HashMap等集合类充当环境类),存储一系列公共信息,如变量名与值的映射关系(key/value)等,用于在进行具体的解释操作时从中获取相关信息。其典型代码片段如下:
class Context {
private HashMap map = new HashMap();
public void assign(String key, String value) {
//往环境类中设值
}
public String lookup(String key) {
//获取存储在环境类中的值
}
}当系统无须提供全局公共信息时可以省略环境类,可根据实际情况决定是否需要环境类。
|
4 完整解决方案
为了能够解释机器人控制指令,Sunny软件公司开发人员使用解释器模式来设计和实现机器人控制程序。针对五条文法规则,分别提供五个类来实现,其中终结符表达式direction、action和distance对应DirectionNode类、ActionNode类和DistanceNode类,非终结符表达式expression和composite对应SentenceNode类和AndNode类。我们可以通过抽象语法树来表示具体解释过程,例如机器人控制指令“down run 10 and left move 20”对应的抽象语法树如图4所示:
图4 机器人控制程序抽象语法树实例
机器人控制程序实例基本结构如图5所示:
图22-5 机器人控制程序结构图
在图22-5中,AbstractNode充当抽象表达式角色,DirectionNode、ActionNode和DistanceNode充当终结符表达式角色,AndNode和SentenceNode充当非终结符表达式角色。完整代码如下所示:
//注:本实例对机器人控制指令的输出结果进行模拟,将英文指令翻译为中文指令,实际情况是调用不同的控制程序进行机器人的控制,包括对移动方向、方式和距离的控制等
import java.util.*;
//抽象表达式
abstract class AbstractNode {
public abstract String interpret();
}
//And解释:非终结符表达式
class AndNode extends AbstractNode {
private AbstractNode left; //And的左表达式
private AbstractNode right; //And的右表达式
public AndNode(AbstractNode left, AbstractNode right) {
this.left = left;
this.right = right;
}
//And表达式解释操作
public String interpret() {
return left.interpret() + "再" + right.interpret();
}
}
//简单句子解释:非终结符表达式
class SentenceNode extends AbstractNode {
private AbstractNode direction;
private AbstractNode action;
private AbstractNode distance;
public SentenceNode(AbstractNode direction,AbstractNode action,AbstractNode distance) {
this.direction = direction;
this.action = action;
this.distance = distance;
}
//简单句子的解释操作
public String interpret() {
return direction.interpret() + action.interpret() + distance.interpret();
}
}
//方向解释:终结符表达式
class DirectionNode extends AbstractNode {
private String direction;
public DirectionNode(String direction) {
this.direction = direction;
}
//方向表达式的解释操作
public String interpret() {
if (direction.equalsIgnoreCase("up")) {
return "向上";
}
else if (direction.equalsIgnoreCase("down")) {
return "向下";
}
else if (direction.equalsIgnoreCase("left")) {
return "向左";
}
else if (direction.equalsIgnoreCase("right")) {
return "向右";
}
else {
return "无效指令";
}
}
}
//动作解释:终结符表达式
class ActionNode extends AbstractNode {
private String action;
public ActionNode(String action) {
this.action = action;
}
//动作(移动方式)表达式的解释操作
public String interpret() {
if (action.equalsIgnoreCase("move")) {
return "移动";
}
else if (action.equalsIgnoreCase("run")) {
return "快速移动";
}
else {
return "无效指令";
}
}
}
//距离解释:终结符表达式
class DistanceNode extends AbstractNode {
private String distance;
public DistanceNode(String distance) {
this.distance = distance;
}
//距离表达式的解释操作
public String interpret() {
return this.distance;
}
}
//指令处理类:工具类
class InstructionHandler {
private String instruction;
private AbstractNode node;
public void handle(String instruction) {
AbstractNode left = null, right = null;
AbstractNode direction = null, action = null, distance = null;
Stack stack = new Stack(); //声明一个栈对象用于存储抽象语法树
String[] words = instruction.split(" "); //以空格分隔指令字符串
for (int i = 0; i < words.length; i++) {
//本实例采用栈的方式来处理指令,如果遇到“and”,则将其后的三个单词作为三个终结符表达式连成一个简单句子SentenceNode作为“and”的右表达式,而将从栈顶弹出的表达式作为“and”的左表达式,最后将新的“and”表达式压入栈中。 if (words[i].equalsIgnoreCase("and")) {
left = (AbstractNode)stack.pop(); //弹出栈顶表达式作为左表达式
String word1= words[++i];
direction = new DirectionNode(word1);
String word2 = words[++i];
action = new ActionNode(word2);
String word3 = words[++i];
distance = new DistanceNode(word3);
right = new SentenceNode(direction,action,distance); //右表达式
stack.push(new AndNode(left,right)); //将新表达式压入栈中
}
//如果是从头开始进行解释,则将前三个单词组成一个简单句子SentenceNode并将该句子压入栈中
else {
String word1 = words[i];
direction = new DirectionNode(word1);
String word2 = words[++i];
action = new ActionNode(word2);
String word3 = words[++i];
distance = new DistanceNode(word3);
left = new SentenceNode(direction,action,distance);
stack.push(left); //将新表达式压入栈中
}
}
this.node = (AbstractNode)stack.pop(); //将全部表达式从栈中弹出
}
public String output() {
String result = node.interpret(); //解释表达式
return result;
}
}工具类InstructionHandler用于对输入指令进行处理,将输入指令分割为字符串数组,将第1个、第2个和第3个单词组合成一个句子,并存入栈中;如果发现有单词“and”,则将“and”后的第1个、第2个和第3个单词组合成一个新的句子作为“and”的右表达式,并从栈中取出原先所存句子作为左表达式,然后组合成一个And节点存入栈中。依此类推,直到整个指令解析结束。
编写如下客户端测试代码:
class Client {
public static void main(String args[]) {
String instruction = "up move 5 and down run 10 and left move 5";
InstructionHandler handler = new InstructionHandler();
handler.handle(instruction);
String outString;
outString = handler.output();
System.out.println(outString);
}
}编译并运行程序,输出结果如下:
| 向上移动5再向下快速移动10再向左移动5 |
5 再谈Context的作用
在解释器模式中,环境类Context用于存储解释器之外的一些全局信息,它通常作为参数被传递到所有表达式的解释方法interpret()中,可以在Context对象中存储和访问表达式解释器的状态,向表达式解释器提供一些全局的、公共的数据,此外还可以在Context中增加一些所有表达式解释器都共有的功能,减轻解释器的职责。在上面的机器人控制程序实例中,我们省略了环境类角色,下面再通过一个简单实例来说明环境类的用途:
| Sunny软件公司开发了一套简单的基于字符界面的格式化指令,可以根据输入的指令在字符界面中输出一些格式化内容,例如输入“LOOP 2 PRINT杨过 SPACE SPACE PRINT 小龙女 BREAK END PRINT郭靖 SPACE SPACE PRINT 黄蓉”,将输出如下结果:
现使用解释器模式设计并实现该格式化指令的解释,对指令进行分析并调用相应的操作执行指令中每一条命令。 |
| expression ::= command* //表达式,一个表达式包含多条命令 command ::= loop | primitive //语句命令 loop ::= 'loopnumber' expression 'end' //循环命令,其中number为自然数 primitive ::= 'printstring' | 'space' | 'break' //基本命令,其中string为字符串 |
图6 格式化指令结构图
在图6中,Context充当环境角色,Node充当抽象表达式角色,ExpressionNode、CommandNode和LoopCommandNode充当非终结符表达式角色,PrimitiveCommandNode充当终结符表达式角色。完整代码如下所示:
import java.util.*;
//环境类:用于存储和操作需要解释的语句,在本实例中每一个需要解释的单词可以称为一个动作标记(Action Token)或命令
class Context {
private StringTokenizer tokenizer; //StringTokenizer类,用于将字符串分解为更小的字符串标记(Token),默认情况下以空格作为分隔符
private String currentToken; //当前字符串标记
public Context(String text) {
tokenizer = new StringTokenizer(text); //通过传入的指令字符串创建StringTokenizer对象
nextToken();
}
//返回下一个标记
public String nextToken() {
if (tokenizer.hasMoreTokens()) {
currentToken = tokenizer.nextToken();
}
else {
currentToken = null;
}
return currentToken;
}
//返回当前的标记
public String currentToken() {
return currentToken;
}
//跳过一个标记
public void skipToken(String token) {
if (!token.equals(currentToken)) {
System.err.println("错误提示:" + currentToken + "解释错误!");
}
nextToken();
}
//如果当前的标记是一个数字,则返回对应的数值
public int currentNumber() {
int number = 0;
try{
number = Integer.parseInt(currentToken); //将字符串转换为整数
}
catch(NumberFormatException e) {
System.err.println("错误提示:" + e);
}
return number;
}
}
//抽象节点类:抽象表达式
abstract class Node {
public abstract void interpret(Context text); //声明一个方法用于解释语句
public abstract void execute(); //声明一个方法用于执行标记对应的命令
}
//表达式节点类:非终结符表达式
class ExpressionNode extends Node {
private ArrayList<Node> list = new ArrayList<Node>(); //定义一个集合用于存储多条命令
public void interpret(Context context) {
//循环处理Context中的标记
while (true){
//如果已经没有任何标记,则退出解释
if (context.currentToken() == null) {
break;
}
//如果标记为END,则不解释END并结束本次解释过程,可以继续之后的解释
else if (context.currentToken().equals("END")) {
context.skipToken("END");
break;
}
//如果为其他标记,则解释标记并将其加入命令集合
else {
Node commandNode = new CommandNode();
commandNode.interpret(context);
list.add(commandNode);
}
}
}
//循环执行命令集合中的每一条命令
public void execute() {
Iterator iterator = list.iterator();
while (iterator.hasNext()){
((Node)iterator.next()).execute();
}
}
}
//语句命令节点类:非终结符表达式
class CommandNode extends Node {
private Node node;
public void interpret(Context context) {
//处理LOOP循环命令
if (context.currentToken().equals("LOOP")) {
node = new LoopCommandNode();
node.interpret(context);
}
//处理其他基本命令
else {
node = new PrimitiveCommandNode();
node.interpret(context);
}
}
public void execute() {
node.execute();
}
}
//循环命令节点类:非终结符表达式
class LoopCommandNode extends Node {
private int number; //循环次数
private Node commandNode; //循环语句中的表达式
//解释循环命令
public void interpret(Context context) {
context.skipToken("LOOP");
number = context.currentNumber();
context.nextToken();
commandNode = new ExpressionNode(); //循环语句中的表达式
commandNode.interpret(context);
}
public void execute() {
for (int i=0;i<number;i++)
commandNode.execute();
}
}
//基本命令节点类:终结符表达式
class PrimitiveCommandNode extends Node {
private String name;
private String text;
//解释基本命令
public void interpret(Context context) {
name = context.currentToken();
context.skipToken(name);
if (!name.equals("PRINT") && !name.equals("BREAK") && !name.equals ("SPACE")){
System.err.println("非法命令!");
}
if (name.equals("PRINT")){
text = context.currentToken();
context.nextToken();
}
}
public void execute(){
if (name.equals("PRINT"))
System.out.print(text);
else if (name.equals("SPACE"))
System.out.print(" ");
else if (name.equals("BREAK"))
System.out.println();
}
}在本实例代码中,环境类Context类似一个工具类,它提供了用于处理指令的方法,如nextToken()、currentToken()、skipToken()等,同时它存储了需要解释的指令并记录了每一次解释的当前标记(Token),而具体的解释过程交给表达式解释器类来处理。我们还可以将各种解释器类包含的公共方法移至环境类中,更好地实现这些方法的重用和扩展。
针对本实例代码,我们编写如下客户端测试代码:
class Client{
public static void main(String[] args){
String text = "LOOP 2 PRINT 杨过 SPACE SPACE PRINT 小龙女 BREAK END PRINT 郭靖 SPACE SPACE PRINT 黄蓉";
Context context = new Context(text);
Node node = new ExpressionNode();
node.interpret(context);
node.execute();
}
}编译并运行程序,输出结果如下:
| 杨过 小龙女 杨过 小龙女 郭靖 黄蓉 |
|
6 解释器模式总结
解释器模式为自定义语言的设计和实现提供了一种解决方案,它用于定义一组文法规则并通过这组文法规则来解释语言中的句子。虽然解释器模式的使用频率不是特别高,但是它在正则表达式、XML文档解释等领域还是得到了广泛使用。与解释器模式类似,目前还诞生了很多基于抽象语法树的源代码处理工具,例如Eclipse中的EclipseAST,它可以用于表示Java语言的语法结构,用户可以通过扩展其功能,创建自己的文法规则。
1. 主要优点
解释器模式的主要优点如下:
(1) 易于改变和扩展文法。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。
(2) 每一条文法规则都可以表示为一个类,因此可以方便地实现一个简单的语言。
(3) 实现文法较为容易。在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂,还可以通过一些工具自动生成节点类代码。
(4) 增加新的解释表达式较为方便。如果用户需要增加新的解释表达式只需要对应增加一个新的终结符表达式或非终结符表达式类,原有表达式类代码无须修改,符合“开闭原则”。
2. 主要缺点
解释器模式的主要缺点如下:
(1) 对于复杂文法难以维护。在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护,此时可以考虑使用语法分析程序等方式来取代解释器模式。
(2) 执行效率较低。由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦。
3. 适用场景
在以下情况下可以考虑使用解释器模式:
(1) 可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。
(2) 一些重复出现的问题可以用一种简单的语言来进行表达。
(3) 一个语言的文法较为简单。
(4) 执行效率不是关键问题。【注:高效的解释器通常不是通过直接解释抽象语法树来实现的,而是需要将它们转换成其他形式,使用解释器模式的执行效率并不高。】
|
感谢您能够坚持看完这六篇关于解释器模式的文章,
!

相关文章推荐
- Java重写Override和重载Overload
- 【java web 培训】java.lang.ClassNotFoundException: com.mysql.jdbc.Driver(转载,已实现)
- Java数组之排序
- JAVA设计模式(21):行为型-迭代器模式(Iterator)
- Eclipse添加注释模板
- JAVA-008类和对象
- JAVA设计模式(20):行为型-备忘录模式(Memento)
- java远程服务调用方法
- java实现163邮箱发送邮件到qq邮箱成功案例
- Java RandomAccessFile用法
- java初步了解
- 使用Eclipse中出现的一些问题的解决方法
- java泛型实现链式栈
- Java笔记---ArrayList源码分析
- spring mvc流转控制说明
- Java的基本点
- JDK支持的JAXB版本
- SSM框架——详细整合教程(Spring+SpringMVC+MyBatis)
- Java数组
- <<深入Java虚拟机>>-虚拟机类加载机制-学习笔记