Selective Search for Object Recognition
2016-05-05 10:49
621 查看
原文地址:http://blog.csdn.net/charwing/article/details/27180421
最近被老师弄去做图像方向,完全没相关经验,都是从论文看起。之后会整理我看的一系列论文,可能会有很多错误的地方,如果有发现,欢迎提出!
很多人问要代码,在文章结尾有分享。
Selective Search for Object Recognition
是J.R.R. Uijlings发表在2012 IJCV上的一篇文章。主要介绍了选择性搜索(Selective Search)的方法。选择性搜索综合了蛮力搜索(exhaustive search)和分割(segmentation)的方法。选择性搜索意在找出可能的目标位置来进行物体的识别。与传统的单一策略相比,选择性搜索提供了多种策略,并且与蛮力搜索相比,大幅度降低搜索空间,让我们可以用到更好的识别算法。

现实中,很多图像是包含多类别,多层次的信息的,如上图。所以我们要用到多层分割的方法,并且要用多种分割策略。
(一)选择性搜索(selectivesearch)
1. 分层分组:区域包含的信息比像素多,所以我们的特征是基于区域的。为了得到一些小的初始化的区域,用的是[13]中区域划分的方法。
[13]具体看http://blog.sciencenet.cn/blog-261330-722530.html
然后我们的分层分组算法如下:

我们首先用[13]得到一些初始化的区域R={r1,….rn}
计算出每个相邻区域的相似性s(ri,rj)
1. 找出相似性最大的区域max(S)={ri,rj}
2. 合并rt=ri∪rj
3. 从S集合中,移走所有与ri,rj相关的数据
4. 计算新集合rt与所有与它相邻区域的相似性s(rt,r*)
5. R=R∪rt
直到S集合为空,重复1~5。
2. 各种分割策略
关于s(ri,rj)的计算,我们有多种方法,但要注意的是这些相似性特征应该是可以传递的。如当我们合并ri和rj成rt时,rt的特征可以由ri和rj直接计算,而不需要根据他们每个像素点的值进行重新计算。
(1) 多种颜色模型(color model):文章共比较了8种颜色模型
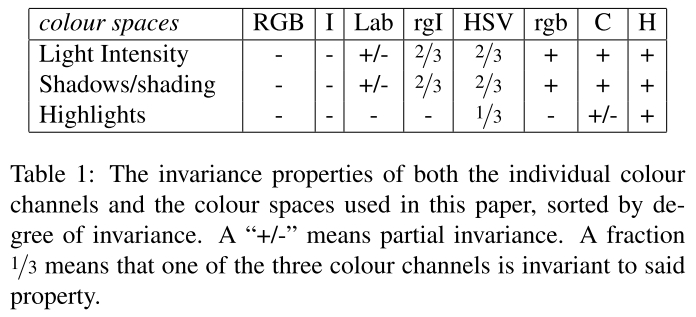
(2) 相似性准则的补充(complementary similarity measure)
共介绍了四种准则,每一种都是可以快速计算的。
Scolor(ri,rj)用于计算ri,rj的相似性。对每个区域,我们都可以得到一个一维的颜色分布直方图。直方图一共有25个区间,区域i的颜色分布直方图为
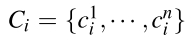
如果有3个颜色通道,则n=75。还要用L1 norm来进行归一化。
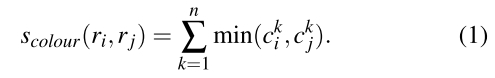
当i和j合并成t,区域t的颜色分布直方图可以用下面式子进行计算:
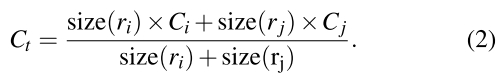
t 的size用下面式子计算:
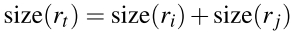
Stexture(ri,rj)我们可以用到SIFT(局部特征描述子)
SIFT介绍见:http://www.cnblogs.com/saintbird/archive/2008/08/20/1271943.html
我们取8个方向,方差为1的高斯滤波器,10个空间的直方图来描述。
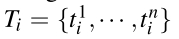
如果有3个颜色通道,n=240=8*3*10,同理得到区域i的纹理直方图要用L1norm归一化。
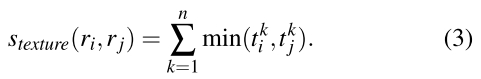
同理,纹理的传递性也可以用(2)式解决。
Ssize (ri,rj)鼓励小的区域尽早合并。
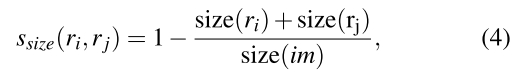
size(im)表示整个图片的像素数目。
Sfill (ri,rj)鼓励有相交或者有包含关系的区域先合并。
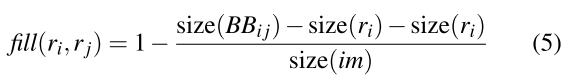
BBij指包含i,j区域的最小外包区域。
在这篇文章中,我们用到如下计算相似性:
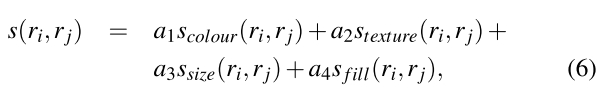
3. 初始化区域
用[13]得到的初始化区域可以根据阈值k得到不同的结果。
(二)用选择性搜索进行识别(object recognition using selective search)
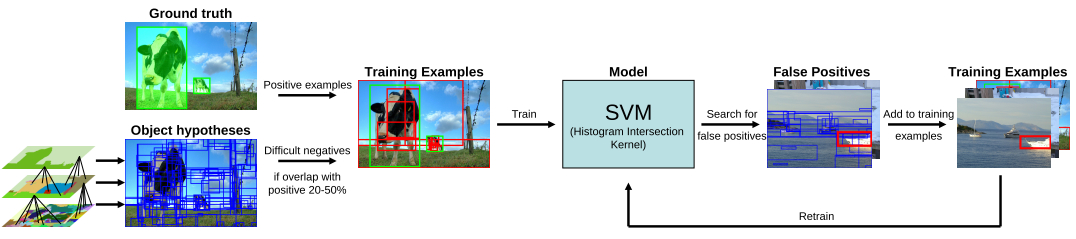
1. 训练数据的产生
在训练数据上,标注出目标区域,如上图中绿色高亮区域的奶牛,将这些标注区域作为正样本。使用selective search产生目标假设区域(也就是若干个分割区域)。将分割区域的外接矩形和目标标注区域的重叠度在20%~50%之间的区域标注为负样本。我们规定负样本之间不能有超过70%的重叠。
有了正样本和负样本之后,我们用的特征提取方法是:
color-SIFT descriptors[32]+a finer spatialpyramid division[18]
然后进行SVM训练。
2. 迭代训练
采用迭代训练方式,在每次训练完成之后,挑选出false positives样本,并将其加入到训练样本中,其实这便是增加了困难样本数。使用其进行模型训练,直到收敛(精度不在产生变化)。
(三)评价(evaluation)
文章给出了一些判断标准。
ABO(Average Best Overlap)
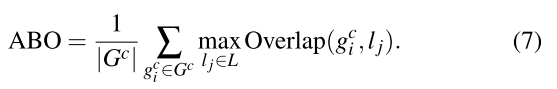
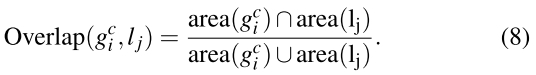
G应该是物体所在的目标区域。L是selective search算法算出的候选区域。找出Selective Search算法中与该类目标区域覆盖最多的区域。覆盖率由(8)式计算。然后再除以该类的数目。
MABO(Mean Average Best Overlap)就是计算每一类的ABO值,再求均值。
之后的实验都是基于这两个评判标准的,详细结果看论文。
本文提到的Reference:
[13] P. F. Felzenszwalb and D. P.Huttenlocher. Efficient Graph-Based Image Segmentation. IJCV, 59:167–181, 2004.
[18] S. Lazebnik, C. Schmid, and J. Ponce.Beyond bags of features: Spatial pyramid matching for recognizing natural scenecategories. In CVPR, 2006.
[32] K. E. A. van de Sande, T. Gevers, andC. G. M. Snoek. Evaluating color descriptors for object and scenerecognition.TPAMI, 32:1582–1596, 2010.
代码下载地址:http://pan.baidu.com/s/1sjOLbat
最近被老师弄去做图像方向,完全没相关经验,都是从论文看起。之后会整理我看的一系列论文,可能会有很多错误的地方,如果有发现,欢迎提出!
很多人问要代码,在文章结尾有分享。
Selective Search for Object Recognition
是J.R.R. Uijlings发表在2012 IJCV上的一篇文章。主要介绍了选择性搜索(Selective Search)的方法。选择性搜索综合了蛮力搜索(exhaustive search)和分割(segmentation)的方法。选择性搜索意在找出可能的目标位置来进行物体的识别。与传统的单一策略相比,选择性搜索提供了多种策略,并且与蛮力搜索相比,大幅度降低搜索空间,让我们可以用到更好的识别算法。
现实中,很多图像是包含多类别,多层次的信息的,如上图。所以我们要用到多层分割的方法,并且要用多种分割策略。
(一)选择性搜索(selectivesearch)
1. 分层分组:区域包含的信息比像素多,所以我们的特征是基于区域的。为了得到一些小的初始化的区域,用的是[13]中区域划分的方法。
[13]具体看http://blog.sciencenet.cn/blog-261330-722530.html
然后我们的分层分组算法如下:
我们首先用[13]得到一些初始化的区域R={r1,….rn}
计算出每个相邻区域的相似性s(ri,rj)
1. 找出相似性最大的区域max(S)={ri,rj}
2. 合并rt=ri∪rj
3. 从S集合中,移走所有与ri,rj相关的数据
4. 计算新集合rt与所有与它相邻区域的相似性s(rt,r*)
5. R=R∪rt
直到S集合为空,重复1~5。
2. 各种分割策略
关于s(ri,rj)的计算,我们有多种方法,但要注意的是这些相似性特征应该是可以传递的。如当我们合并ri和rj成rt时,rt的特征可以由ri和rj直接计算,而不需要根据他们每个像素点的值进行重新计算。
(1) 多种颜色模型(color model):文章共比较了8种颜色模型
(2) 相似性准则的补充(complementary similarity measure)
共介绍了四种准则,每一种都是可以快速计算的。
Scolor(ri,rj)用于计算ri,rj的相似性。对每个区域,我们都可以得到一个一维的颜色分布直方图。直方图一共有25个区间,区域i的颜色分布直方图为
如果有3个颜色通道,则n=75。还要用L1 norm来进行归一化。
当i和j合并成t,区域t的颜色分布直方图可以用下面式子进行计算:
t 的size用下面式子计算:
Stexture(ri,rj)我们可以用到SIFT(局部特征描述子)
SIFT介绍见:http://www.cnblogs.com/saintbird/archive/2008/08/20/1271943.html
我们取8个方向,方差为1的高斯滤波器,10个空间的直方图来描述。
如果有3个颜色通道,n=240=8*3*10,同理得到区域i的纹理直方图要用L1norm归一化。
同理,纹理的传递性也可以用(2)式解决。
Ssize (ri,rj)鼓励小的区域尽早合并。
size(im)表示整个图片的像素数目。
Sfill (ri,rj)鼓励有相交或者有包含关系的区域先合并。
BBij指包含i,j区域的最小外包区域。
在这篇文章中,我们用到如下计算相似性:
3. 初始化区域
用[13]得到的初始化区域可以根据阈值k得到不同的结果。
(二)用选择性搜索进行识别(object recognition using selective search)
1. 训练数据的产生
在训练数据上,标注出目标区域,如上图中绿色高亮区域的奶牛,将这些标注区域作为正样本。使用selective search产生目标假设区域(也就是若干个分割区域)。将分割区域的外接矩形和目标标注区域的重叠度在20%~50%之间的区域标注为负样本。我们规定负样本之间不能有超过70%的重叠。
有了正样本和负样本之后,我们用的特征提取方法是:
color-SIFT descriptors[32]+a finer spatialpyramid division[18]
然后进行SVM训练。
2. 迭代训练
采用迭代训练方式,在每次训练完成之后,挑选出false positives样本,并将其加入到训练样本中,其实这便是增加了困难样本数。使用其进行模型训练,直到收敛(精度不在产生变化)。
(三)评价(evaluation)
文章给出了一些判断标准。
ABO(Average Best Overlap)
G应该是物体所在的目标区域。L是selective search算法算出的候选区域。找出Selective Search算法中与该类目标区域覆盖最多的区域。覆盖率由(8)式计算。然后再除以该类的数目。
MABO(Mean Average Best Overlap)就是计算每一类的ABO值,再求均值。
之后的实验都是基于这两个评判标准的,详细结果看论文。
本文提到的Reference:
[13] P. F. Felzenszwalb and D. P.Huttenlocher. Efficient Graph-Based Image Segmentation. IJCV, 59:167–181, 2004.
[18] S. Lazebnik, C. Schmid, and J. Ponce.Beyond bags of features: Spatial pyramid matching for recognizing natural scenecategories. In CVPR, 2006.
[32] K. E. A. van de Sande, T. Gevers, andC. G. M. Snoek. Evaluating color descriptors for object and scenerecognition.TPAMI, 32:1582–1596, 2010.
代码下载地址:http://pan.baidu.com/s/1sjOLbat

相关文章推荐
- PHP GD 图像处理组件的常用函数总结
- PHP图像处理之imagecreate、imagedestroy函数介绍
- jsvascript图像处理―(计算机视觉应用)图像金字塔
- Javascript图像处理思路及实现代码
- PHP图像处理之使用imagecolorallocate()函数设置颜色例子
- java数字图像处理基础使用imageio写图像文件示例
- 使用Java进行图像处理的一些基础操作
- javascript图像处理―边缘梯度计算函数
- Javascript图像处理―阈值函数实例应用
- Javascript图像处理―虚拟边缘介绍及使用方法
- PHP图像处理类库及演示分享
- php图像处理函数大全(推荐收藏)
- Javascript图像处理―图像形态学(膨胀与腐蚀)
- Javascript图像处理―平滑处理实现原理
- Swift图像处理之优化照片
- 在Ubuntu上安装OpenCV3.0和Python-openCV的经历
- VTK学习笔记之图像处理
- vtk 图像处理 多种 操作
- 05-VTK在图像处理中的应用(2)
- 计算机视觉领域的牛人博客和有实力的研究机构