《机器学习实战》Logistic回归算法(1)
2016-04-25 00:13
786 查看

打开微信扫一扫,关注微信公众号【数据与算法联盟】
转载请注明出处:http://blog.csdn.net/gamer_gyt
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer=================================================================《机器学习实战》系列博客是博主阅读《机器学习实战》这本书的笔记也包含一些其他python实现的机器学习算法 算法实现均采用pythongithub 源码同步:https://github.com/Thinkgamer/Machine-Learning-With-Python=====================================================================
关于回归算法的分析与scikit-learn代码分析实现请参考:点击阅读 ,Logistic回归模型案例实战:《机器学习实战》Logistic回归算法(2)下面算法演示用到的数据集在博客最后
一:Sigmoid函数和Logistic回归分类器
1:Sigmoid函数
单位阶跃函数(或者称为海维塞德阶跃函数):在二分问题下,函数的输出类别是0和1,Simoid函数就是属于这种函数其函数表达式为: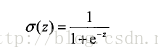
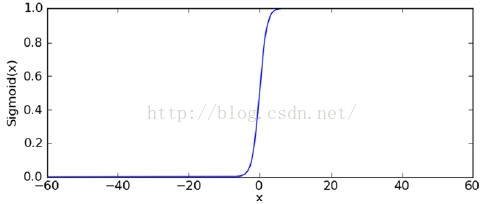
其显示的图象为:
2:Logistic回归分类器
Simoid函数的输入记为:z=w0x0 + w1x1 + w2x2 .... + wnxn如果采用向量的写法,上述公式可以写成z=w^t * x(w^t表示系数w的转置矩阵)代入到Sigmoid函数可得:
其输出分大于0.5和小于0.5,表示两个类别,也就实现了分类,确定了分类器的函数形式,接下来问题就是求最佳回归系数
二:基于最优化方法的最佳回归系数确定
2.1:梯度上升法
主要思想:要找到某函数的最大值,最好的办法是沿着该函数的梯度方向探寻下边这种图片是机器学习实战对梯度的数学解释:
梯度是有方向的,总是沿着函数值上升最快的方向移动(这有点感觉想物理中的加速度),因此我们沿着梯度方向或者反方向行进时,就能达到一个函数的最大值或者最小值,因此梯度上升算法就是不断更新梯度值,直到梯度不再变化或者变化很小,即函数达到了最大值梯度算法的迭代公式为(alpha为步长,即每一步移动量):
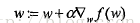
那么问题来了,我们如何求解函数的梯度,在 Machine Learning in Action一书中,作者没有解释,直接给出了代码
h = sigmoid(dataMatrix*weights) error = (labelMat - h) weights = weights + alpha * dataMatrix.transpose()* error当然在实战这本书也没有具体说明(这里有一篇博客对这个公式进行了猜想推测:http://blog.sina.com.cn/s/blog_61f1db170101k1wr.html )
求梯度上升算法的代码,并画出图形:
#coding:utf-8
'''
Created on 2016/4/24
@author: Gamer Think
'''
from numpy import *
#加载数据集
def loadDataSet():
dataMat = []
labelMat = []
fp = open("ex1.txt")
for line in fp.readlines():
lineArr = line.strip().split("\t") #每行按\t分割
dataMat.append([1.0,float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
#定义Sigmoid函数
def sigmoid(inX):
return 1.0/(1+exp(-inX))
#定义求解最佳回归系数
def gradAscent(dataMatIn,classLabels):
dataMatrix = mat(dataMatIn) #将数组转为矩阵
labelMat = mat(classLabels).transpose()
m,n = shape(dataMatrix) #返回矩阵的行和列
alpha = 0.001 #初始化 alpha的值
maxCycles = 500 #最大迭代次数
weights = ones((n,1)) #初始化最佳回归系数
for i in range(0,maxCycles):
#引用原书的代码,求梯度
h = sigmoid(dataMatrix*weights)
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
return weights
#分析数据,画出决策边界
def plotBestFit(wei,dataMatrix,labelMat):
import matplotlib.pyplot as plt
weights = wei.getA() #将矩阵wei转化为list
dataArr = array(dataMatrix) #将矩阵转化为数组
n = shape(dataMatrix)[0]
xcord1 = [];ycord1=[]
xcord2 = [];ycord2=[]
for i in range(n):
if int(labelMat[i])==1:
xcord1.append(dataArr[i,1])
ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1])
ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='red', marker='s')
ax.scatter(xcord2,ycord2,s=30,c="green")
x = arange(-3.0,3.0,0.1)
y = (-weights[0]-weights[1] * x)/weights[2]
ax.plot(x,y)
plt.xlabel("x1") #X轴的标签
plt.ylabel("x2") #Y轴的标签
plt.show()
if __name__=="__main__":
dataMatrix,labelMat = loadDataSet()
weight = gradAscent(dataMatrix, labelMat)
plotBestFit(weight,dataMatrix,labelMat)显示效果图: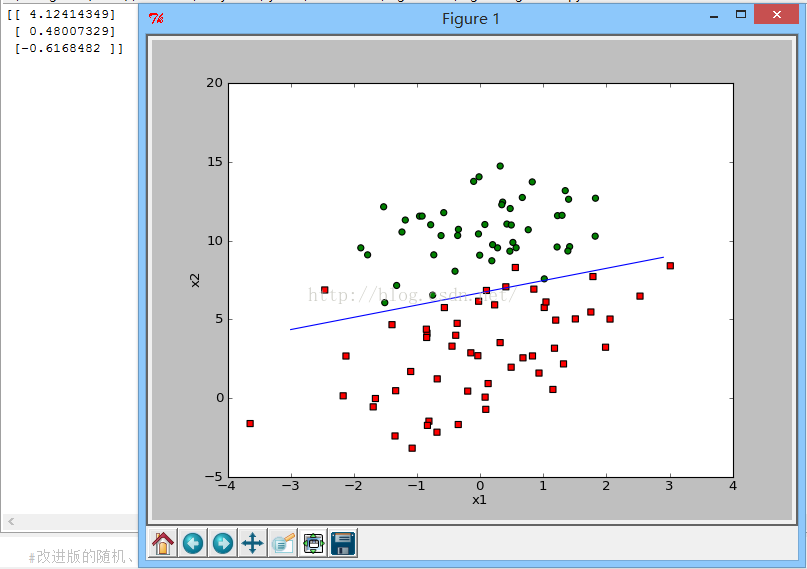
2.2随机梯度上升算法
梯度上升算法在每次更新回归系数时都需要遍历整个数据集,该方法在处理100个左右的数据集尚可,但如果数据量增大,那该方法的计算量就太大了,有一种改进方法是一次仅用一个样本点来更新回归系数,该方法称为随机梯度上升算法,由于可以在新样本到来时对分类器进行增量式更新,因而随机梯度上升算法是一个在线学习算法。随机梯度上升算法的代码如下:<span style="font-size:18px;">#随机梯度上升算法求回归系数 def stocGradAscent0(dataMatrix,labelMat): dataMatrix = array(dataMatrix) m,n = shape(dataMatrix) alpha = 0.01 weights = ones(n) for i in range(0,m): h = sigmoid(sum(dataMatrix[i]*weights)) error = labelMat[i] - h weights = weights + alpha * error * dataMatrix[i] return weights</span><span style="font-size: 14px;"> </span>
main函数调用代码:
#随机梯度上升算法 weight = stocGradAscent0(dataMatrix, labelMat) print weight plotBestFit(weight,dataMatrix,labelMat)
显示效果图如下
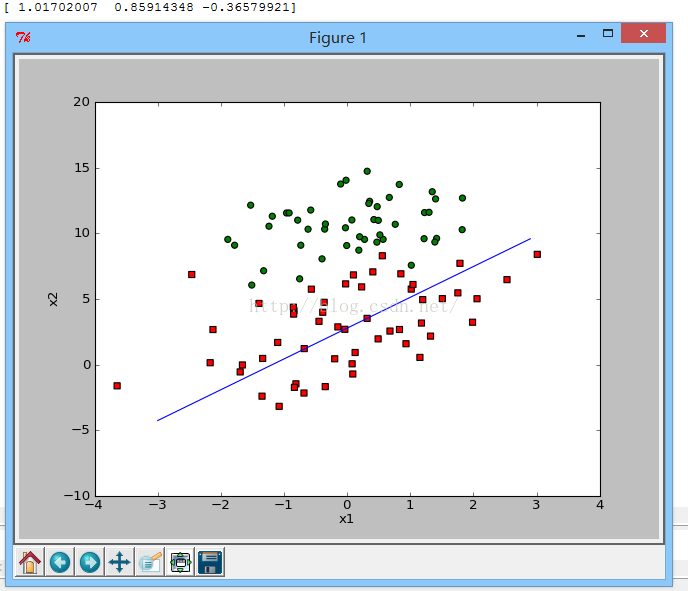
2.3改进版的随机梯度上升算法
存在一些不能正确分类的点样本点(数据集并非线性可分),在每次迭代时会引发系数的剧烈变化。我们期望算法能够避免来回波动,从而收列到某个值<span style="font-size:18px;">#改进版的随机梯度上升算法 def stocGradAscent1(dataMatrix,labelMat,numIter=150): m,n = shape(dataMatrix) weights = ones(n) for i in range(0,numIter): dataIndex = range(m) for j in range(0,m): alpha = 4/(1.0+j+i)+0.01 #(1) randIndex = int(random.uniform(0,len(dataIndex))) #(2) h = sigmoid(sum(dataMatrix[randIndex] * weights)) error = labelMat[randIndex] - h weights = weights + alpha * error * dataMatrix[randIndex] del(dataIndex[randIndex]) return weights </span><span style="font-size: 14px;"> </span>(1):alpha在每次 迭代的时候都会调整,会缓解数据波动和高频波动,另外alpha会随着迭代次数不断减小,但永远不会减小到0,这是因为(1)中存在一个常数项,这样做的目的是保证在多次迭代后新数据仍有一定的影响力,如果处理的问题是动态的,可以适当加大上边的常数项,来保证新的书获得更大的回归系数,另外一点值得注意的是,在降低alpha的函数中,alpha每次减小1/(j+i),其中j是迭代次数,i是样本点的下标,这样当j<<max(i)时,alpha就不是严格下降的,避免参数的严格下降也是常见于模拟退火算法等其他优化算法中(2):通过随机选择样本来更新回归系数,这样方法将减小周期性波动,每次随机从列表中选出一个值,然后从列表中删除该值。此外增加了一个迭代次数作为第三个参数,如果不给定的话,默认是150次。
main函数调用代码:
<span style="font-size:18px;"> #改进版的随机梯度上升算法 weight = stocGradAscent1(array(dataMatrix), labelMat) print weight plotBestFit(weight,dataMatrix,labelMat)</span>
显示效果图如下:
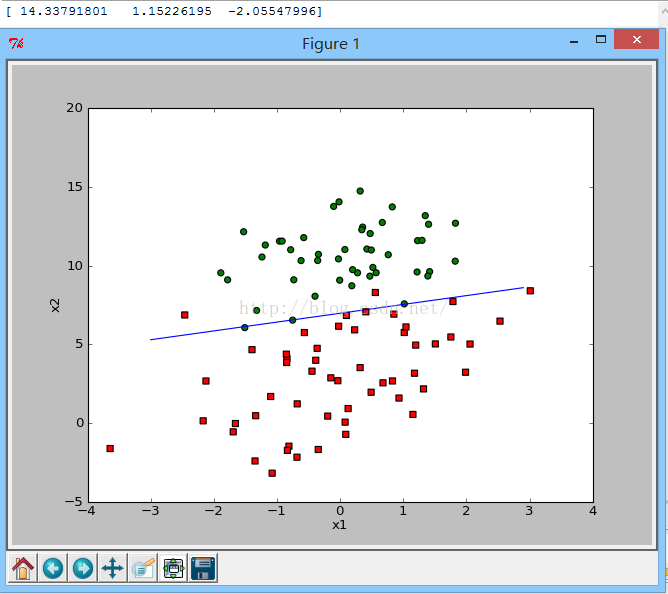
数据集内容如下:-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
0.850433 6.920334 1
1.347183 13.175500 0
1.176813 3.167020 1
-1.781871 9.097953 0
-0.566606 5.749003 1
0.931635 1.589505 1
-0.024205 6.151823 1
-0.036453 2.690988 1
-0.196949 0.444165 1
1.014459 5.754399 1
1.985298 3.230619 1
-1.693453 -0.557540 1
-0.576525 11.778922 0
-0.346811 -1.678730 1
-2.124484 2.672471 1
1.217916 9.597015 0
-0.733928 9.098687 0
-3.642001 -1.618087 1
0.315985 3.523953 1
1.416614 9.619232 0
-0.386323 3.989286 1
0.556921 8.294984 1
1.224863 11.587360 0
-1.347803 -2.406051 1
1.196604 4.951851 1
0.275221 9.543647 0
0.470575 9.332488 0
-1.889567 9.542662 0
-1.527893 12.150579 0
-1.185247 11.309318 0
-0.445678 3.297303 1
1.042222 6.105155 1
-0.618787 10.320986 0
1.152083 0.548467 1
0.828534 2.676045 1
-1.237728 10.549033 0
-0.683565 -2.166125 1
0.229456 5.921938 1
-0.959885 11.555336 0
0.492911 10.993324 0
0.184992 8.721488 0
-0.355715 10.325976 0
-0.397822 8.058397 0
0.824839 13.730343 0
1.507278 5.027866 1
0.099671 6.835839 1
-0.344008 10.717485 0
1.785928 7.718645 1
-0.918801 11.560217 0
-0.364009 4.747300 1
-0.841722 4.119083 1
0.490426 1.960539 1
-0.007194 9.075792 0
0.356107 12.447863 0
0.342578 12.281162 0
-0.810823 -1.466018 1
2.530777 6.476801 1
1.296683 11.607559 0
0.475487 12.040035 0
-0.783277 11.009725 0
0.074798 11.023650 0
-1.337472 0.468339 1
-0.102781 13.763651 0
-0.147324 2.874846 1
0.518389 9.887035 0
1.015399 7.571882 0
-1.658086 -0.027255 1
1.319944 2.171228 1
2.056216 5.019981 1
-0.851633 4.375691 1
-1.510047 6.061992 0
-1.076637 -3.181888 1
1.821096 10.283990 0
3.010150 8.401766 1
-1.099458 1.688274 1
-0.834872 -1.733869 1
-0.846637 3.849075 1
1.400102 12.628781 0
1.752842 5.468166 1
0.078557 0.059736 1
0.089392 -0.715300 1
1.825662 12.693808 0
0.197445 9.744638 0
0.126117 0.922311 1
-0.679797 1.220530 1
0.677983 2.556666 1
0.761349 10.693862 0
-2.168791 0.143632 1
1.388610 9.341997 0
0.317029 14.739025 0

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- Python 七步捉虫法