基于内积法的Hadoop的MapReducer框架实现稀疏矩阵乘法(java)
2016-05-13 00:00
555 查看
摘要: 博主现在仅仅处于初研究阶段,若有错误望指正,不说其他的,直接给大家来点干货!
1、构建两个矩阵,此处写定,如下:
A={{1, 2, 3},{4, 5, 0},{7, 8, 9},{10, 11, 12}};
B={{13, 14},{0, 16},{17, 0}};
2、将矩阵转换成(row, col, value)形式存于文本中,其中row为行号,col为列号,同时只存储有效数据,即0不存储
private static void util(String fileName, int[][] arg){
try {
File file = new File(fileName);
if (!file.exists()) {
file.createNewFile();
}
System.out.println(arg[0].length + ", " + arg.length);
FileWriter fw = new FileWriter(file);
int i=0, j=0;
for (i = 0; i < arg.length; i++) {
for (j = 0; j < arg[0].length-1; j++) {
System.out.print(arg[i][j] + ", ");
if(arg[i][j]!=0){
fw.write((i+1)+" "+(j+1)+" "+arg[i][j]+"\n");
}
}
System.out.println(arg[i][j]);
if(arg[i][j]!=0){
fw.write((i+1)+" "+(j+1)+" "+arg[i][j]+"\n");
}
}
fw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
private static void getATxt(){
util("matrixA.txt", A);
}
private static void getBTxt(){
util("matrixB.txt", B);
}
public static void main(String[] args) {
getATxt();
getBTxt();
}
3、生成的 matrixA.txt 和 matrixB.txt 结果及格式如下

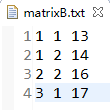
4、在实现稀疏矩阵乘法之前,首先要了解MapReducer原理
在Map阶段,根据传入的文本数据,本次中为 m x j 的A矩阵和 j x n 的B矩阵通过A的行的每一位元素和B的列的对应每一位元素相乘的和,最后将得到一个 m x n 的C矩阵,故A的行或B的列作为outputValue,而Reducer阶段是根据outputKey相同自动将其分组形成一个list,故写入Reducer阶段的key应该相同,所以选择c的行号和列号,outputValue根据文件不同,区别是A的行还是B的列,故需加上标识。
在Reducer阶段,分割InputValue,根据标识不同,取出值并存入相应数据,最后实现对应位相乘然后相加得到c并输出到文件。
5、代码实现前推荐一个好方法,可以获取具体文件名,可根据文件名不同加上不同的标识
String pathName = ((FileSplit)context.getInputSplit()).getPath().toString();
6、具体代码实现
public class MatirxMult {
private static final int[][] A={{1, 2, 3},{4, 5, 0},{7, 8, 9},{10, 11, 12}};
private static final int[][] B={{13, 14},{0, 16},{17, 0}};
private static final int rowSizeA = A.length;//获取A的行数
private static final int colSizeA = A[0].length;//获取A的列数
private static final int colSizeB = B[0].length;//获取B的列数
private static class MatirxMultMapper extends Mapper<LongWritable, Text, Text, Text>{
private static int i=0;
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
//可以获取文件名,根据文件名来判定传入reducer的形式
String pathName = ((FileSplit)context.getInputSplit()).getPath().toString();
//strs[0]行值;strs[0]列值;strs[2]值
String[] strs = value.toString().split(" ");
if(pathName.contains("matrixA")){
for(i=0; i<colSizeB; i++){
context.write(new Text(strs[0]+":"+(i+1)), new Text(strs[1]+":"+strs[2]+":A"));
}
}else if(pathName.contains("matrixB")){
for(i=0; i<rowSizeA; i++){
context.write(new Text((i+1)+":"+strs[1]), new Text(strs[0]+":"+strs[2]+":B"));
}
}
}
}
private static class MatirxMultReducer extends Reducer<Text, Text, Text, IntWritable>{
@Override
protected void reduce(Text value, Iterable<Text> datas,
Reducer<Text, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String[] strsValue = value.toString().split(":");
int colA=0, rowB=0, valueA=0, valueB=0;
int[] vA = new int[colSizeA];//因为A对应行和B对应列必须为A的列数等于B的行数
int[] vB = new int[colSizeA];
for(Text data : datas){
String[] strs = data.toString().split(":");
if("A".equals(strs[2])){
colA = Integer.parseInt(strs[0]);
valueA = Integer.parseInt(strs[1]);
vA[colA-1] = valueA;//因为存文件的时候下标是从1开始,而数组下标从0开始,故需-1
}else if("B".equals(strs[2])){
rowB = Integer.parseInt(strs[0]);
valueB = Integer.parseInt(strs[1]);
vB[rowB-1] = valueB;
}
}
int result=0;
for(int j=0; j<colSizeA; j++){
result+=vA[j]*vB[j];
}
//C=AB, strsValue[0]为C的行号,strsValue[1]为C的列号,result位C的具体位置结果
context.write(new Text(strsValue[0]+":"+strsValue[1]), new IntWritable(result));
}
}
public static void main(String[] args) {
try {
Configuration cfg = HadoopCfg.getConfigration();
Job job = Job.getInstance(cfg);
job.setJobName("MatirxMult");
job.setJarByClass(MatirxMult.class);
job.setMapperClass(MatirxMultMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(MatirxMultReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/input/matrix"));
FileOutputFormat.setOutputPath(job, new Path("/MatirxMult/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
7、结果展示(格式为:坐标,值)

写在最后:如有疑问可以提出,谢谢。博主是看了一篇论文,但是只取了其中一小部分实现。
论文名称:基于Hadoop的大矩阵乘法处理方法(孙远帅)
1、构建两个矩阵,此处写定,如下:
A={{1, 2, 3},{4, 5, 0},{7, 8, 9},{10, 11, 12}};
B={{13, 14},{0, 16},{17, 0}};
2、将矩阵转换成(row, col, value)形式存于文本中,其中row为行号,col为列号,同时只存储有效数据,即0不存储
private static void util(String fileName, int[][] arg){
try {
File file = new File(fileName);
if (!file.exists()) {
file.createNewFile();
}
System.out.println(arg[0].length + ", " + arg.length);
FileWriter fw = new FileWriter(file);
int i=0, j=0;
for (i = 0; i < arg.length; i++) {
for (j = 0; j < arg[0].length-1; j++) {
System.out.print(arg[i][j] + ", ");
if(arg[i][j]!=0){
fw.write((i+1)+" "+(j+1)+" "+arg[i][j]+"\n");
}
}
System.out.println(arg[i][j]);
if(arg[i][j]!=0){
fw.write((i+1)+" "+(j+1)+" "+arg[i][j]+"\n");
}
}
fw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
private static void getATxt(){
util("matrixA.txt", A);
}
private static void getBTxt(){
util("matrixB.txt", B);
}
public static void main(String[] args) {
getATxt();
getBTxt();
}
3、生成的 matrixA.txt 和 matrixB.txt 结果及格式如下
4、在实现稀疏矩阵乘法之前,首先要了解MapReducer原理
在Map阶段,根据传入的文本数据,本次中为 m x j 的A矩阵和 j x n 的B矩阵通过A的行的每一位元素和B的列的对应每一位元素相乘的和,最后将得到一个 m x n 的C矩阵,故A的行或B的列作为outputValue,而Reducer阶段是根据outputKey相同自动将其分组形成一个list,故写入Reducer阶段的key应该相同,所以选择c的行号和列号,outputValue根据文件不同,区别是A的行还是B的列,故需加上标识。
在Reducer阶段,分割InputValue,根据标识不同,取出值并存入相应数据,最后实现对应位相乘然后相加得到c并输出到文件。
5、代码实现前推荐一个好方法,可以获取具体文件名,可根据文件名不同加上不同的标识
String pathName = ((FileSplit)context.getInputSplit()).getPath().toString();
6、具体代码实现
public class MatirxMult {
private static final int[][] A={{1, 2, 3},{4, 5, 0},{7, 8, 9},{10, 11, 12}};
private static final int[][] B={{13, 14},{0, 16},{17, 0}};
private static final int rowSizeA = A.length;//获取A的行数
private static final int colSizeA = A[0].length;//获取A的列数
private static final int colSizeB = B[0].length;//获取B的列数
private static class MatirxMultMapper extends Mapper<LongWritable, Text, Text, Text>{
private static int i=0;
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
//可以获取文件名,根据文件名来判定传入reducer的形式
String pathName = ((FileSplit)context.getInputSplit()).getPath().toString();
//strs[0]行值;strs[0]列值;strs[2]值
String[] strs = value.toString().split(" ");
if(pathName.contains("matrixA")){
for(i=0; i<colSizeB; i++){
context.write(new Text(strs[0]+":"+(i+1)), new Text(strs[1]+":"+strs[2]+":A"));
}
}else if(pathName.contains("matrixB")){
for(i=0; i<rowSizeA; i++){
context.write(new Text((i+1)+":"+strs[1]), new Text(strs[0]+":"+strs[2]+":B"));
}
}
}
}
private static class MatirxMultReducer extends Reducer<Text, Text, Text, IntWritable>{
@Override
protected void reduce(Text value, Iterable<Text> datas,
Reducer<Text, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String[] strsValue = value.toString().split(":");
int colA=0, rowB=0, valueA=0, valueB=0;
int[] vA = new int[colSizeA];//因为A对应行和B对应列必须为A的列数等于B的行数
int[] vB = new int[colSizeA];
for(Text data : datas){
String[] strs = data.toString().split(":");
if("A".equals(strs[2])){
colA = Integer.parseInt(strs[0]);
valueA = Integer.parseInt(strs[1]);
vA[colA-1] = valueA;//因为存文件的时候下标是从1开始,而数组下标从0开始,故需-1
}else if("B".equals(strs[2])){
rowB = Integer.parseInt(strs[0]);
valueB = Integer.parseInt(strs[1]);
vB[rowB-1] = valueB;
}
}
int result=0;
for(int j=0; j<colSizeA; j++){
result+=vA[j]*vB[j];
}
//C=AB, strsValue[0]为C的行号,strsValue[1]为C的列号,result位C的具体位置结果
context.write(new Text(strsValue[0]+":"+strsValue[1]), new IntWritable(result));
}
}
public static void main(String[] args) {
try {
Configuration cfg = HadoopCfg.getConfigration();
Job job = Job.getInstance(cfg);
job.setJobName("MatirxMult");
job.setJarByClass(MatirxMult.class);
job.setMapperClass(MatirxMultMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(MatirxMultReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/input/matrix"));
FileOutputFormat.setOutputPath(job, new Path("/MatirxMult/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
7、结果展示(格式为:坐标,值)
写在最后:如有疑问可以提出,谢谢。博主是看了一篇论文,但是只取了其中一小部分实现。
论文名称:基于Hadoop的大矩阵乘法处理方法(孙远帅)

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 单机版搭建Hadoop环境图文教程详解
- C中实现矩阵乘法的一种高效的方法
- hadoop常见错误以及处理方法详解
- java 二维数组矩阵乘法的实现方法
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍
- Hadoop单机版和全分布式(集群)安装
- 用PHP和Shell写Hadoop的MapReduce程序
- hadoop map-reduce中的文件并发操作
- Hadoop1.2中配置伪分布式的实例
- hadoop上传文件功能实例代码
- java结合HADOOP集群文件上传下载