HttpGet协议与正则表达
2016-05-03 11:44
579 查看
使用HttpGet协议与正则表达实现桌面版的糗事百科
写在前面最近在重温asp.net,找了一本相关的书籍。本书在第一章就讲了,在不使用浏览器的情况下生成一个web请求,获取服务器返回的内容。于是在网上搜索关于Http请求相关的资料,发现了很多资料都是讲述基于HttpGet和HttpPost请求服务器的资源,然根据Get和Post的单词意思就大概知道Get(得到)意为从服务中获取资源,而Post(发送)意为先发送数据包返还给服务器再获取服务器资源。当然他们之间还有一些其他的区别,但是本文主要讲的不是这个。当知道如何使用Get和Post的请求去访问服务器的数据,我就迫不及待找一些网页来做测试,于是就有了糗事百科的Winform版啦。
下面给大家看看效果。
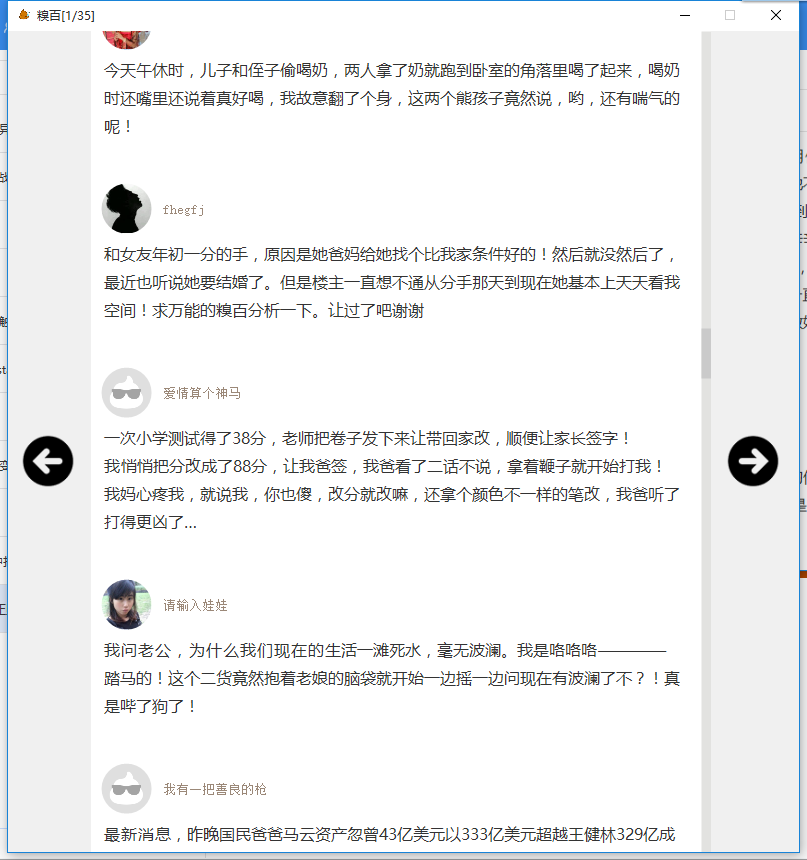
下面我将这个过程分为以下几个部分来进行讲解,并在文章的最后提供下载链接。
1、分析糗事百科的网页,构造web请求。
2、分析网页html源代码,提取需要的信息。
3、数据绑定。
1、分析糗事百科的网页,构造web请求
打开糗事百科笑话的主页,在这里我只取糗事笑话中文字这一板块,点击文字这一菜单栏。如下图。
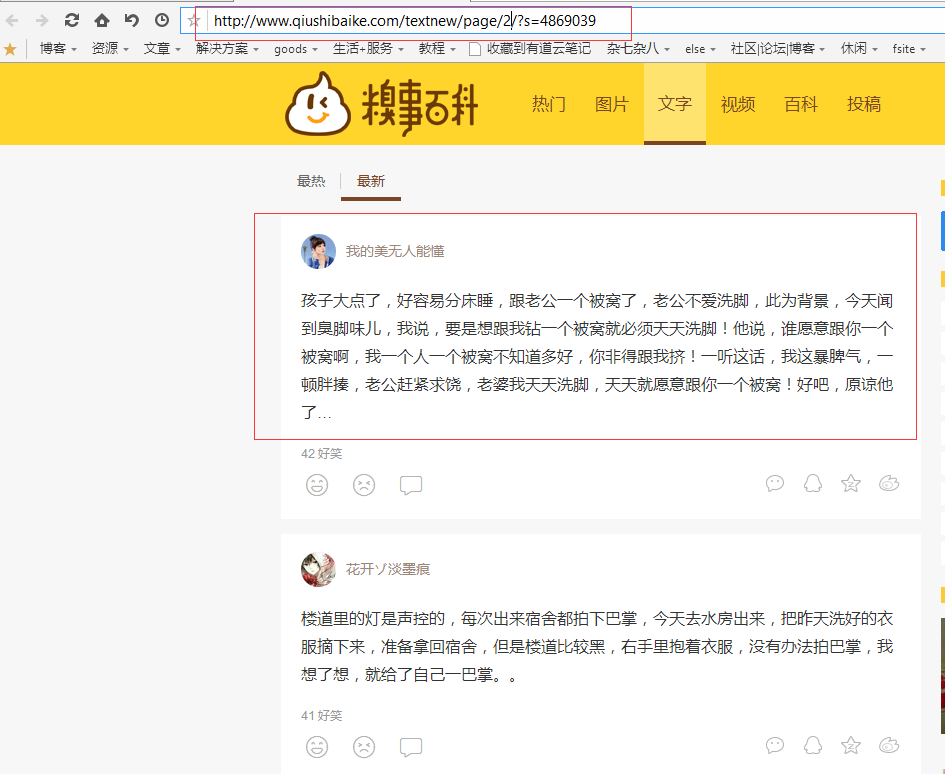
1.1 获取糗事百科内容的url
从上图可以看出,文字版本的url链接为:http://www.qiushibaike.com/textnew/page/2/?s=4869039。根据链接的内容可以看出http://www.qiushibaike.com为该网页的主机部分是不变的,/textnew/page代表是文字笑话这一主题的页面也是不变的,而后面的数字2和?s=4869039是url中变换不同页面内容的关键,通过分析得知数字2代表不同的文字笑话的页数,而?s=4869039没有弄得很清楚,估计是标识符啥的,但是并不影响,我们就把它固定下来,不做改变。综上所述在http://www.qiushibaike.com/textnew/page/2/?s=4869039中我们只需要变动数字2就可以获取不同页面的文字笑话内容。
1.2 构造HttpGet请求的头信息
上一步我们获取了文字内容页面的url,下面我需要模拟浏览器针对这个url构造一个Get请求,从而获取糗百的页面数据。打开浏览器的开发者工具,从中可以看到浏览器构造的详细的http请求的报头信息如下图。然后我们在代码中仿照这样的请求报头信息去请求服务器资源。
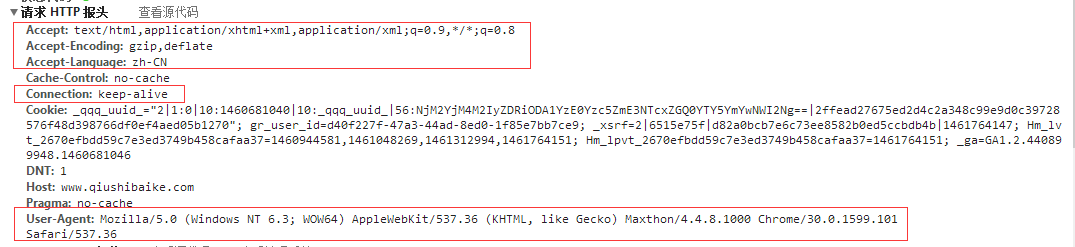
注意:其中红线标示的部分在实例化一个Http请求类时都需要被设置,否则会得到错误的返回结果。
1.3 c#实现糗百网页的抓取
根据上面的分析,我使用c#语言并利用System.Net程序集中的HttpWebRequest和HttpWebResponse这两个类去实现网页内容的抓取。
源代码如下:
const string qsbkMainUrl = "http://www.qiushibaike.com";
//获取糗百文字笑话页的url
private static string GetWBJokeUrl(int pageIndex)
{
StringBuilder url = new StringBuilder();
url.Append(qsbkMainUrl);
url.Append ("/textnew/page/");
url.Append(pageIndex.ToString ());
url.Append("/?s=4869039");
return url.ToString();
}
//根据网页的url获取网页的html源码
private static string GetUrlContent(string url)
{
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.8.1000 Chrome/30.0.1599.101 Safari/537.36";
request.Method = "GET";
request.ContentType = "text/html;charset=UTF-8";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));//因为知道糗百网页的编码方式为utf-8
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
catch { return null; }
}2、分析网页html源代码,提取需要的信息
在1中我们已经根据page页索引的不同而获取不同的页面内容,而这一步的任务就是如何从返回的html源代码中获取我们想要的笑话内容。
我们提取网页文字的笑话内容包括三个部分:发布笑话者的头像,发布笑话者的昵称,发布内容。
2.1 分析网页构造正则表达式
首先我们对html源码进行分析并找出我们想要的内容所在的标签位置,以及它们的html的结构。
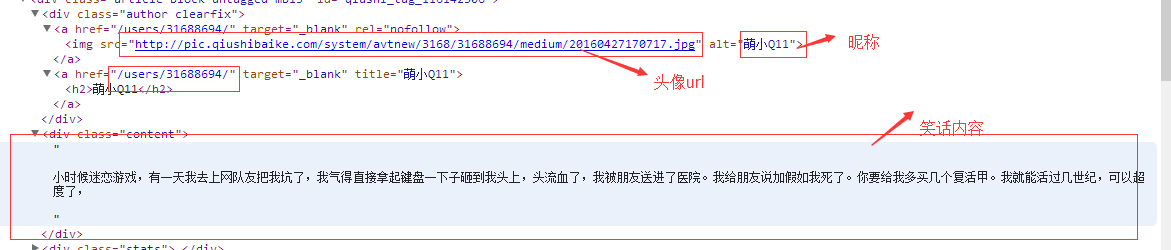
这上面是我分析的我们所需要的内容所在html源码中的标签位置,由于一个页面中每条笑话的html显示标签都是一样的,所以只要能偶提取一条笑话的内容,那么该页的其它笑话也可以同样提取。由于这种结构基本是固定的,每个笑话的各部分内容都是用相同的html标签表示,并且位置也是相同的,因此在写正则表达的时候,可以用很多常量字符去固定,这样能够加快正则的匹配效率。下面给出匹配笑话内容的正则表达,(通过分组实现捕获一个笑话的不同内容)。当然这个正则表达式可能存在一些不能完全精确匹配的情况。
正则:<img src="([^"]*")\s*alt="([^"]*)"/>\s</a>\s<a href="([^"]*)"[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class="content">\s*((.*|<br/>)*)
其中,第一个括号里面的内容代表“头像地址”,第二个括号里面的内容代表“昵称”,第三个括号里面的内容代表“笑话内容”
2.2 编码获取页面的所有笑话
a、首先建一个笑话的实体类
public class JokeItem
{
private string nickName;
/// <summary>
/// 昵称
/// </summary>
public string NickName
{
get { return nickName; }
set { nickName = value; }
}
private Image headImage;
/// <summary>
/// 头像
/// </summary>
public Image HeadImage
{
get { return headImage; }
set { headImage = value; }
}
private string jokeContent;
/// <summary>
/// 笑话内容
/// </summary>
public string JokeContent
{
get { return jokeContent; }
set { jokeContent = value; }
}
private string jokeUrl;
/// <summary>
/// 笑话地址
/// </summary>
public string JokeUrl
{
get { return jokeUrl; }
set { jokeUrl = value; }
}
}b、利用正则获取笑话内容
/// <summary>
/// 获取笑话列表
/// </summary>
/// <param name="htmlContent"></param>
public static List<JokeItem> GetJokeList(int pageIndex)
{
string htmlContent=GetUrlContent(GetWBJokeUrl(pageIndex));
List<JokeItem> jokeList = new List<JokeItem>();
Regex rg = new Regex(@"<img src=""([^""]*"")\s*alt=""([^""]*)""/>\s</a>\s<a href=""([^""]*)""[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class=""content"">\s*((.*|<br/>)*)", RegexOptions.IgnoreCase);
JokeItem joke;
MatchCollection matchResults = rg.Matches(htmlContent);
foreach (Match result in matchResults)
{
joke = new JokeItem();
joke.HeadImage = GetWebImage(result.Groups[1].Value);
joke.HeadImage = joke.HeadImage != null ? new Bitmap(GetWebImage(result.Groups[1].Value), 50, 50) : null;
joke.NickName = result.Groups[2].Value;
joke.JokeUrl = qsbkMainUrl + "/" + result.Groups[3].Value; ;
joke.JokeContent = result.Groups[4].Value.Replace("<br/>", "\r\n").Replace("<br>", "\r\n");
joke.JokeContent = Regex.Replace(joke.JokeContent, @"(\r\n)+", "\r\n");//去掉多余的空行
jokeList.Add(joke);
}
return jokeList;
}c、根据头像url地址获取头像
private static Image GetWebImage(string webUrl)
{
try
{
Encoding encode = Encoding.GetEncoding("utf-8");//网页编码==Encoding.UTF8
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(new Uri(webUrl));
HttpWebResponse ress = (HttpWebResponse)req.GetResponse();
Stream sstreamRes = ress.GetResponseStream();
return System.Drawing.Image.FromStream(sstreamRes);
}
catch { return null; }
}3、数据绑定
数据都获取了,数据绑定是最容易的一步,由于数据获取这一步牵涉到web请求,会发生几秒的网络延迟,因此需要使用一个后台的工作线程去请求数据。在此处采用backgroundWorker控件来实现异步请求数据。其中UI部分借用了两个第三方控件,一个是加载的等待条,另一个是数据绑定控件。数据绑定代码就不贴出来了。可以在下面下载我的源码。
4、总结
在这个过程中,我对http的请求方式有了进一步的理解,也终于把平常学习的正则表达式发挥了用处。
把平常学习到的技术综合起来再结合一个好的想法就会做出让自己意想不到的小程序,希望自己以后能多把自己学习的技术与实践结合起来。
开发环境:vs2013,.net2.0
源码地址:http://download.csdn.net/detail/mingge38/9504931

相关文章推荐
- http错误代码含义大全详解
- zabbix 监控 TCP 连接数
- adb通过TCP/IP来调试Android设备,adb直接往editTest文本框里写文本
- F5/LVS/Nginx/HAProxy硬软件级网络负载均衡介绍
- IOS socket基于tcp/udp的通信
- python-网络:原始套接字和流量嗅探
- 【TCP/IP】路由选择之TTL
- Taglist: Exuberant ctags (http://ctags.sf.net) not found in PATH. Plugin is not loaded.
- 一根网线的风波
- iOS中 HTTP/Socket/TCP/IP通信协议详解
- iOS TCP通讯
- TCP/IP协议 卷一 -----------广播和多播
- LR 录制Web(HTTP/HTML)脚本的模式选择
- Java使用HTTPClient4.3开发的公众平台消息模板的推送功能
- An error occurred at line: 307 in the generated java file The code of method _jspService (HttpServle
- Volley网络请求框架的使用
- UnityEditor.AsyncHTTPClient:Done(State, Int32)异常处理
- SVN 错误:Error validating server certificate for 'https://xxxxxxx':443... Mac os svn客户端证书验证缓存 解决
- HTTP POST请求报文格式分析与Java实现文件上传
- MAPI over HTTP和RPC over HTTP的区别