spring源码剖析(七)JdbcTemplate数据库封装原理解读
2016-05-12 00:36
453 查看
前言
写这个之前我一直在想,阅读spring对数据库操作的封装的操作原理还有意义么,hibernate和mybatis不是比JdbcTemplate封装的更好使用更加简单么,为什么我们还要阅读JdbcTemplate相关的操作原理呢,要读去读mybatis或者hibernate的源代码岂不是更好。其实,如果能去读mybatis或者hibernate的源代码也好,但是对于spring那么完美的框架,我不愿意放过任意一个作者精心设计的功能,我们虽然不常用到JdbcTemplate,难道我们就因此不去发现另一个美妙的设计?我认为阅读研究这一部分的源代码还是蛮有必要的,最起码我可以从中体会到作者的设计思想,或许以后,我可以从他的设计中得到启发,亦或者升华自己的设计理念。so,让我们一块来开始揭开spring对数据库操作封装的神秘面纱把。
数据库操作一般流程
下面以连接操作mysql数据库为例,简单说明不使用框架的情况下,操作的数据库的一般流程,相信大家也都敲过千百遍了,我就简单描述下流程吧1)java程序中加载驱动程序。一般使用Class.forName这种反射的方法加载数据库的驱动。
2)创建数据连接对象。通过DriverManager的getConnection方法,输入数据库连接的URL,用户名,密码等信息,连接数据库,获取连接对象Connection 的实例
3)创建Statement(PreparedStatement)。通过数据库的连接对象可以创建Statement(PreparedStatement)对象实例,Statement(PreparedStatement)对象实例可以执行静态SQL并返回生成结果对象。
4)调用Statement(PreparedStatemen)t实例相关方法执行相应的SQL语句。Statement(PreparedStatement)的实例有很多数据库的操作方法,如通过executeQuery方法可以执行数据的查询,并可以得到返回的结果集ResultSet
5)关闭数据库连接。在使用完数据库之后,或者不需要再使用数据库的时候,可以通过Connection的close方法,关闭数据库的连接。
spring操作数据库流程
spring中的jdbc连接与直接使用jdbc去连接还是有所差别的,Spring对jdbc做了大量的封装,消除了冗余的代码,大大减少了开发量,下面先上一个简单的例子让大家回顾下spring的jdbc操作流程spring的Jdbc操作示例
创建数据库表(person)
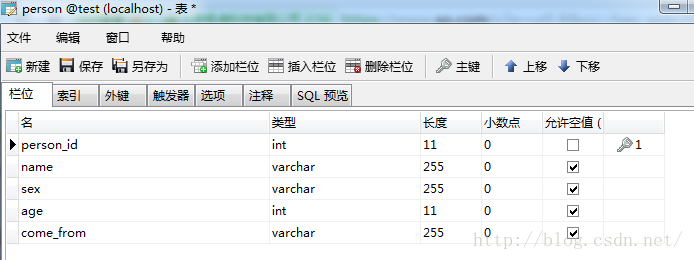
创建数据库表对应的po类
/**
*
* @author Fighter168
*/
public class Person {
private String personId;
private String name;
private String sex;
private int age;
private String comeFrom;
//省略set get方法
}创建表与实体之间的映射
/**
*
* @author Fighter168
*/
public class PersonRowMapper implements RowMapper<Person>{
/* (non-Javadoc)
* @see org.springframework.jdbc.core.RowMapper#mapRow(java.sql.ResultSet, int)
*/
@Override
public Person mapRow(ResultSet rs, int rowNum) throws SQLException {
Person person=new Person();
person.setAge(rs.getInt("age"));
person.setComeFrom(rs.getString("come_from"));
person.setName(rs.getString("name"));
person.setPersonId(rs.getString("person_id"));
person.setSex(rs.getString("sex"));
return person;
}
}创建数据库操作接口
/**
*
* @author Fighter168
*/
public interface PersonService {
public void save(Person person);
public List<Person> getPersons();
}创建数据库操作接口的实现类
/**
*
* @author Fighter168
*/
public class PersonServiceImpl implements PersonService {
private JdbcTemplate jdbcTemplate;
public void setJdbcTemplate(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public void save(Person p) {
jdbcTemplate.update("insert in to person(person_id,name,age,sex,come_from) values(?,?,?,?,?)",
new Object[]{p.getPersonId(),p.getName(),p.getAge(),p.getSex(),p.getComeFrom()},
new int[]{Types.VARCHAR,Types.VARCHAR,Types.INTEGER,Types.VARCHAR,Types.VARCHAR});
}
public List<Person> getPersons(){
List<Person> list=jdbcTemplate.query("select * from person", new PersonRowMapper());
return list;
}
}创建spring配置文件
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd"> <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"> <property name="driverClassName" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/test"/> <property name="username" value="root"/> <property name="password" value="123abc"/> <!-- 连接池启动时候的初始连接数 --> <property name="initialSize" value="10"/> <!-- 最小空闲值 --> <property name="minIdle" value="5"/> <!-- 最大空闲值 --> <property name="maxIdle" value="20"/> <property name="maxWait" value="2000"/> <!-- 连接池最大值 --> <property name="maxActive" value="50"/> <property name="logAbandoned" value="true"/> <property name="removeAbandoned" value="true"/> <property name="removeAbandonedTimeout" value="180"/> </bean> <!-- 配置业务bean --> <bean id="personService" class="net.itaem.service.PersonServiceImpl"> <!-- 向dataSource注入数据源 --> <property name="jdbcTemplate" ref="dataSource"/> </bean> </beans>
测试
/**
*
* @author Fighter168
*/
public class JdbcTest {
public static void main(String[] args) {
ApplicationContext context=new ClassPathXmlApplicationContext("net/itaem/source/bean.xml");
PersonService service=(PersonService) context.getBean("personService");
System.out.println(service.getPersons().size());
}
}jdbctemp的其他用法就不多说了,比较简单,大家都了解,那么我们就借着这个示例看看里面执行的源码原理吧。
JdbcTemplate的query方法
时序图
首先我们来看看query方法执行的时序图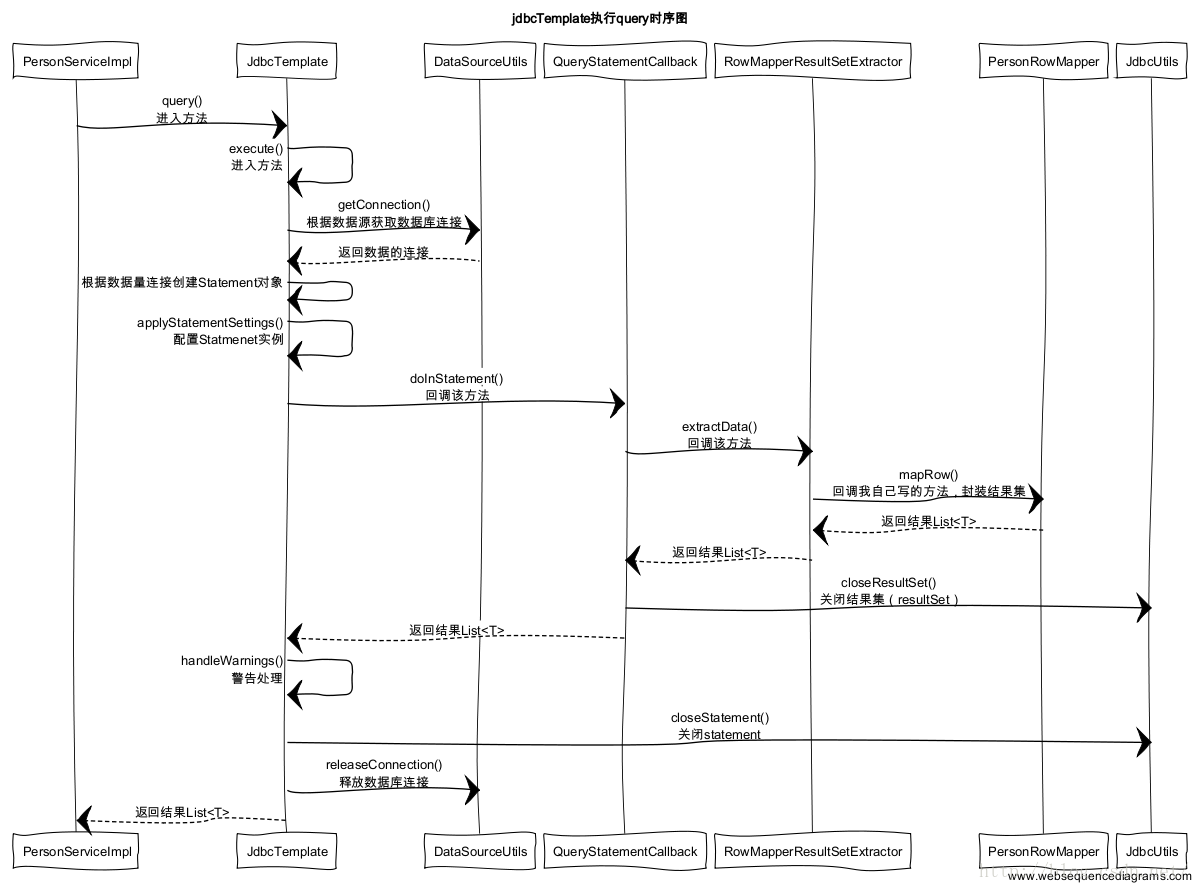
重要步骤说明
首先是从PersonServiceImpl方法进去,调用JdbcTemplate的query方法,然后执行一连串错中复杂的调用,而且里面有很多函数都是以回调形式处理,由此可以知道,代理模式在spring是多么的常用。接下来让我来看一些重要的细节的逻辑把。1)JdbcTemplate接受到query请求,由于query没有带参数,所以选择不带sql参数的重载方法query执行。
2)query方法面会创建一个内部类(QueryStatementCallback),然后实例化,传给execute方法,等待execute回调,这里使用了代理设计模式,让我们看看这个query的详细实现
public <T> T query(final String sql, final ResultSetExtractor<T> rse) throws DataAccessException {
Assert.notNull(sql, "SQL must not be null");
Assert.notNull(rse, "ResultSetExtractor must not be null");
if (logger.isDebugEnabled()) {
logger.debug("Executing SQL query [" + sql + "]");
}
class QueryStatementCallback implements StatementCallback<T>, SqlProvider {
public T doInStatement(Statement stmt) throws SQLException {
ResultSet rs = null;
try {
rs = stmt.executeQuery(sql);
ResultSet rsToUse = rs;
if (nativeJdbcExtractor != null) {
rsToUse = nativeJdbcExtractor.getNativeResultSet(rs);
}
//先进入RowMapperResultSetExtractor的回调函数,然后再回调PersonRowMapper的 mapRow方法
return rse.extractData(rsToUse);
}
finally {
JdbcUtils.closeResultSet(rs);
}
}
public String getSql() {
return sql;
}
}
return execute(new QueryStatementCallback());
}3)很明显,上面是传了一个callback对象的实例进入execute,其实execute也是JdbcTemplate的核心方法,虽然execute有很多重载方法,但是他们的核心逻辑其实没什么特别大的差别,那么就让我先看看执行query方法所调用的execute方法的源码把.
//-------------------------------------------------------------------------
// Methods dealing with static SQL (java.sql.Statement)
//-------------------------------------------------------------------------
public <T> T execute(StatementCallback<T> action) throws DataAccessException {
Assert.notNull(action, "Callback object must not be null");
//创建数据库连接
Connection con = DataSourceUtils.getConnection(getDataSource());
Statement stmt = null;
try {
Connection conToUse = con;
if (this.nativeJdbcExtractor != null &&
this.nativeJdbcExtractor.isNativeConnectionNecessaryForNativeStatements()) {
conToUse = this.nativeJdbcExtractor.getNativeConnection(con);
}
stmt = conToUse.createStatement();
//应用用户输入的参数
applyStatementSettings(stmt);
Statement stmtToUse = stmt;
if (this.nativeJdbcExtractor != null) {
stmtToUse = this.nativeJdbcExtractor.getNativeStatement(stmt);
}
//回调QueryStatementCallback的doInStatement方法,然后doStatement方法里面又回调PersonRowMapper类的rowMap方法,
//rowMap取得每一行的信息封装成Person对象返回,一直返回,知道返回到这里的result
T result = action.doInStatement(stmtToUse);
//警告处理
handleWarnings(stmt);
return result;
}
catch (SQLException ex) {
// 发生异常时候释放资源
JdbcUtils.closeStatement(stmt);
stmt = null;
DataSourceUtils.releaseConnection(con, getDataSource());
con = null;
throw getExceptionTranslator().translate("StatementCallback", getSql(action), ex);
}
finally {
//释放Statement
JdbcUtils.closeStatement(stmt);
//释放Connection
DataSourceUtils.releaseConnection(con, getDataSource());
}
}具体的核心逻辑,上面注释也写比较清晰,我就不重复诉说了。4)获取到List对象后,就直接退出execute方法,逐步返回result,知道返回给最初的调用者(ok,query方法实现完毕!)
JdbcTemplate的update方法
时序图
接下来我们看看update/save方法的具体实现吧,首先,我们还是先上时序图,清晰一点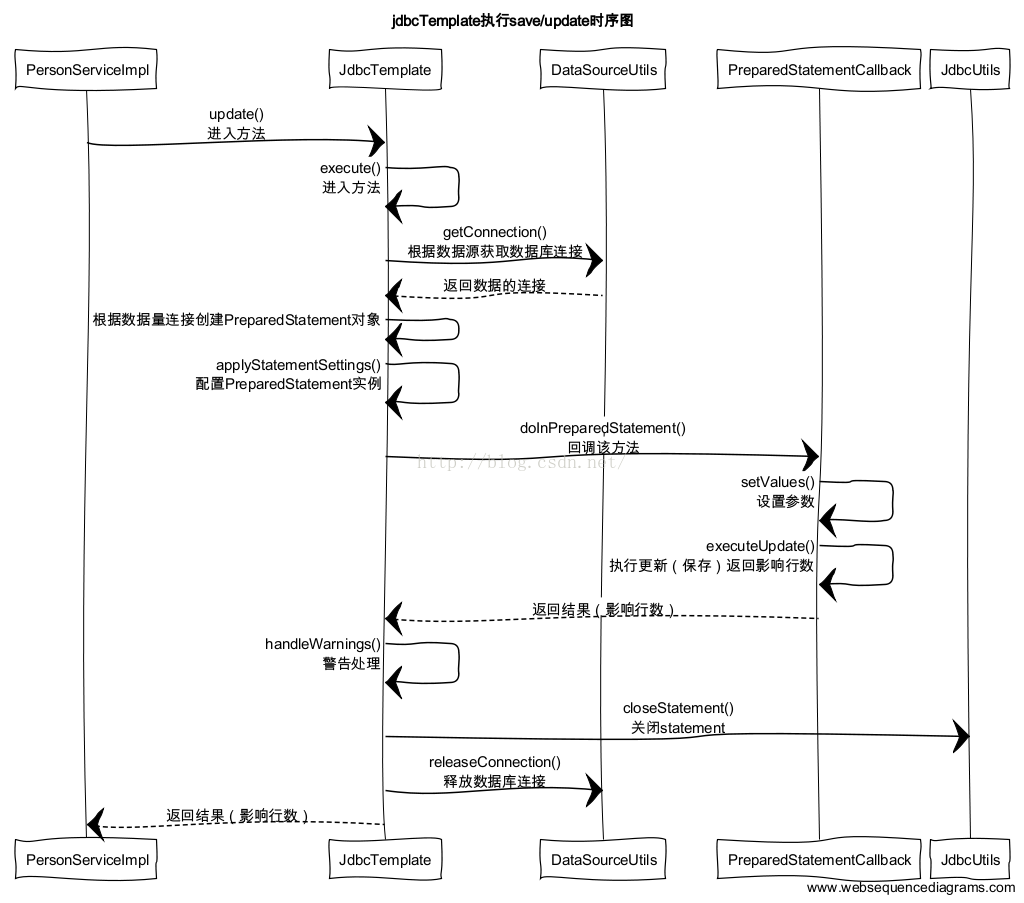
此时我们会发现,咦,这调用的时序怎么好像和query的有点类似。其实,他们的核心逻辑还是差不多的,都是先获取数据源,创建PreparedStatement或者Statement,然后调用各种的回调函数,给各种的CallBack去处理,处理完成之后便释放资源,返回结果。
所以,JdbcTemplate核心操作数据库的逻辑其实都是差不多的,但是针对于不同的方法,例如query,或者update他们分别有不同的CallBack传给execute方法去执行,然后execute方法回调各自的回调方法,执行完毕后再传给execute方法,等待execute方法释放完资源后便逐步返回结果给调用者。
由于其他方法,类似queryForObject,还有batchUpdate等等这些方法的处理逻辑类似,所以在此便不再说明了。
小结
spring的JdbcTemplate用起来其实还是比较好用的,起码对原始的jdbc操作已经封装的很好了,尤其是设计里面代理模式的完美应用,各种callback。虽说我们现在做项目都是使用mybatis或者hibernate这种ORM框架的居多,但是偶尔我们还是需要返璞归真一下,去探究底层的实现原理,加深自己的理解,提高自己的水平。
相关文章推荐
- struts2(十一)运行流程
- Quartz使用-入门使用(java定时任务实现)
- java基础第六天_接口与适配器模式、多态、内部类
- java基础第六天_接口与适配器模式、多态、内部类
- java中有那些关键字?
- [Java] 基础命令
- java运算符中值的注意的地方
- JAVA回调机制(CallBack)详解
- 详解java定时任务
- Eclipse快捷键
- 用Java获取vSphere相关数据
- Java连接MySQL
- Java接受控制台的值
- C#和Java打开文件
- java异常 try-catch 和throw
- Java 正则表达式从入门到“跑路”
- Java中的异常处理
- Spring (依赖注入)
- Spring+SpringMVC+MyBatis+Maven框架整合
- java annotation