forkjoin并发框架—需求背景和设计原理
2016-05-14 12:50
651 查看
1. Fork Join 的设计简介
看过《Introduction to Algorithms》(《算法导论》)的朋友们应该还记得,在讲到归并排序(Merge Sort)和快速排序的时候,有一种很简单又很有效率的思路就是“分而治之”,即“分治法”。而Fork Join的思路也是同理,只不过划分之后的任务更适合分派给不同的计算资源,可以并行的完成任务。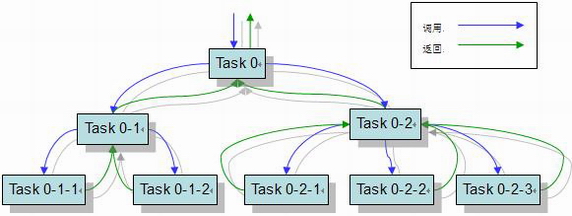
当计算分别完成之后,最后再合并回来。
简单来看,就是一个递归的分解和合并,直到任务小到可以接受的程度。
2. Fork Join 设计要点
Fork Join设计出来就是为了提高任务完成的效率,围绕这个目标,有一些要点是设计中需要考虑的,下面就给出一些要点。线程的管理和线程的单纯性。基于如上的设计思路,我们可以看到子任务之间的相关性是相对比较简单的,可以并行处理。为了提高效率,并不需要重量级的线程结构和对应的线程维护,线程实现简单就好,满足需求即可,降低维护成本。
队列机制,硬件支持一定是比较有限的,那么分解的任务应该用队列维护起来,一个好的队列设计是很有必要的。
“工作窃取”,也就是设计论文原文中提到的 Work Stealing 。对于负载比较轻的线程,可以帮助负载较重的执行线程分担任务。
对于使用Fork Join的开发者来讲,需要注意:
可用线程数和硬件支持。线程这东西,也是有开销的东西,绝对不是越多越好,尤其在硬件基础有限的情况下。
任务分解的粒度。和前者有关系,就是分解的任务,“小”到什么程度是可以接受的,不可再分。
3. Fork Join数据结构支持
按照如上设计,分解执行一个大的任务,Fork Join至少需要考虑如下一些数据结构。轻量级的线程结构。
维护线程的线程池,负责线程的创建,数量维护和任务管理。维护任务,并支持Work Stealing的双端队列。
如下图。
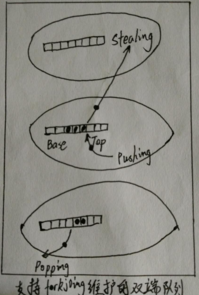
对于子任务的分解,可以从base端取出分解再放入,而对于WorkStealing则可以从top端取出,放入其他队列的尾部。
原文链接

相关文章推荐
- 一步一步跟我学易语言之第二个易程序菜单设计
- 插件管理框架 for Delphi(一)
- 基于逻辑运算的简单权限系统(原理,设计,实现) VBS 版
- 使用CSS框架布局的缺点和优点小结
- C#中设计、使用Fluent API
- 一起动手编写Android图片加载框架
- 基于.NET平台常用的框架和开源程序整理
- 探究在C++程序并发时保护共享数据的问题
- 基于逻辑运算的简单权限系统(原理,设计,实现) VBS 版
- 列举PHP的Yii 2框架的开发优势
- 在ASP.NET 2.0中操作数据之二十一:实现开放式并发
- Windows窗体的.Net框架绘图技术实现方法
- 浅谈JavaScript 框架分类
- 轻量级javascript 框架Backbone使用指南
- javascript实现框架高度随内容改变的方法
- JS刷新框架外页面七种实现代码
- 超赞的动手创建JavaScript框架的详细教程
- 深入探讨前端框架react
- Nodejs实战心得之eventproxy模块控制并发
- JavaScript设计模式初探