MongoDB学习笔记系列:(八) 复制
2016-05-15 16:06
369 查看
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://zhanyah.blog.51cto.com/2821907/1270518
一、主从集群简介
高可用性通常描述一个系统经过专门的设计,从而减少停工时间。
保存其服务的高度连续可用性,MongoDB提供的主从复制机制保证了多个数据库的数据同步,这对实现数据库的容灾、备份、恢复、负载均衡都是有极大的帮助.
主从复制的优点:
从服务器可以执行查询工作,降低主服务器访问压力;
在从服务器执行备份,避免备份期间锁定主服务器的数据;
当主服务器出现故障时,可以快速切换到从服务器,减少当机时间;
MongoDB支持在多个机器中通过异步复制到底故障转移和实现冗余,多台机器中同一时刻只有一台是用于写操作,
这为mongoDB提供了数据一致性的保障.担当Primary角色的机器能把读操作分发给slave机器。
MongoDB的主从集群分为两种:
Master-Slave 复制(主从复制)
Replica Sets 复制(副本集)
主服务器支持增删该,从服务器主要支持读.
Master-Slave(主从复制):
只需要在某一个服务启动时加上-master参数,以指明此服务器的角色是primary,
而另一个服务加上-slave与-source参数,以指明此服务器的角色是slave. 即可实现同步。
MongoDB的最新版本已经不推荐使用这种方法了。
Replica Sets 复制(副本集):
MongoDB在1.6版本开发了replica set,主要增加了故障自动切换和自动修复成员节点。
各个DB之间数据完全一致,最为显著的区别在于:
副本集没有固定的主节点,它是整个集群选举得出的一个主节点,当其不工作时变更其它节点。
二、主从复制(Master-Slave)
1、概念:主从复制是一个简单的数据库同步备份的集群技术。简单结构,如下图所示:
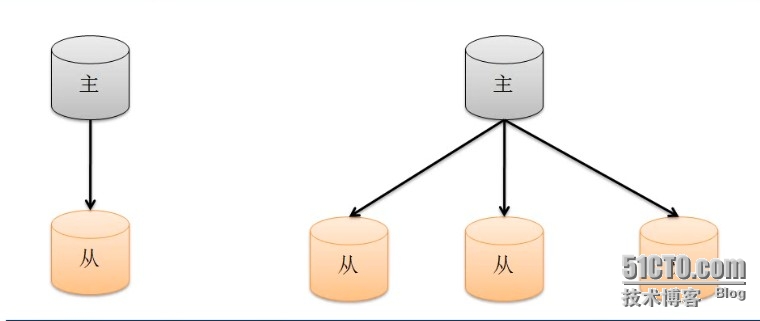
(1)、在数据库集群中要明确的知道谁是主服务器,主服务器只有一台。
(2)、从服务器要知道自己的数据源,也就是对于自己的主服务器是谁。
(3)、--master用来确定主服务器,--slave来控制从服务器, --source确定从服务的数据源。
2、主从复制集群案例
主服务器:1111
参数配置:
dbpath=D:\Work\MongoDB\Data\1111 #主数据库地址
bind_ip=127.0.0.1 #主数据库所在服务器IP
port=1111 #主数据库端口号
master=true #确定主服务器
从服务器:2222
参数配置:
dbpath=D:\Work\MongoDB\Data\2222 #从数据库地址
bind_ip=127.0.0.1 #从数据库所在服务器IP
port=2222 #从数据库端口号
source=127.0.0.1:1111 #主数据的服务器IP和端口
#这个配置项(source),可以用shell动态添加
slave=true #确定从服务器
3、主从复制选项
--only 从节点->指定复制某个数据库,默认是复制全部数据库;
--slavedelay 从节点->设置主数据库同步数据的延迟时间,单位为秒;
--fastsync 从节点->以主数据库的节点快照为节点,启动从数据库;
--oplogSize 主节点->设置oplog的大小(主节点操作记录,存储在local数据库的oplog中);
4、利用shell动态添加和删除从节点
示例:
> use local
switched to db local
> db.sources.find()
{ "host" : "127.0.0.1:1111", "source" : "main", "syncedTo" : { "t" : 1376132657, "i" : 1 } }
从上面的示例中,不难看出从节点中关于主节点的信息,全部存储到local数据库的sources集合中。
我们只要对sources集合进行操作,就可以动态操作主从关系。
(1)添加数据源
db.sources.insert({"host":"127.0.0.1:1111"})
(2)删除数据源
db.sources.remove({"host":"127.0.0.1:1111"})
三、副本集(Replica Sets)
1、概念:副本集就是具有自动故障恢复功能的主从集群(俗称"故障转移集群")。简单结构,
如下图所示:
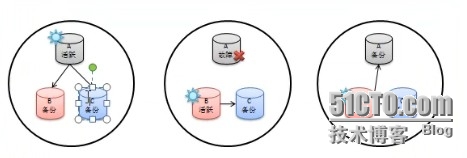
1.1、第一张图表明A是活跃的,B和C是用于备份的;
1.2、第二张图表明当A出现了故障,这时候集群根据权重算法,推选出B为活跃的数据库;
1.3、第三张图表明当A恢复后,它自动又会变为备份数据库。
2、特点:
(1)、与普通主从复制集群相比,具有自动检测机制;
(2)、需要使用--replset选项指定副本同伴;
(3)、任何时候,副本集当中只允许有一个活跃节点。
3、副本集案例:
A服务器:1111
参数配置:
dbpath=D:\Work\MongoDB\Data\replset\1111 #数据库地址
bind_ip=127.0.0.1 #数据库所在服务器IP
port=1111 #数据库端口号
replSet=child/127.0.0.1:2222 #设定同伴
B服务器:2222
参数配置:
dbpath=D:\Work\MongoDB\Data\replset\2222 #数据库地址
bind_ip=127.0.0.1 #数据库所在服务器IP
port=2222 #数据库端口号
replSet=child/127.0.0.1:3333 #设定同伴
C服务器:3333
参数配置:
dbpath=D:\Work\MongoDB\Data\replset\3333 #数据库地址
bind_ip=127.0.0.1 #数据库所在服务器IP
port=3333 #数据库端口号
replSet=child/127.0.0.1:1111 #设定同伴s
4、初始化副本集
use admin;
db.runCommand({"replSetInitiate":
{
"_id":"child",#副本集名称
"members":[{
"_id":1, #服务器唯一ID(必须为数字)
"host":"127.0.0.1:1111" #服务器主机地址
},{
"_id":2,
"host":"127.0.0.1:2222"
},{
"_id":3,
"host":"127.0.0.1:3333"
}]
}
});
初始化副本集的结果:
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}
5、查看副本集状态
rs.status();#查看副本集所有服务器状态。
rs.isMaster();#查看副本集中当前服务器状态。
6、查看主从配置信息
在local库中不仅有主从日志oplog.rs,还有一个集合用于记录主从配置信息system.replset。
通过执行”db.system.replset.find()”命令查看复制集的配置信息,查询结果如下所示:
child:PRIMARY> use local
switched to db local
child:PRIMARY> db.system.replset.find()
{
"_id" : "child", "version" : 1,
"members" : [
{ "_id" : 1, "host" : "127.0.0.1:11111" },
{ "_id" : 2, "host" : "127.0.0.1:2222" },
{ "_id" : 3, "host" : "127.0.0.1:3333" }
]
}
7、副本集中的节点类型
standard->常规节点:参与投票有可能成为活跃节点。
passive->副本节点:参与投票,但是不能成为活跃节点。
arbiter->仲裁节点:只是参与投票,不复制节点,也不能成为活跃节点。
8、初始化高级参数
priority:0到1000之间,0代表是副本节点,1到1000是常规节点;
通过这个我们可以指明副本集某台服务器节点初始为活跃节点。
arbiterOnly:true,仲裁节点;特定指明某个服务器节点为仲裁节点,仲裁节点不会复制数据,不会成为活跃节点;
其存在的目的只有一个:当前活跃节点失效后,副本集内重新投票选活跃节点时,防止出现僵局!
9、故障切换和活跃点选举
当前活跃节点失效,包括两种情况:
(1)当前活跃节点宕机或本身异常。
(2)当前活跃节点会通过心跳跟踪集群中多少节点对其可见,如果数量小于集群服务器数量的一半,会自动降级为备份节点。
此时,集群会投票选举出一个新的活跃节点(新比较优先级,优先级相同的,各个节点判断哪个数据最新,就会投哪个)。
任何时候,活跃节点的数据会被认为是最新的,当重新确定了活跃节点后,所有其他节点都要重新进行完整同步(数据可能发生回滚)。
四、在服务器上执行操作
1、读写分离(扩展读)
一般情况下,作为副本的节点是不能进行数据库读操作的,但是在读取密集型的系统中,读写分离是十分必要的。
2、设置读写分离
slaveOkay:true
3、读写分离的特点:
(1)、将密集的读取操作分流到从节点上,降低主节点的负载。
(2)、默认情况下,从节点是不允许处理客户端请求的,需要使用--slaveOkay打开。
(3)、不适用于实时性要求非常高的应用。
五、工作原理
1、oplog
oplog保存在local数据库中,oplog就在其中的oplog.$main集合内保存。该集合的每个文档都记录了主节点上执行的一个操作,其键定义如下:
ts:操作时间戳,占用4字符;
op:操作类型,占用2个字节;
ns:操作对象的命名空间(或理解为集合全名);
O:
o:进一步指定所执行的操作,例如插入。
2、同步
(1)、从节点首次启动时,做完整同步;
(2)、主节点数据发生变化时,做增量同步;
(3)、从节点与主节点数据严重不一致时,做完整同步。
六、复制管理
1、诊断
(1)、当连接上主节点后,可以使用db.printReplicationInfo(),查看oplog的大小和oplog中操作的时间范围。
(2)、当连接上从节点后,可以使用db.printSlaveReplicationInfo(),查看从节点的数据源列表、同步延迟时间等信息。
2、变更oplog的容量
在主节点上使用:
(1)、设定oplogSize参数;
(2)、重启MongoDB数据库;
3、复制认证
主从节点皆须配置:
(1)、存储在local.system.users;
(2)、优先尝试repl用户;
(3)、主从节点的用户配置必须保持一致。
本文出自 “成长的记忆录” 博客,请务必保留此出处http://zhanyah.blog.51cto.com/2821907/1270518
一、主从集群简介
高可用性通常描述一个系统经过专门的设计,从而减少停工时间。
保存其服务的高度连续可用性,MongoDB提供的主从复制机制保证了多个数据库的数据同步,这对实现数据库的容灾、备份、恢复、负载均衡都是有极大的帮助.
主从复制的优点:
从服务器可以执行查询工作,降低主服务器访问压力;
在从服务器执行备份,避免备份期间锁定主服务器的数据;
当主服务器出现故障时,可以快速切换到从服务器,减少当机时间;
MongoDB支持在多个机器中通过异步复制到底故障转移和实现冗余,多台机器中同一时刻只有一台是用于写操作,
这为mongoDB提供了数据一致性的保障.担当Primary角色的机器能把读操作分发给slave机器。
MongoDB的主从集群分为两种:
Master-Slave 复制(主从复制)
Replica Sets 复制(副本集)
主服务器支持增删该,从服务器主要支持读.
Master-Slave(主从复制):
只需要在某一个服务启动时加上-master参数,以指明此服务器的角色是primary,
而另一个服务加上-slave与-source参数,以指明此服务器的角色是slave. 即可实现同步。
MongoDB的最新版本已经不推荐使用这种方法了。
Replica Sets 复制(副本集):
MongoDB在1.6版本开发了replica set,主要增加了故障自动切换和自动修复成员节点。
各个DB之间数据完全一致,最为显著的区别在于:
副本集没有固定的主节点,它是整个集群选举得出的一个主节点,当其不工作时变更其它节点。
二、主从复制(Master-Slave)
1、概念:主从复制是一个简单的数据库同步备份的集群技术。简单结构,如下图所示:
(1)、在数据库集群中要明确的知道谁是主服务器,主服务器只有一台。
(2)、从服务器要知道自己的数据源,也就是对于自己的主服务器是谁。
(3)、--master用来确定主服务器,--slave来控制从服务器, --source确定从服务的数据源。
2、主从复制集群案例
主服务器:1111
参数配置:
dbpath=D:\Work\MongoDB\Data\1111 #主数据库地址
bind_ip=127.0.0.1 #主数据库所在服务器IP
port=1111 #主数据库端口号
master=true #确定主服务器
从服务器:2222
参数配置:
dbpath=D:\Work\MongoDB\Data\2222 #从数据库地址
bind_ip=127.0.0.1 #从数据库所在服务器IP
port=2222 #从数据库端口号
source=127.0.0.1:1111 #主数据的服务器IP和端口
#这个配置项(source),可以用shell动态添加
slave=true #确定从服务器
3、主从复制选项
--only 从节点->指定复制某个数据库,默认是复制全部数据库;
--slavedelay 从节点->设置主数据库同步数据的延迟时间,单位为秒;
--fastsync 从节点->以主数据库的节点快照为节点,启动从数据库;
--oplogSize 主节点->设置oplog的大小(主节点操作记录,存储在local数据库的oplog中);
4、利用shell动态添加和删除从节点
示例:
> use local
switched to db local
> db.sources.find()
{ "host" : "127.0.0.1:1111", "source" : "main", "syncedTo" : { "t" : 1376132657, "i" : 1 } }
从上面的示例中,不难看出从节点中关于主节点的信息,全部存储到local数据库的sources集合中。
我们只要对sources集合进行操作,就可以动态操作主从关系。
(1)添加数据源
db.sources.insert({"host":"127.0.0.1:1111"})
(2)删除数据源
db.sources.remove({"host":"127.0.0.1:1111"})
三、副本集(Replica Sets)
1、概念:副本集就是具有自动故障恢复功能的主从集群(俗称"故障转移集群")。简单结构,
如下图所示:
1.1、第一张图表明A是活跃的,B和C是用于备份的;
1.2、第二张图表明当A出现了故障,这时候集群根据权重算法,推选出B为活跃的数据库;
1.3、第三张图表明当A恢复后,它自动又会变为备份数据库。
2、特点:
(1)、与普通主从复制集群相比,具有自动检测机制;
(2)、需要使用--replset选项指定副本同伴;
(3)、任何时候,副本集当中只允许有一个活跃节点。
3、副本集案例:
A服务器:1111
参数配置:
dbpath=D:\Work\MongoDB\Data\replset\1111 #数据库地址
bind_ip=127.0.0.1 #数据库所在服务器IP
port=1111 #数据库端口号
replSet=child/127.0.0.1:2222 #设定同伴
B服务器:2222
参数配置:
dbpath=D:\Work\MongoDB\Data\replset\2222 #数据库地址
bind_ip=127.0.0.1 #数据库所在服务器IP
port=2222 #数据库端口号
replSet=child/127.0.0.1:3333 #设定同伴
C服务器:3333
参数配置:
dbpath=D:\Work\MongoDB\Data\replset\3333 #数据库地址
bind_ip=127.0.0.1 #数据库所在服务器IP
port=3333 #数据库端口号
replSet=child/127.0.0.1:1111 #设定同伴s
4、初始化副本集
use admin;
db.runCommand({"replSetInitiate":
{
"_id":"child",#副本集名称
"members":[{
"_id":1, #服务器唯一ID(必须为数字)
"host":"127.0.0.1:1111" #服务器主机地址
},{
"_id":2,
"host":"127.0.0.1:2222"
},{
"_id":3,
"host":"127.0.0.1:3333"
}]
}
});
初始化副本集的结果:
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}
5、查看副本集状态
rs.status();#查看副本集所有服务器状态。
rs.isMaster();#查看副本集中当前服务器状态。
6、查看主从配置信息
在local库中不仅有主从日志oplog.rs,还有一个集合用于记录主从配置信息system.replset。
通过执行”db.system.replset.find()”命令查看复制集的配置信息,查询结果如下所示:
child:PRIMARY> use local
switched to db local
child:PRIMARY> db.system.replset.find()
{
"_id" : "child", "version" : 1,
"members" : [
{ "_id" : 1, "host" : "127.0.0.1:11111" },
{ "_id" : 2, "host" : "127.0.0.1:2222" },
{ "_id" : 3, "host" : "127.0.0.1:3333" }
]
}
7、副本集中的节点类型
standard->常规节点:参与投票有可能成为活跃节点。
passive->副本节点:参与投票,但是不能成为活跃节点。
arbiter->仲裁节点:只是参与投票,不复制节点,也不能成为活跃节点。
8、初始化高级参数
priority:0到1000之间,0代表是副本节点,1到1000是常规节点;
通过这个我们可以指明副本集某台服务器节点初始为活跃节点。
arbiterOnly:true,仲裁节点;特定指明某个服务器节点为仲裁节点,仲裁节点不会复制数据,不会成为活跃节点;
其存在的目的只有一个:当前活跃节点失效后,副本集内重新投票选活跃节点时,防止出现僵局!
9、故障切换和活跃点选举
当前活跃节点失效,包括两种情况:
(1)当前活跃节点宕机或本身异常。
(2)当前活跃节点会通过心跳跟踪集群中多少节点对其可见,如果数量小于集群服务器数量的一半,会自动降级为备份节点。
此时,集群会投票选举出一个新的活跃节点(新比较优先级,优先级相同的,各个节点判断哪个数据最新,就会投哪个)。
任何时候,活跃节点的数据会被认为是最新的,当重新确定了活跃节点后,所有其他节点都要重新进行完整同步(数据可能发生回滚)。
四、在服务器上执行操作
1、读写分离(扩展读)
一般情况下,作为副本的节点是不能进行数据库读操作的,但是在读取密集型的系统中,读写分离是十分必要的。
2、设置读写分离
slaveOkay:true
3、读写分离的特点:
(1)、将密集的读取操作分流到从节点上,降低主节点的负载。
(2)、默认情况下,从节点是不允许处理客户端请求的,需要使用--slaveOkay打开。
(3)、不适用于实时性要求非常高的应用。
五、工作原理
1、oplog
oplog保存在local数据库中,oplog就在其中的oplog.$main集合内保存。该集合的每个文档都记录了主节点上执行的一个操作,其键定义如下:
ts:操作时间戳,占用4字符;
op:操作类型,占用2个字节;
ns:操作对象的命名空间(或理解为集合全名);
O:
o:进一步指定所执行的操作,例如插入。
2、同步
(1)、从节点首次启动时,做完整同步;
(2)、主节点数据发生变化时,做增量同步;
(3)、从节点与主节点数据严重不一致时,做完整同步。
六、复制管理
1、诊断
(1)、当连接上主节点后,可以使用db.printReplicationInfo(),查看oplog的大小和oplog中操作的时间范围。
(2)、当连接上从节点后,可以使用db.printSlaveReplicationInfo(),查看从节点的数据源列表、同步延迟时间等信息。
2、变更oplog的容量
在主节点上使用:
(1)、设定oplogSize参数;
(2)、重启MongoDB数据库;
3、复制认证
主从节点皆须配置:
(1)、存储在local.system.users;
(2)、优先尝试repl用户;
(3)、主从节点的用户配置必须保持一致。
本文出自 “成长的记忆录” 博客,请务必保留此出处http://zhanyah.blog.51cto.com/2821907/1270518

相关文章推荐
- 小心服务器内存居高不下的元凶--WebAPI服务
- 分享微信开发Html5轻游戏中的几个坑
- Android之获取手机上的图片和视频缩略图thumbnails
- 如何在 Fedora 上安装 MongoDB 服务器
- 运维入门
- PHP添加yaf xhprof mongodb 同理
- mongodb安装
- 数据库链接字符串查询网站
- 如何在 Ubuntu 上安装 MongoDB
- RedHat 5.8 安装Oracle 11gR2_Grid集群
- DB2实例管理
- DB2实例管理
- mysql集群之MMM简单搭建
- 利用开源软件打造自己的全功能远程工具
- Linux5.9无人值守安装
- 数据中心和云未来的十二大趋势
- 保障MySQL数据安全的14个最佳方法