数据结构:链表(linked-list)
2016-05-09 11:09
776 查看
在讨论链表(linked-list)之前,需要明确几个概念:线性表(顺序表, list, linear list), 数组(array),链表(linked-list)。
线性表:在中文里,线性表也叫作顺序表。在英文中,它称为list, linear list等。它是最基础、最简单、最常用的一种基本数据结构,线性表总存储的每个数据称为一个元素,各个元素及其索引是一一对应的关系。线性表有两种存储方式:顺序存储方式和链式存储方式。
数组(array):数组就是线性表的顺序存储方式。数组的内存是连续分配的,并且是静态分配的,即在使用数组之前需要分配固定大小的空间。可以通过索引直接得到数组中的而元素,即获取数组中元素的时间复杂度为O(1)。
链表(linked-list):链表就是线性表的链式存储方式。链表的内存是不连续的,前一个元素存储地址的下一个地址中存储的不一定是下一个元素。链表通过一个指向下一个元素地址的引用将链表中的元素串起来。

来源:http://i.stack.imgur.com/puPVJ.jpg
其实为了简便,通常我们也直接将list看做是链表。但是也不必太过纠结这种名称定义,更重要的还是关注数据结构的实现。
The thing and the name of the thing are two different things - Richard Feynman

来源:https://upload.wikimedia.org/wikipedia/commons/4/45/Link_zh.png
后插法比较符合平常的思维方式,并且保证插入数据的先后顺序。但是由于只保存了头结点,所以每次插入新元素必须重新遍历到链表末尾。为了解决这个问题,考虑增加一个尾指针,指向链表的最后一个节点。

来源:http://c.biancheng.net/cpp/uploads/allimg/140709/1-140F9153GJ93.jpg
由于前插法是在头部插入新元素,那么每次增加新元素可以直接通过头指针索引,但是得到的元素顺序与插入顺序相反。

来源:http://c.biancheng.net/cpp/uploads/allimg/140709/1-140F9152T3201.jpg

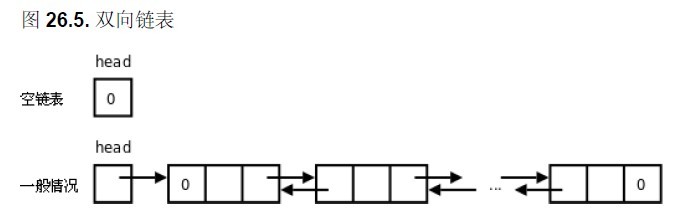


如何判断当前节点是否为最后一个节点?
在双向链表中,第一个节点的前驱节点不是头结点,而是指向一个空指针。同样的,最后一个节点的后驱指向了一个空指针。

来源:http://p.blog.csdn.net/images/p_blog_csdn_net/blacklord/%E5%9B%BE2.15.JPG
从图(b)中可以看到,不同于双向链表,循环链表中第一个节点和尾节点不在指向空指针,而是指向了头节点。
线性表:在中文里,线性表也叫作顺序表。在英文中,它称为list, linear list等。它是最基础、最简单、最常用的一种基本数据结构,线性表总存储的每个数据称为一个元素,各个元素及其索引是一一对应的关系。线性表有两种存储方式:顺序存储方式和链式存储方式。
数组(array):数组就是线性表的顺序存储方式。数组的内存是连续分配的,并且是静态分配的,即在使用数组之前需要分配固定大小的空间。可以通过索引直接得到数组中的而元素,即获取数组中元素的时间复杂度为O(1)。
链表(linked-list):链表就是线性表的链式存储方式。链表的内存是不连续的,前一个元素存储地址的下一个地址中存储的不一定是下一个元素。链表通过一个指向下一个元素地址的引用将链表中的元素串起来。
来源:http://i.stack.imgur.com/puPVJ.jpg
其实为了简便,通常我们也直接将list看做是链表。但是也不必太过纠结这种名称定义,更重要的还是关注数据结构的实现。
The thing and the name of the thing are two different things - Richard Feynman
链表分类
链表分为单向链表(Singly linked lis)、双向链表(Doubly linked list)、循环链表(Circular Linked list)。单向链表(Singly linked lis)
单向链表是最简单的链表形式。我们将链表中最基本的数据称为节点(node),每一个节点包含了数据块和指向下一个节点的指针。来源:https://upload.wikimedia.org/wikipedia/commons/4/45/Link_zh.png
typedef struct node
{
int val;
struct node *next;
}Node;头结点
单向链表有时候也分为有头结点和无头结点。有头结点的链表实现比较方便(每次插入新元素的时候,不需要每次判断第一个节点是否为空),并且可以直接在头结点的数据块部分存储链表的长度,而不用每次都遍历整个链表。// create a new node with a value
Node* CreateNode(int val)
{
Node *newNode = (Node*)malloc(sizeof(Node));
if (newNode == NULL)
{
printf("out of memory!\n");
return NULL;
} else
{
newNode->val = val;
newNode->next = NULL;
return newNode;
}
}
int main(){
Node *head = CreateNode(0);
//insert new value into list, end with END_INPUT(999)
int value;
while (scanf("%d", &value) && value != END_INPUT)
{
Insert(head, value);
}
return 0;
}插入
在链表中插入一个新的元素有两种方式:后插和前插。后插就是每次在链表的末尾插入新元素,前插就是在链表的头插入新元素。后插法比较符合平常的思维方式,并且保证插入数据的先后顺序。但是由于只保存了头结点,所以每次插入新元素必须重新遍历到链表末尾。为了解决这个问题,考虑增加一个尾指针,指向链表的最后一个节点。
来源:http://c.biancheng.net/cpp/uploads/allimg/140709/1-140F9153GJ93.jpg
void Insert(Node *head, Node *tail, int val)
{
Node *newNode = CreateNode(val);
tail->next = newNode;
tail = tail->next;
head->val ++;
}由于前插法是在头部插入新元素,那么每次增加新元素可以直接通过头指针索引,但是得到的元素顺序与插入顺序相反。
来源:http://c.biancheng.net/cpp/uploads/allimg/140709/1-140F9152T3201.jpg
void Insert(Node *head, int val)
{
Node *newNode = CreateNode(val);
newNode->next = head->next;
head->next = newNode;
head->val ++;
}删除
由于单向链表只存储了头指针,所以删除单向链表中的元素时,需要找到目标节点的前驱节点。void DeleteByVal(Node *head, int val)
{
if (head->next == NULL)
{
printf("empty list!\n");
return;
}
//find target node and its precursor
Node *cur = head->next, *pre = head;
while(cur)
{
if (cur->val == val)
break;
else {
cur = cur->next;
pre = pre->next;
}
}
//delete target node
pre->next = cur->next;
free(cur);
head->val--;
}清空链表
由于链表里面的内存是手动分配的,当不再使用这些内存时需要手动删除。void Free(Node *head)
{
for (Node *temp = head; temp != NULL; temp = head->next)
{
head = head->next;
free(temp);
}
}链表反转
Node* Reverse (Node* head) {
if (head == NULL || head->next == NULL)
return head;
else {
Node *cur = head->next,
*pre = NULL,
*next = NULL;
while (cur != NULL) {
next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
head->next = pre;
return head;
}
}双向链表(Doubly linked list)
顾名思义,双向链表就是有两个方向的链表。同单向链表不同,在双向链表中每一个节点不仅存储指向下一个节点的指针,而且存储指向前一个节点的指针。通过这种方式,能够通过在O(1)时间内通过目的节点直接找到前驱节点,但是同时会增加大量的指针存储空间。typedef struct node
{
int val;
struct node *pre;
struct node *next;
}Node;插入
在双向链表中插入新元素的操作跟在单向链表中插入新元素的操作类似。Node* CreateNode(int val)
{
Node *newNode = (Node*)malloc(sizeof(Node));
if (newNode == NULL)
{
printf("out of memory!\n");
return NULL;
} else
{
newNode->val = val;
newNode->next = NULL;
newNode->pre = NULL;
return newNode;
}
}
void Insert(Node *head, int val)
{
Node *newNode = CreateNode(val);
newNode->next = head->next;
head->next->pre = newNode;
head->next = newNode;
}删除
由于双向链表中每个节点记录了它的前驱结点,所以不需要像单向链表中一样索引目的节点的前驱节点,而是可以通过目标节点直接获得。Node* FindByVal(Node *head, int val)
{
for(Node* temp = head; temp != NULL; temp = temp->next)
{
if (temp->val == val)
return temp;
}
return NULL;
}
void DeleteByVal(Node *head, int val)
{
Node *target = FindByVal(val);
if (target == NULL)
{
printf("not find target value!\n");
return;
}
target->pre->next = target->next;
target->next->pre = target->pre;
free(target);
}其他
如何判断当前节点是否为第一个节点?如何判断当前节点是否为最后一个节点?
在双向链表中,第一个节点的前驱节点不是头结点,而是指向一个空指针。同样的,最后一个节点的后驱指向了一个空指针。
循环链表(Circular Linked list)
循环链表与双向链表相似,不同的地方在于:在链表的尾部增加一个指向头结点的指针,头结点也增加一个指向尾节点的指针,以及第一个节点指向头节点的指针,从而更方便索引链表元素。来源:http://p.blog.csdn.net/images/p_blog_csdn_net/blacklord/%E5%9B%BE2.15.JPG
插入、删除
循环链表的插入和删除操作与双向链表的实现方式一样。判断空链表、链表头和尾
从上图(a)中可以明显观察到,一个空的双向循环链表中只有一个头节点,头节点的前驱和后驱都指向本身。从图(b)中可以看到,不同于双向链表,循环链表中第一个节点和尾节点不在指向空指针,而是指向了头节点。

相关文章推荐
- [C/C++]反转链表
- C#数据结构之顺序表(SeqList)实例详解
- C#实现基于链表的内存记事本实例
- Lua教程(七):数据结构详解
- C#模拟链表数据结构的实例解析
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- C#数据结构之队列(Quene)实例详解
- C#数据结构揭秘一
- C#数据结构之单链表(LinkList)实例详解
- 数据结构之Treap详解
- C语言实现带头结点的链表的创建、查找、插入、删除操作
- C++利用静态成员或类模板构建链表的方法讲解
- C++实现简单的学生管理系统
- 用C语言举例讲解数据结构中的算法复杂度结与顺序表
- C#数据结构之堆栈(Stack)实例详解
- C#数据结构之双向链表(DbLinkList)实例详解
- JavaScript数据结构和算法之图和图算法
- Linux内核链表实现过程
- C++链表倒序实现方法
- C#通过链表实现队列的方法