Memcache-Java-Client-Release源码阅读(之六)
2016-05-06 21:57
615 查看
一、主要内容
本章节的主要内容是介绍Memcache Client的一致性Hash算法的应用及实现。
二、准备工作
1、服务器启动192.168.0.106:11211,192.168.0.106:11212两个服务端实例。
2、示例代码:
三、一致性Hash算法简单介绍
一致性Hash算法主要适用于动态变化的cache环境中,比如P2P场景,缓存系统,主要解决的问题是动态增加、删除节点引起的系统震荡。
1、Hash算法的衡量指标
单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
平衡性(Balance):指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
2、路由算法
因为在一致性Hash算法中,各个节点只负责管理一部分缓冲区,所以对于任何一个Hash的键值,存在这个键值应该归属到哪个节点的问题,这个查找算法就叫做路由算法。
举一个简单的例子,在0–2^32(2的32次方,^表示幂,下文类似)缓冲区空间内,有4个节点A、B、C、D平均分管这片空间,并且定义A分管的为0-2^8-1,B分管的为2^8-2^16,C分管的为2^16-2^24-1,D分管的为2^24-2^32,各节点都存储了本节点和其他几个邻近节点的分管信息,如果某个对象的键值为15(介于0-2^8-1 之间),那么它查询的节点应该为A。
3、一致性Hash应用模型
环形Hash空间 :按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。如下图
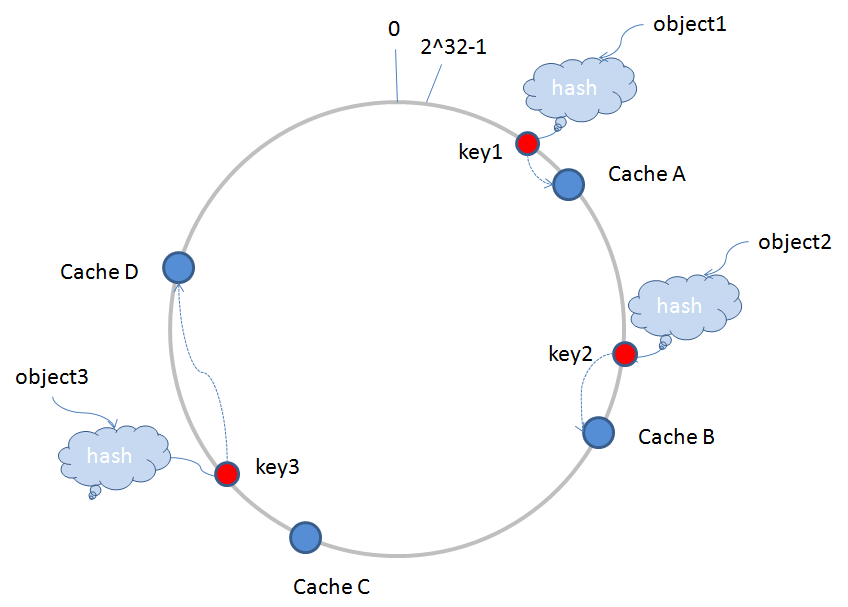
object1,object2,object3三个存储对象经过hash算法后得到的key1,key2,key3映射到环形Hash空间内,CacheA,CacheB,CacheC,CacheD表示节点服务器经过一样的Hash算法(服务器一般会采用IP或是Mac地址作为输入项,采用一定的算法取Hash值),也映射到环形空间内。这样存储对象和服务器的Hash值处在同一个Hash空间内,路由算法是顺时针查找最近的服务器,进行存储的,比如key1存储在CacheA中,key2存储在CacheB中,key3存储在CacheD中。
当运行过程中有节点服务器宕机退出时,假如CacheA宕机退出(图中变为灰色),服务器需要更新相应的路由表信息,原有的key1值根据路由算法继续查找的服务器,将由CacheA跳到CacheB(如图中红色的虚线),这样,受影响的缓冲片区仅仅为从CacheD到CacheA这一段,其他区域不受影响,如下图所示:
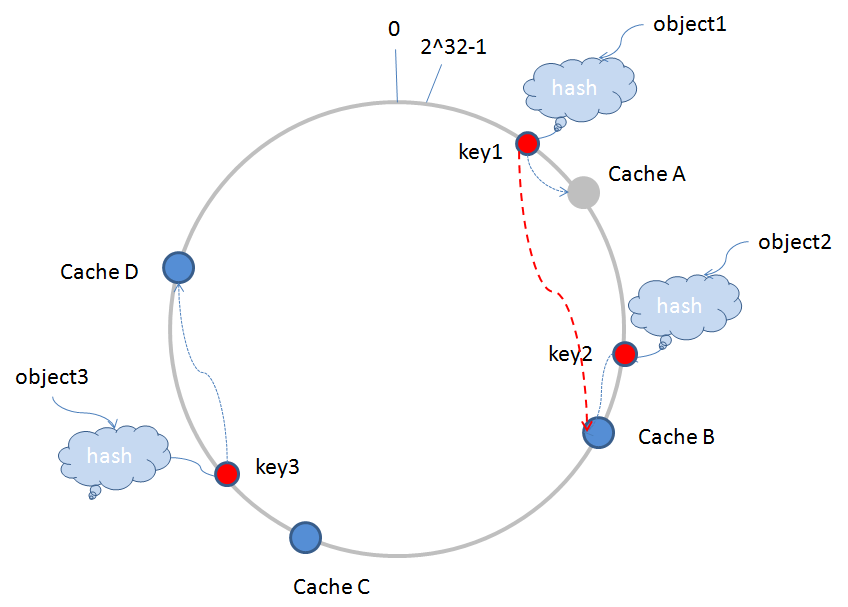
动态增加服务器,也是类似。
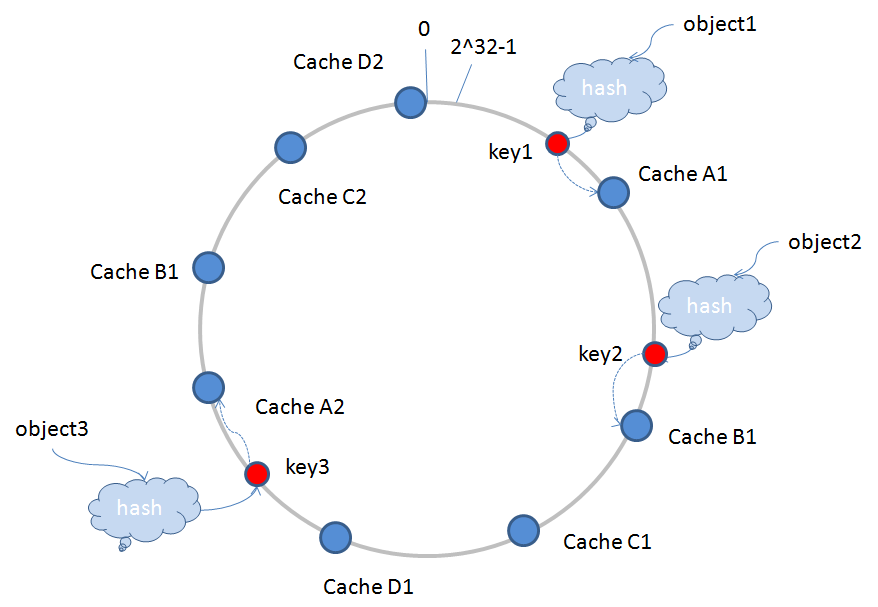
4、虚拟节点
上面的图例中,CacheA,CacheB,CacheC,CacheD分别表示实际的服务器节点,会存在一个问题:如果CacheA宕机退出,会导致原有CacheA承担的存储任务全部会积压在CacheB上面,这样很容易导致CacheB因为负荷过重也宕机了,然后把CacheA,CacheB的存储任务推给CacheC,如此一来,可能会诱发“雪崩”现象,导致所有服务器节点全部宕机。为了排除这一隐患,引入虚拟节点。
虚拟节点是实际节点在Hash空间的复制品(replica),一个实际节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在Hash空间中以Hash值排列,映射关系就由{对象->节点}转换到了{对象->虚拟节点->实际节点}。
有两个减缓“雪崩”现象的原因:
1)虚拟节点经过一定的算法,可以做到在环形Hash空间内交叉排列,这样就可以分摊宕机带来的存储压力。
2)虚拟节点数量要比实际节点多,这样可以使环形Hash空间每个虚拟节点负责存储的区域变小,即单个节点存储负荷量变小,一个节点宕机,推给下一个节点的负荷会更小。
这样就能更好地保证整体运行稳定,如下图所示CacheA1,CacheA2等表示:
四、Memcache客户端有关一致性Hash的实现
1、客户端初始化过程
在SchoonerSockIOPool类中的initialize()方法,源代码如下:
有一个很明显的分支,一致性Hash调用populateConsistentBuckets()方法,其他三个Hash算法调用populateBuckets()方法,前面已经讲过其他三个Hash算法的逻辑,这里重点讲解一致性Hash,populateConsistentBuckets()方法源码如下:
如上代码我认为可以分成三部分:
1)计算服务端节点权重之和(totalWeight);
2)factor的计算,作为生成虚拟节点数量的因子;
3)创建 GenericObjectPool对象池,这段逻辑四个Hash算法都是一样处理的。
这里我们重点看一下第二部分,注意一下factor的生成:
double factor = Math.floor(((double) (40 * this.servers.length * thisWeight))
/ (double) this.totalWeight);
根据权重的比例,计算factor因子,注意所有服务端节点的factor总和,会小于等于40 * this.servers.length。例如,两个服务端节点,factor总和会小于等于80。
而每一次factor循环时,拼接的服务端节点信息(这里的格式是ip:port-0,ip:port-1,ip:port-2,ip:port-3等),经过MD5加密得到一个16位的byte[],又会拆分成四个一组,共有四组,即byte[0],byte[1],byte[2],byte[3],作为一组,分别移位得到小于2^32大小的Long值,剩余组依次类推,这个就是上文提到的服务器信息映射到环形Hash空间内和虚拟节点的创建过程。
这里需要注意一个问题:为什么byte[3]要左移24位,byte[2]要左移16位,byte[1]要左移8位,byte[1]不移位?
因为环形Hash空间的大小为2^32-1,只有这样按24,16,8,0进行左移,才能保证服务器是基本均匀地映射在环形空间内,0–2^32各个区间都能分配到,这样才能更好的满足Hash平衡性。
我们做一个最简单的算术:
假设有2个服务端节点,不设置权重,factor总和为80,这样共能生成虚拟节点80*4=320个,2^32 - 1 = 4294967295(4G),所以一个虚拟节点负责的缓冲区间平均大约有2^32/320=13421772(12.8M)空间大小(这里要注意一下,每个虚拟节点负责的缓冲区间大小并不是均等的,均等是最理想的情况),设置了权重的话,虚拟节点负责的缓冲区间大于或等于12.8M。
这样,初始化过程中就完成了服务器信息到环形Hash空间的映射过程。
2、set/get操作
阅读过前面文章就可以知道,memcache客户端在set/get操作时,寻址的算法是一样的,在SchoonerSockIOPool类中的getBucket ()方法,源码如下所示:
先看一下缓存对象key求hash的算法,这里我们看一致性Hash的求法:
跟上面的移位操作很像,也是通过MD5得到16位的byte[],取前面四个元素进行移位,得到hash值。
得到hash值后,我们往下看,一致性Hash调用findPointFor(),其他的三个算法直接线性求模,findPointFor()源码如下:
方法很简单,直接使用TreeMap集合,调用tailMap方法,得到一个TreeMap对象的分区视图,这个分区视图集合里对象的key值,都要比当前传入的hash值大,注意一下这个集合视图,是关联原有的TreeMap对象的,修改视图也会导致原有对象被修改。
consistentBuckets集合里存储的是虚拟节点的信息,tmap调用firstKey(),意思是取比当前hash值大的元素,但这个元素是分区视图集合里面最小的,这个就是一致性Hash的路由算法实现,很神奇吧?就一句话。
现在已经很明了了,TreeMap集合对象就是前面所说的环形Hash空间,但环形又是怎么实现的呢?
我们再看一下return语句这一行,如果分区视图为空,就从原始的集合对象里取一个最小的元素,这个元素是整个集合中最小的元素,那么分区视图什么时候会是空?只有当前hash值已经比TreeMap集合中最大元素还大时,才会为空,意味着当前Hash是最接近2^32的值了,这种情况就取从0开始,一个最小元素的虚拟节点,这样就完成了环形的特性。
五、FAQ
Q1:虚拟节点Hash值计算时,是把16位的数据拆分成4个一组,这样会不会导致Hash冲突?
A1:目前MD5可以保证唯一性,即16位的byte[]肯定是唯一的,但拆分的四组,能否保证也是唯一,这个很难确定,但应该冲突的概率不高,不过就算有冲突,也只是少了一个虚拟节点而已,并不会造成多大影响。
Q2:缓存对象key的hash算法也是这样只取前面4位,会不会有冲突?
A2:原因如上,这个问题要查证,猜想只要两个不同的对象,如果MD5值的前面4位相等,就能证明这个hash算法存在不足,若有精通MD5算法的童鞋,请帮忙指点此疑问,不胜感激。
Q3:Memcache客户端中会不会出现动态增加/删除服务端节点的情况?
A3:经查阅客户端的源码,在初始化过程中,维护服务端信息的集合以及存储虚拟节点的集合就已经固定,set/get操作过程中不会对这两个集合的元素进行增删,只有在shutdown时,会清空这两个集合。如果因为这样你认为一致性Hash用处不大,你就大错特错了,因为客户端是可以shutdown再初始化的,比如,我动态增加了一些服务端节点,虽然客户端不提供方法让我热加载节点,但我可以先调用shutdown方法,再调用initialize方法的,让客户端重新加载配置文件,若是使用线性求模Hash,那么很多缓存对象将不可再用,这样一致性Hash的威力就体现出来了。
本章节的主要内容是介绍Memcache Client的一致性Hash算法的应用及实现。
二、准备工作
1、服务器启动192.168.0.106:11211,192.168.0.106:11212两个服务端实例。
2、示例代码:
String[] servers = { "192.168.0.106:11211", "192.168.0.106:11212" };
SockIOPool pool = SockIOPool.getInstance();
pool.setServers(servers);
pool.setInitConn(10);
pool.setMinConn(5);
pool.setMaxConn(250);
pool.setSocketTO(3000);
// 设置Hash算法为一致性Hash算法
pool.setHashingAlg(SockIOPool.CONSISTENT_HASH);
pool.initialize();
// 省略......三、一致性Hash算法简单介绍
一致性Hash算法主要适用于动态变化的cache环境中,比如P2P场景,缓存系统,主要解决的问题是动态增加、删除节点引起的系统震荡。
1、Hash算法的衡量指标
单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
平衡性(Balance):指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
2、路由算法
因为在一致性Hash算法中,各个节点只负责管理一部分缓冲区,所以对于任何一个Hash的键值,存在这个键值应该归属到哪个节点的问题,这个查找算法就叫做路由算法。
举一个简单的例子,在0–2^32(2的32次方,^表示幂,下文类似)缓冲区空间内,有4个节点A、B、C、D平均分管这片空间,并且定义A分管的为0-2^8-1,B分管的为2^8-2^16,C分管的为2^16-2^24-1,D分管的为2^24-2^32,各节点都存储了本节点和其他几个邻近节点的分管信息,如果某个对象的键值为15(介于0-2^8-1 之间),那么它查询的节点应该为A。
3、一致性Hash应用模型
环形Hash空间 :按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。如下图
object1,object2,object3三个存储对象经过hash算法后得到的key1,key2,key3映射到环形Hash空间内,CacheA,CacheB,CacheC,CacheD表示节点服务器经过一样的Hash算法(服务器一般会采用IP或是Mac地址作为输入项,采用一定的算法取Hash值),也映射到环形空间内。这样存储对象和服务器的Hash值处在同一个Hash空间内,路由算法是顺时针查找最近的服务器,进行存储的,比如key1存储在CacheA中,key2存储在CacheB中,key3存储在CacheD中。
当运行过程中有节点服务器宕机退出时,假如CacheA宕机退出(图中变为灰色),服务器需要更新相应的路由表信息,原有的key1值根据路由算法继续查找的服务器,将由CacheA跳到CacheB(如图中红色的虚线),这样,受影响的缓冲片区仅仅为从CacheD到CacheA这一段,其他区域不受影响,如下图所示:
动态增加服务器,也是类似。
4、虚拟节点
上面的图例中,CacheA,CacheB,CacheC,CacheD分别表示实际的服务器节点,会存在一个问题:如果CacheA宕机退出,会导致原有CacheA承担的存储任务全部会积压在CacheB上面,这样很容易导致CacheB因为负荷过重也宕机了,然后把CacheA,CacheB的存储任务推给CacheC,如此一来,可能会诱发“雪崩”现象,导致所有服务器节点全部宕机。为了排除这一隐患,引入虚拟节点。
虚拟节点是实际节点在Hash空间的复制品(replica),一个实际节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在Hash空间中以Hash值排列,映射关系就由{对象->节点}转换到了{对象->虚拟节点->实际节点}。
有两个减缓“雪崩”现象的原因:
1)虚拟节点经过一定的算法,可以做到在环形Hash空间内交叉排列,这样就可以分摊宕机带来的存储压力。
2)虚拟节点数量要比实际节点多,这样可以使环形Hash空间每个虚拟节点负责存储的区域变小,即单个节点存储负荷量变小,一个节点宕机,推给下一个节点的负荷会更小。
这样就能更好地保证整体运行稳定,如下图所示CacheA1,CacheA2等表示:
四、Memcache客户端有关一致性Hash的实现
1、客户端初始化过程
在SchoonerSockIOPool类中的initialize()方法,源代码如下:
/**
* Initializes the pool.
*/
public void initialize() {
initDeadLock.lock();
try {
// if servers is not set, or it empty, then
// throw a runtime exception
if (servers == null || servers.length <= 0) {
log.error("++++ trying to initialize with no servers");
throw new IllegalStateException(
"++++ trying to initialize with no servers");
}
// pools
socketPool = new HashMap<String, GenericObjectPool>(servers.length);
hostDead = new ConcurrentHashMap<String, Date>();
hostDeadDur = new ConcurrentHashMap<String, Long>();
// only create up to maxCreate connections at once
// initalize our internal hashing structures
if (this.hashingAlg == CONSISTENT_HASH)
populateConsistentBuckets();
else
populateBuckets();
// mark pool as initialized
this.initialized = true;
} finally {
initDeadLock.unlock();
}
}有一个很明显的分支,一致性Hash调用populateConsistentBuckets()方法,其他三个Hash算法调用populateBuckets()方法,前面已经讲过其他三个Hash算法的逻辑,这里重点讲解一致性Hash,populateConsistentBuckets()方法源码如下:
private void populateConsistentBuckets() {
// store buckets in tree map
consistentBuckets = new TreeMap<Long, String>();
MessageDigest md5 = MD5.get();
if (this.totalWeight <= 0 && this.weights != null) {
for (int i = 0; i < this.weights.length; i++)
this.totalWeight += (this.weights[i] == null) ? 1
: this.weights[i];
} else if (this.weights == null) {
this.totalWeight = this.servers.length;
}
for (int i = 0; i < servers.length; i++) {
int thisWeight = 1;
if (this.weights != null && this.weights[i] != null)
thisWeight = this.weights[i];
double factor = Math
.floor(((double) (40 * this.servers.length * thisWeight))
/ (double) this.totalWeight);
for (long j = 0; j < factor; j++) {
byte[] d = md5.digest((servers[i] + "-" + j).getBytes());
for (int h = 0; h < 4; h++) {
Long k = ((long) (d[3 + h * 4] & 0xFF) << 24)
| ((long) (d[2 + h * 4] & 0xFF) << 16)
| ((long) (d[1 + h * 4] & 0xFF) << 8)
| ((long) (d[0 + h * 4] & 0xFF));
consistentBuckets.put(k, servers[i]);
}
}
// Create a socket pool for each host
// Create an object pool to contain our active connections
GenericObjectPool gop;
SchoonerSockIOFactory factory;
if (authInfo != null) {
factory = new AuthSchoonerSockIOFactory(servers[i], isTcp,
bufferSize, socketTO, socketConnectTO, nagle, authInfo);
} else {
factory = new SchoonerSockIOFactory(servers[i], isTcp,
bufferSize, socketTO, socketConnectTO, nagle);
}
gop = new GenericObjectPool(factory, maxConn,
GenericObjectPool.WHEN_EXHAUSTED_BLOCK, maxIdle, maxConn);
factory.setSockets(gop);
socketPool.put(servers[i], gop);
}
}如上代码我认为可以分成三部分:
1)计算服务端节点权重之和(totalWeight);
2)factor的计算,作为生成虚拟节点数量的因子;
3)创建 GenericObjectPool对象池,这段逻辑四个Hash算法都是一样处理的。
这里我们重点看一下第二部分,注意一下factor的生成:
double factor = Math.floor(((double) (40 * this.servers.length * thisWeight))
/ (double) this.totalWeight);
根据权重的比例,计算factor因子,注意所有服务端节点的factor总和,会小于等于40 * this.servers.length。例如,两个服务端节点,factor总和会小于等于80。
而每一次factor循环时,拼接的服务端节点信息(这里的格式是ip:port-0,ip:port-1,ip:port-2,ip:port-3等),经过MD5加密得到一个16位的byte[],又会拆分成四个一组,共有四组,即byte[0],byte[1],byte[2],byte[3],作为一组,分别移位得到小于2^32大小的Long值,剩余组依次类推,这个就是上文提到的服务器信息映射到环形Hash空间内和虚拟节点的创建过程。
这里需要注意一个问题:为什么byte[3]要左移24位,byte[2]要左移16位,byte[1]要左移8位,byte[1]不移位?
因为环形Hash空间的大小为2^32-1,只有这样按24,16,8,0进行左移,才能保证服务器是基本均匀地映射在环形空间内,0–2^32各个区间都能分配到,这样才能更好的满足Hash平衡性。
我们做一个最简单的算术:
假设有2个服务端节点,不设置权重,factor总和为80,这样共能生成虚拟节点80*4=320个,2^32 - 1 = 4294967295(4G),所以一个虚拟节点负责的缓冲区间平均大约有2^32/320=13421772(12.8M)空间大小(这里要注意一下,每个虚拟节点负责的缓冲区间大小并不是均等的,均等是最理想的情况),设置了权重的话,虚拟节点负责的缓冲区间大于或等于12.8M。
这样,初始化过程中就完成了服务器信息到环形Hash空间的映射过程。
2、set/get操作
阅读过前面文章就可以知道,memcache客户端在set/get操作时,寻址的算法是一样的,在SchoonerSockIOPool类中的getBucket ()方法,源码如下所示:
private final long getBucket(String key, Integer hashCode) {
long hc = getHash(key, hashCode);
if (this.hashingAlg == CONSISTENT_HASH) {
return findPointFor(hc);
} else {
long bucket = hc % buckets.size();
if (bucket < 0)
bucket *= -1;
return bucket;
}
}先看一下缓存对象key求hash的算法,这里我们看一致性Hash的求法:
/**
* Internal private hashing method.
*
* MD5 based hash algorithm for use in the consistent hashing approach.
*
* @param key
* @return
*/
private static long md5HashingAlg(String key) {
MessageDigest md5 = MD5.get();
md5.reset();
md5.update(key.getBytes());
byte[] bKey = md5.digest();
long res = ((long) (bKey[3] & 0xFF) << 24)
| ((long) (bKey[2] & 0xFF) << 16)
| ((long) (bKey[1] & 0xFF) << 8) | (long) (bKey[0] & 0xFF);
return res;
}跟上面的移位操作很像,也是通过MD5得到16位的byte[],取前面四个元素进行移位,得到hash值。
得到hash值后,我们往下看,一致性Hash调用findPointFor(),其他的三个算法直接线性求模,findPointFor()源码如下:
/**
* Gets the first available key equal or above the given one, if none found,
* returns the first k in the bucket
*
* @param k
* key
* @return
*/
private final Long findPointFor(Long hv) {
SortedMap<Long, String> tmap = this. consistentBuckets.tailMap(hv);
return (tmap.isEmpty()) ? this. consistentBuckets.firstKey() : tmap
.firstKey();
}方法很简单,直接使用TreeMap集合,调用tailMap方法,得到一个TreeMap对象的分区视图,这个分区视图集合里对象的key值,都要比当前传入的hash值大,注意一下这个集合视图,是关联原有的TreeMap对象的,修改视图也会导致原有对象被修改。
consistentBuckets集合里存储的是虚拟节点的信息,tmap调用firstKey(),意思是取比当前hash值大的元素,但这个元素是分区视图集合里面最小的,这个就是一致性Hash的路由算法实现,很神奇吧?就一句话。
现在已经很明了了,TreeMap集合对象就是前面所说的环形Hash空间,但环形又是怎么实现的呢?
我们再看一下return语句这一行,如果分区视图为空,就从原始的集合对象里取一个最小的元素,这个元素是整个集合中最小的元素,那么分区视图什么时候会是空?只有当前hash值已经比TreeMap集合中最大元素还大时,才会为空,意味着当前Hash是最接近2^32的值了,这种情况就取从0开始,一个最小元素的虚拟节点,这样就完成了环形的特性。
五、FAQ
Q1:虚拟节点Hash值计算时,是把16位的数据拆分成4个一组,这样会不会导致Hash冲突?
A1:目前MD5可以保证唯一性,即16位的byte[]肯定是唯一的,但拆分的四组,能否保证也是唯一,这个很难确定,但应该冲突的概率不高,不过就算有冲突,也只是少了一个虚拟节点而已,并不会造成多大影响。
Q2:缓存对象key的hash算法也是这样只取前面4位,会不会有冲突?
A2:原因如上,这个问题要查证,猜想只要两个不同的对象,如果MD5值的前面4位相等,就能证明这个hash算法存在不足,若有精通MD5算法的童鞋,请帮忙指点此疑问,不胜感激。
Q3:Memcache客户端中会不会出现动态增加/删除服务端节点的情况?
A3:经查阅客户端的源码,在初始化过程中,维护服务端信息的集合以及存储虚拟节点的集合就已经固定,set/get操作过程中不会对这两个集合的元素进行增删,只有在shutdown时,会清空这两个集合。如果因为这样你认为一致性Hash用处不大,你就大错特错了,因为客户端是可以shutdown再初始化的,比如,我动态增加了一些服务端节点,虽然客户端不提供方法让我热加载节点,但我可以先调用shutdown方法,再调用initialize方法的,让客户端重新加载配置文件,若是使用线性求模Hash,那么很多缓存对象将不可再用,这样一致性Hash的威力就体现出来了。

相关文章推荐
- 从源码安装Mysql/Percona 5.5
- 浅析Ruby的源代码布局及其编程风格
- 使用Memcache缓存mysql数据库操作的原理和缓存过程浅析
- PHP memcache扩展的三种安装方法
- asp.net 抓取网页源码三种实现方法
- JS小游戏之仙剑翻牌源码详解
- JS小游戏之宇宙战机源码详解
- jQuery源码分析之jQuery中的循环技巧详解
- 本人自用的global.js库源码分享
- java中原码、反码与补码的问题分析
- ASP.NET使用HttpWebRequest读取远程网页源代码
- PHP模块 Memcached功能多于Memcache
- Memcache 基础教程(php 缓存)
- 配置Memcache服务器并实现主从复制功能(repcached)
- php模块memcache和memcached区别分析
- windows环境下memcache配置方法 详细篇
- 批量获取memcache值并按key的顺序返回的实现代码
- Linux服务器中对于Memcache的安装配置方法
- PHP操作Memcache实例介绍