深入理解HTTP(一)
2016-05-04 11:52
351 查看
B/S网络架构
采用HTTP(无状态短连接)来交互数据(应用层),可以达到处理大量用户请求的要求http连接
本质上是建立一个socket连接,通过outputstream.write发送到目标服务器,通过inputstream.read来接受返回数据。http header
控制用户浏览器的渲染行为和服务器的执行该逻辑(如404状态码)
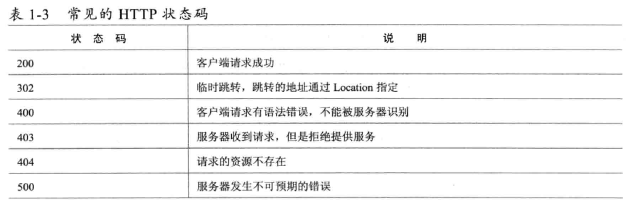
浏览器缓存机制:
缓存分为服务端侧(server side,比如 Nginx、Apache)和客户端侧(client side,比如 web browser)。服务端缓存又分为 代理服务器缓存 和 反向代理服务器缓存(也叫网关缓存,比如 Nginx反向代理、Squid等),其实广泛使用的 CDN 也是一种服务端缓存,目的都是让用户的请求走”捷径“,并且都是缓存图片、文件等静态资源。
客户端侧缓存一般指的是浏览器缓存,目的就是加速各种静态资源的访问,想想现在的大型网站,随便一个页面都是一两百个请求,每天 pv 都是亿级别,如果没有缓存,用户体验会急剧下降、同时服务器压力和网络带宽都面临严重的考验。
浏览器缓存控制机制有两种:HTML Meta标签 vs. HTTP头信息
浏览器缓存机制,其实主要就是HTTP协议定义的缓存机制(如: Expires; Cache-control等)。但是也有非HTTP协议定义的缓存机制,如使用HTML Meta 标签,Web开发者可以在HTML页面的节点中加入标签,代码如下:
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">
上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器拉取。使用上很简单,但只有部分浏览器可以支持,而且所有缓存代理服务器都不支持,因为代理不解析HTML内容本身。而广泛应用的还是 HTTP头信息 来控制缓存。
参考:http://my.oschina.net/leejun2005/blog/369148

相关文章推荐
- Unix网络编程 第四章 笔记
- 关于R语言和社交网络分析的几篇文章
- 苹果Xcode帮助文档阅读指南-https://developer.apple.com/library/ios/navigation/
- Android网络连接系列学习(一)
- 刷单、打字员等这类网络兼职靠谱吗?
- 转HTTP协议 --- Cookie
- Java中发送Http请求Get、Post
- python http.client 进行 get 跟 post 访问
- PHP $_SERVER['HTTP_HOST']与$_SERVER["SERVER_NAME"]的区别
- HTTP 协议详解
- python urllib 对 https 的访问不支持
- 网络显示连接,但是无法打开网页的解决方法
- Redis网络协议详解
- 【codevs1935】【BZOJ2879】美食节,网络流之动态加点
- LINUX网络状态工具SS命令使用详解
- caffe微调网络时的注意事项(持续更新中)
- vmware 虚拟网络环境配置
- charles抓取https请求包
- charles抓取https请求包
- charles抓取https请求包