[置顶] JavaSE学习笔记21:Java正则表达式
2016-04-24 18:19
786 查看
Java正则表达式
1、正则表达式(特点)
正则表达式,顾名思义,就是符合一定规则的表达式。作用是专门用于操作字符串,虽说String类中已经有了很多操作字符串的方法,但是它们的功能单一,操作起来还麻烦,正则弥补了它们的补足。
下面我们通过一个小例子来感受一下区别:
需求:对QQ号码进行校验,要求:5~15位,0不能开头,只能是数字。
(1)常规的做法:
class CheckQQ
{
public static void main(String[] args)
{
String qq="3891289y49";
checkQQ(qq);
}
//常规的做法:
public static void checkQQ(String str)
{
String qq=str;
if(str.length()>=5&&str.length()<=15)
{
if(!str.startsWith("0"))
{
char[] chs=str.toCharArray();
boolean flag=true;
for(int x=0;x<chs.length;x++)
{
if(!(chs[x]>='0'&&chs[x]<='9'))
{
flag=false;
break;
}
}
if(flag==true)
System.out.println("qq:"+qq);
else
System.out.println("出现非法字符!");
}
else
{
System.out.println("不可以0开头!");
}
}
else
{
System.out.println("长度错误!");
}
}
}
我们可以优化一下:
/*
char[] chs=str.toCharArray();
boolean flag=true;
for(int x=0;x<chs.length;x++)
{
if(!(chs[x]>='0'&&chs[x]<='9'))
{
flag=false;
break;
}
}
if(flag==true)
System.out.println("qq:"+qq);
else
System.out.println("出现非法字符!");
*/
回忆之前我们学过的Integer.parseInt(String str);
如果str=“12a”,那么Integer.parseInt(String str)就会抛出异常:NumberFormatException·。
因此我们可以将这个方法用在此处。
将上面一大片代码改成:
try
{
long l=Long.parseLong(qq);
System.out.println("qq:"+qq);
}
catch(Exception e)
{
System.out.println("出现非法字符!");
}
但是,尽管我们这么优化,代码还是很复杂。因此我们只得另辟蹊径。
(2)用正则表达式来做:
通过查找API文档,我们发现String类中一个方法,之前我们没讲的:
boolean matches(String regex):告知此字符串是否匹配给定的正则表达式。用规则匹配整个字符串,只要有一处不符合规则,匹配结果就返回-1。
什么意思呢,就是说字符串是否符合给定的规则。这个规则通过一个字符串来定义,因此称之为正则表达式。正则表达式通常用regex来表示,它也是一个字符串。
import java.util.regex.*;
class CheckQQ
{
public static void main(String[] args)
{
String qq="3891289y49";
checkQQ(qq);
}
//用正则表达式:
public static void checkQQ(String str)
{
String qq=str;
String regex="[1-9][0-9]{4,14}";
boolean flag=qq.matches(regex);
if(flag)
System.out.println("qq:"+qq);
System.out.println("出现非法字符");
}
}
解释:
"[1-9][0-9]{4,14}"
[1-9]:表示字符串的第一位必须是1到9范围内的一个数字。
[0-9]:表示字符串的第二位必须是0到9范围内的一个数字。
{4,14}:表示想第二位这样的数据可以出现4,5,6,7,8,9,10,11,12,13,14次,包括第二位这一次出现在内。
"[1-9][0-9]{4,14}"从左往右看,还是从右往左看都可以。
这些符号都封装在java.util.regex包中的Pattern类中,因此要导包。
可以明显的看到,代码少了很多,这就是正则表达式的威力之处。可以看出,正则表达式就是用一些特定的符号来表示一些代码操作,这样就简化了书写。所以学习正则表达式就是在学习一些特殊符号的使用。
2、正则表达式(功能)
(1)匹配。
boolean matches(String regex):告知此字符串是否匹配给定的正则表达式。
首先,我们去找Pattern类,发现有下面的一些基本符号需要重点掌握:
1)字符类
[abc]:a、b或c(简单类)
[^abc]:任何字符,除了a、b或c(否定)
[a-zA-z]:a到z或A到Z,两头的字母包括在内(范围)
[a-d[m-p]]:a到d或m到p:[a-dm-p](并集)
[a-z&&[def]]d、e、f(交集)
a、String regex="[bcd]"
matches(regex)
表示字符串中的内容是否只有一位,且这一位是否取值为b、c、d中任意一个字符。
b、String regex="[123]"
matches(regex)
表示字符串中的内容是否只有一位,且这一位是否取值为1、2、3中任意一个字符。
c、String regex="[bcd][a-z]"
matches(regex);
表示字符串中的内容是否只有两位,且第一位是否取值为a、b、c中任意一个字符,第二位是否取值为a到z范围内的任意一个字符。
d、String regex="[a-zA-Z][0-9]"
matches(regex);
表示字符串中的内容是否只有两位,且第一位是否取值为a到z范围和A-Z范围中任意一个字符,即是否是字母,第二位是否取值为0到9范围内的任意一个字符,即是否是数字。
2)预定义字符
.<=>任何字符
\d<=>[0-9]
\D<=>[^0-9]
\W<=>[a-zA-Z_0-9]
ps:这些预定义字符放在双引号中,要当心转义的问题。比如:.,必须是\\.;\d,必须是\\d;其他类推。
因此:
regex="[a-zA-Z][0-9]",可以表示成:
regex="[a-zA-Z]\\d"
3)Greedy数量词
X?,表示X这样特点的字符可以出现一次或者一次也不出现。
X*,表示X这样特点的字符可以出现零次或者多次。
X+,表示X这样特点的字符可以出现一次或多次。
X{n},表示X这样特点的字符可以出现n次。
X{n,},表示X这样特点的字符至少出现n次。
X{n,m},表示X这样特点的字符至少出现n次,但是不超过m次。
a、String regex="[a-zA-z]\\d?";
matches(regex);
表示字符串中的内容是否只有三位或者只有两位。而且第一位是否取值为任
意一个字母,第二位是否取值为任意一个数字,并且第三位可有可无,有的
也是以数字的形式出现。
b、String regex="[a-zA-z]\\d*";
matches(regex);
表示字符串中的内容是最少为两位。而且第一位是否取值为任意一个字母, 第二位是否取值为任意一个数字,并且第三位以及第三位以后可有可无,有
的话也是以数字的形式出现。
示例:
(1)校验QQ号码。
需求:对QQ号码进行校验,要求:5~15位,0不能开头,只能是数字。
import java.util.regex.*;
class CheckQQ
{
public static void main(String[] args)
{
String qq="3891289y49";
checkQQ(qq);
}
public static void checkQQ(String str)
{
String qq=str;
String regex="[1-9][0-9]{4,14}";
boolean flag=qq.matches(regex);
if(flag)
System.out.println("qq:"+qq);
System.out.println("出现非法字符");
}
}
(2)校验手机码。
需求:手机号段:13XXXX、15XXXXX、18XXXXX
import java.util.regex.*;
class CheckTel
{
public static void main(String[] args)
{
String tel="132095097503";
checkTel(tel);
}
public static void checkTel(String str)
{
String tel=str;
String regex="1[358]\\d{9}";
boolean flag=tel.matches(regex);
if(flag)
System.out.println("是范围内的号码");
System.out.println("不是范围内的号码");
}
}
(2)[b]切割。
String[] split(String regex):根据给定正则表达式的匹配拆分字符串。
1)按照","去切割。
String str="zhangsan,lisi,wangwu";
String regex=",";
String[] arr=str.split(regex);
2)按照"."去切割。
String str="zhangsan.lisi.wangwu";
String regex="\\.";
String[] arr=str.split(regex);
3)按照" "去切割。
String str="zhangsan lisi wangwu";
String regex=" ";
String[] arr=str.split(regex);
4)按照" "去切割。
String str="zhangsan lisi wangwu";
Stirng regex=" +";//两个或多个空格
String[] arr=str.split(regex);
ps:如果单词之间所隔的空格不一样,就不能写死用几个空格来分割。这时这样定义规则是比较合理的。
5)按照"/"去切割。
String str="zhangsan/lisi/wangwu";
String regex="//";
String[] arr=str.split(regex);
6)按照"//"去切割。
String str="zhangsan//lisi//wangwu";
String regex="////";
Stirng[] arr=str.split(regex);
7)按照"叠词"去切割。
String str="zhangsankklisiqqwangwuoo0";
String regex="(.)\\1+";
String[] arr=str.split(regex);
ps:
这里要引出一个重要的概念了。就是“组”的概念。
一般,我们对一个规则的结果进行重用,就将它封装成一个组。组的出现都有编号,想要使用已有的组可以通过\n(n就是组的编号)的形式来获取。例如在表达式:((A)(B(C))),就存在四个组:((A)(B(C)))、(A)、(B(C))、(C)。可以通过从左到右计算其开括号来编号。这里也能看出,正则表达式的一个弊端:符号定义越多,正则越大,阅读性越差。
分割原理图:
比如以zhangsan,lisi,wangwu为例:

(3)替换。
String replaceAll(String regex,String replacement):使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串。
示例:
String str="hoaheo29409275028jsi ho jf09w39u93594399";
(1)将超过5个数字替换成"#"。
String regex="\\d{5,}";
str.replaceAll(regex,"#");
(2)将叠词替换成单个词。
Stirng regex="(.)\\1+";
str.replaceAll(regex,"$1");
Ps:$也是获取组的符号。
(4)获取。
将字符串中符合规则的子串取出。
这个功能必须要用到java.util.regex包中的Pattern类和Matcher类。
Pattern类中没有构造方法。
操作步骤:
1)将正则表达式封装成对象。
Pattern类中的方法:
static Pattern compile(String regex):将给定的正则表达式编译到模式中。
2)让正则对象和要操作的字符串相关联。关联后,获取正则匹配引擎。
Pattern类中的方法:
Macher matcher(CharSequence input):创建匹配给定输入与此模式的匹配器。
3)通过引擎对符合规则的子串进行操作,比如取出。
Macher类中的方法:
boolean find():尝试查找与该模式匹配的输入序列的下一个子序列。
String group():返回由以前匹配操作所匹配的输入子序列。即符合规则的字符子串。
int start():返回以前匹配的初始索引。即符合规则的字符子串的初始位置。
int end():返回最后匹配字符之后的偏移量。即符合规则的字符子串的结束位置。
ps:拿到匹配器对象,就可以对字符串进行很多操作。比如:
matches(),其实String类中的matches方法,用的就是Pattern和Matcher对象来完成的。只不过被String的方法封装后,用起来较为简单。但是功能却单一。
下面用代码来体现:
需求:现在想获取一行字符串中三个字母组成的单词。
import java.util.regex.*;
class GetDemo
{
public static void main(String[] args)
{
getDemo();
}
public static void getDemo()
{
String str="main ini fidn jai jain jij";
/*"\b":是一个表示单词边界的字符。属于边界匹配器。*/
String regex="\\b[a-z]{4}\\b";
//1.将正则表达式封装成对象。
Pattern p=Pattern.compile(regex);
//2.将正则对象和要作用的字符串相关联,获取匹配器对象。
Matcher m=p.matcher(str);
//3.对通过匹配器对象对字符串进行操作。
/*
boolean flag1=m.find();
System.out.println(flag1);
String str1=m.group();
System.out.println(str1);
boolean flag2=m.find();
System.out.println(flag2);
String str2=m.group();
System.out.println(str2);
boolean flag3=m.find();
System.out.println(flag3);
String str3=m.group();
System.out.println(str3);
*/
while(m.find())
{
System.out.println(m.group());
System.out.println(m.start()+"...."+m.end());
}
}
}
运行结果:
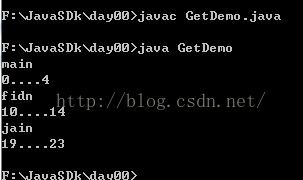
这里注意一个小问题:
import java.util.regex.*;
class GetDemo
{
public static void main(String[] args)
{
getDemo();
}
public static void getDemo()
{
String str="main ini fidn jai jain jij";
/*"\b":是一个表示单词边界的字符。属于边界匹配器。*/
String regex="\\b[a-z]{4}\\b";
//1.将正则表达式封装成对象。
Pattern p=Pattern.compile(regex);
//2.将正则对象和要作用的字符串相关联,获取匹配器对象。
Matcher m=p.matcher(str);
//3.对通过匹配器对象对字符串进行操作。
System.out.println("matches:"+m.matches());
while(m.find())
{
System.out.println(m.group());
System.out.println(m.start()+"...."+m.end());
}
}
}
加了这句话之后,运行结果如下:
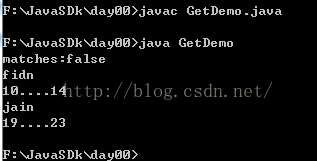
同一个匹配器的时候,它用的是同一个指针。m.matches()匹配失败以后,进入循环以后,指针就进入下一个单词进行匹配判断了。
3、正则表达式(练习)
(1)将下列字符串转化成:我要学编程。
String str="我我....我我....我要...要要..要要..学学学..学学..学.. 编编..编编....程程....程程程....程";
import java.util.regex.*;
class RegexDemo
{
public static void main(String[] args)
{
String str=
"我我....我我....我要...要要..学学..学..编编....程程....程";
/*
思路:将已有字符串变成另一个字符串。使用替换功能。
1.将"."去掉。
2.将多个相同字符变成单个字符。
*/
str=str.replaceAll("\\.","");
System.out.println(str);
str=str.replaceAll("(.)\\1+","$1");
System.out.println(str);
}
}
运行结果:
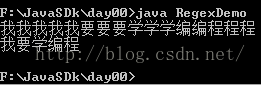
(2)将下列ip地址进行地址段顺序的排序。
192.68.1.254 102.49.23.0 12.3.56.2 2.4.5.7
import java.util.regex.*;
import java.util.*;
class RegexDemo
{
public static void main(String[] args)
{
/*
还按照字符串自然顺序,只要让它们每一段都是3位即可。
1、按照每一段需要的最多的0进行补齐,那么每一段就会
至少保留有3位。
2、将每一段只保留3位。这样,所有的ip地址都是每一段3位。
*/
String str="192.68.1.254 102.49.23.0 12.3.56.2 2.4.5.7";
str=str.replaceAll("(\\d+)","00$1");
System.out.println(str);
str=str.replaceAll("0*(\\d{3})","$1");
System.out.println(str);
String[] arr=str.split(" +");
TreeSet<String> ts=new TreeSet<String>();
for(String s:arr)
{
ts.add(s);
}
for(String s:ts)
{
System.out.println(s.replaceAll("0*(\\d+)","$1"));
}
}
}
运行结果:
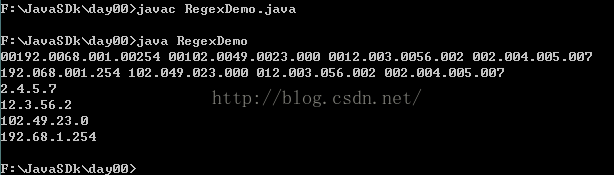
(3)定义规则对邮件地址进行校验。
1)较为精确的匹配。
import java.util.regex.*;
import java.util.*;
class RegexDemo
{
public static void main(String[] args)
{
/*
String str="34A5a25@sina.com";
String regex="[a-zA-z_0-9]+@[a-zA-z_0-9]+\\.[a-zA-z]+";
System.out.println(str.matches(regex));
str="34A5a25@sina.com.cn";
regex="[a-zA-z_0-9]+@[a-zA-z_0-9]+\\.[a-zA-z]+\\.[a-zA-Z]+";
System.out.println(str.matches(regex));
*/
String str="34A5a25@sina.com.cn";
String regex="[a-zA-z_0-9]+@[a-zA-z_0-9]+(\\.[a-zA-z]+)+";
System.out.println(str.matches(regex));
}
}
2)较为不精确的匹配。
import java.util.regex.*;
import java.util.*;
class RegexDemo
{
public static void main(String[] args)
{
String str="34A5a25@sina.com.cn";
//String regex="[a-zA-z_0-9]+@[a-zA-z_0-9]+(\\.[a-zA-z]+)+"
String regex="\\w+@\\w+(\\.\\w+)+";
System.out.println(str.matches(regex));
}
}
4、拓展:正则表达式在网页爬虫中的应用
什么是网页爬虫呢?
所谓的网页爬虫(蜘蛛):一段小程序(功能),去爬互联网上的一些指定信息。但是,爬虫之前得有数据源。
下面我们说一个较实际的需求:
互联网兴起以后,很多人想打广告,想让很多人知道我这个网站,但是我不想花更多的前,想找一些小公司获或者找个人来做。个人怎么做的呢?就是发垃圾邮件,这种方式比较直观一点,就是说我给你发到邮箱里边去,你点开邮箱以后呢,你就愿意去看这个网站,你只要一点,我这个网站就可以赚钱了。那么有个问题就是,我们得搞个邮箱啊。早期那帮哥们就自己算邮箱,怎么算呢,就是用随机的方式或者顺序的方式去产生,如ABC1、ABC2、ABC3等用户名,这样就算出邮箱来,紧接着写个邮件程序,往这一匹邮箱里发指定的广告页面。可是算了好多个邮箱,只有几个是已经被注册过了,是有用的,又很多邮箱是没注册过的,是废的,中奖率不高,因此,就想去互联网上去获取一匹已经存在的邮箱。怎么获取呢?我们知道,网络上有很多邮箱地址怎么来的呢?比如,去技术论坛发帖看帖的时候就会看到这种现象:“各位坛友们,我手里边有本java葵花宝典,那位需要,请留下邮箱”。于是,下面就会有很多人要,并且留下了邮箱,那哥们就将所有的邮箱都复制过来放在自己的邮件里边去,来个群发。那么这个论坛的网页是有很多邮箱地址,搞一个爬虫过去,把网页获取到以后把里边的数据一行行扫,把凡是符合邮箱的数据全取出。这些邮箱地址都是真实的,可用的,存在的。这个就是爬邮箱的实例,还可以爬其他的东西。百度就是做这个的。
假设我现在有c盘下有一个.html文件,文件中有好多行文字,文字里边呢也有很多邮箱地址。我们想将这个文件中的邮箱地址取出来。
import java.io.*;
import java.util.regex.*;
class PachonDemo
{
public static void main(String[] args)throws Exception
{
BufferedReader bufr=
new BufferedReader(new FileReader("C:\\mail.txt"));
String regex="\\w+@\\w+(\\.\\w+)+";
Pattern p=Pattern.compile(regex);
String line=null;
while((line=bufr.readLine())!=null)
{
Matcher m=p.matcher(line);
while(m.find())
{
System.out.println(m.group());
}
}
}
}
拓展:如果这个文件是网络上的呢?即数据源从网络上获取。
我们先将这个html格式的文件放在tomcat服务器上。如:放在F:\tomcat\webapps\myweb目录下。将tomcat服务器打开。
编写代码,然后运行,就可以出现想要的结果。
import java.io.*;
import java.util.regex.*;
class PachonDemo
{
public static void main(String[] args)throws Exception
{
URL url=new URL("http://127.0.0.1:8080/myweb/demo.html");
Connection conn=url.openConnection();
BufferedReader bufr=
new BufferedReader(new InputStreamReader(conn.getInputStream()));
String regex="\\w+@\\w+(\\.\\w+)+";
Pattern p=Pattern.compile(regex);
String line=null;
while((line=bufr.readLine())!=null)
{
Matcher m=p.matcher(line);
while(m.find())
{
System.out.println(m.group());
}
}
}
}
2016-04-23至
2016-04-24著
1、正则表达式(特点)
正则表达式,顾名思义,就是符合一定规则的表达式。作用是专门用于操作字符串,虽说String类中已经有了很多操作字符串的方法,但是它们的功能单一,操作起来还麻烦,正则弥补了它们的补足。
下面我们通过一个小例子来感受一下区别:
需求:对QQ号码进行校验,要求:5~15位,0不能开头,只能是数字。
(1)常规的做法:
class CheckQQ
{
public static void main(String[] args)
{
String qq="3891289y49";
checkQQ(qq);
}
//常规的做法:
public static void checkQQ(String str)
{
String qq=str;
if(str.length()>=5&&str.length()<=15)
{
if(!str.startsWith("0"))
{
char[] chs=str.toCharArray();
boolean flag=true;
for(int x=0;x<chs.length;x++)
{
if(!(chs[x]>='0'&&chs[x]<='9'))
{
flag=false;
break;
}
}
if(flag==true)
System.out.println("qq:"+qq);
else
System.out.println("出现非法字符!");
}
else
{
System.out.println("不可以0开头!");
}
}
else
{
System.out.println("长度错误!");
}
}
}
我们可以优化一下:
/*
char[] chs=str.toCharArray();
boolean flag=true;
for(int x=0;x<chs.length;x++)
{
if(!(chs[x]>='0'&&chs[x]<='9'))
{
flag=false;
break;
}
}
if(flag==true)
System.out.println("qq:"+qq);
else
System.out.println("出现非法字符!");
*/
回忆之前我们学过的Integer.parseInt(String str);
如果str=“12a”,那么Integer.parseInt(String str)就会抛出异常:NumberFormatException·。
因此我们可以将这个方法用在此处。
将上面一大片代码改成:
try
{
long l=Long.parseLong(qq);
System.out.println("qq:"+qq);
}
catch(Exception e)
{
System.out.println("出现非法字符!");
}
但是,尽管我们这么优化,代码还是很复杂。因此我们只得另辟蹊径。
(2)用正则表达式来做:
通过查找API文档,我们发现String类中一个方法,之前我们没讲的:
boolean matches(String regex):告知此字符串是否匹配给定的正则表达式。用规则匹配整个字符串,只要有一处不符合规则,匹配结果就返回-1。
什么意思呢,就是说字符串是否符合给定的规则。这个规则通过一个字符串来定义,因此称之为正则表达式。正则表达式通常用regex来表示,它也是一个字符串。
import java.util.regex.*;
class CheckQQ
{
public static void main(String[] args)
{
String qq="3891289y49";
checkQQ(qq);
}
//用正则表达式:
public static void checkQQ(String str)
{
String qq=str;
String regex="[1-9][0-9]{4,14}";
boolean flag=qq.matches(regex);
if(flag)
System.out.println("qq:"+qq);
System.out.println("出现非法字符");
}
}
解释:
"[1-9][0-9]{4,14}"
[1-9]:表示字符串的第一位必须是1到9范围内的一个数字。
[0-9]:表示字符串的第二位必须是0到9范围内的一个数字。
{4,14}:表示想第二位这样的数据可以出现4,5,6,7,8,9,10,11,12,13,14次,包括第二位这一次出现在内。
"[1-9][0-9]{4,14}"从左往右看,还是从右往左看都可以。
这些符号都封装在java.util.regex包中的Pattern类中,因此要导包。
可以明显的看到,代码少了很多,这就是正则表达式的威力之处。可以看出,正则表达式就是用一些特定的符号来表示一些代码操作,这样就简化了书写。所以学习正则表达式就是在学习一些特殊符号的使用。
2、正则表达式(功能)
(1)匹配。
boolean matches(String regex):告知此字符串是否匹配给定的正则表达式。
首先,我们去找Pattern类,发现有下面的一些基本符号需要重点掌握:
1)字符类
[abc]:a、b或c(简单类)
[^abc]:任何字符,除了a、b或c(否定)
[a-zA-z]:a到z或A到Z,两头的字母包括在内(范围)
[a-d[m-p]]:a到d或m到p:[a-dm-p](并集)
[a-z&&[def]]d、e、f(交集)
a、String regex="[bcd]"
matches(regex)
表示字符串中的内容是否只有一位,且这一位是否取值为b、c、d中任意一个字符。
b、String regex="[123]"
matches(regex)
表示字符串中的内容是否只有一位,且这一位是否取值为1、2、3中任意一个字符。
c、String regex="[bcd][a-z]"
matches(regex);
表示字符串中的内容是否只有两位,且第一位是否取值为a、b、c中任意一个字符,第二位是否取值为a到z范围内的任意一个字符。
d、String regex="[a-zA-Z][0-9]"
matches(regex);
表示字符串中的内容是否只有两位,且第一位是否取值为a到z范围和A-Z范围中任意一个字符,即是否是字母,第二位是否取值为0到9范围内的任意一个字符,即是否是数字。
2)预定义字符
.<=>任何字符
\d<=>[0-9]
\D<=>[^0-9]
\W<=>[a-zA-Z_0-9]
ps:这些预定义字符放在双引号中,要当心转义的问题。比如:.,必须是\\.;\d,必须是\\d;其他类推。
因此:
regex="[a-zA-Z][0-9]",可以表示成:
regex="[a-zA-Z]\\d"
3)Greedy数量词
X?,表示X这样特点的字符可以出现一次或者一次也不出现。
X*,表示X这样特点的字符可以出现零次或者多次。
X+,表示X这样特点的字符可以出现一次或多次。
X{n},表示X这样特点的字符可以出现n次。
X{n,},表示X这样特点的字符至少出现n次。
X{n,m},表示X这样特点的字符至少出现n次,但是不超过m次。
a、String regex="[a-zA-z]\\d?";
matches(regex);
表示字符串中的内容是否只有三位或者只有两位。而且第一位是否取值为任
意一个字母,第二位是否取值为任意一个数字,并且第三位可有可无,有的
也是以数字的形式出现。
b、String regex="[a-zA-z]\\d*";
matches(regex);
表示字符串中的内容是最少为两位。而且第一位是否取值为任意一个字母, 第二位是否取值为任意一个数字,并且第三位以及第三位以后可有可无,有
的话也是以数字的形式出现。
示例:
(1)校验QQ号码。
需求:对QQ号码进行校验,要求:5~15位,0不能开头,只能是数字。
import java.util.regex.*;
class CheckQQ
{
public static void main(String[] args)
{
String qq="3891289y49";
checkQQ(qq);
}
public static void checkQQ(String str)
{
String qq=str;
String regex="[1-9][0-9]{4,14}";
boolean flag=qq.matches(regex);
if(flag)
System.out.println("qq:"+qq);
System.out.println("出现非法字符");
}
}
(2)校验手机码。
需求:手机号段:13XXXX、15XXXXX、18XXXXX
import java.util.regex.*;
class CheckTel
{
public static void main(String[] args)
{
String tel="132095097503";
checkTel(tel);
}
public static void checkTel(String str)
{
String tel=str;
String regex="1[358]\\d{9}";
boolean flag=tel.matches(regex);
if(flag)
System.out.println("是范围内的号码");
System.out.println("不是范围内的号码");
}
}
(2)[b]切割。
String[] split(String regex):根据给定正则表达式的匹配拆分字符串。
1)按照","去切割。
String str="zhangsan,lisi,wangwu";
String regex=",";
String[] arr=str.split(regex);
2)按照"."去切割。
String str="zhangsan.lisi.wangwu";
String regex="\\.";
String[] arr=str.split(regex);
3)按照" "去切割。
String str="zhangsan lisi wangwu";
String regex=" ";
String[] arr=str.split(regex);
4)按照" "去切割。
String str="zhangsan lisi wangwu";
Stirng regex=" +";//两个或多个空格
String[] arr=str.split(regex);
ps:如果单词之间所隔的空格不一样,就不能写死用几个空格来分割。这时这样定义规则是比较合理的。
5)按照"/"去切割。
String str="zhangsan/lisi/wangwu";
String regex="//";
String[] arr=str.split(regex);
6)按照"//"去切割。
String str="zhangsan//lisi//wangwu";
String regex="////";
Stirng[] arr=str.split(regex);
7)按照"叠词"去切割。
String str="zhangsankklisiqqwangwuoo0";
String regex="(.)\\1+";
String[] arr=str.split(regex);
ps:
这里要引出一个重要的概念了。就是“组”的概念。
一般,我们对一个规则的结果进行重用,就将它封装成一个组。组的出现都有编号,想要使用已有的组可以通过\n(n就是组的编号)的形式来获取。例如在表达式:((A)(B(C))),就存在四个组:((A)(B(C)))、(A)、(B(C))、(C)。可以通过从左到右计算其开括号来编号。这里也能看出,正则表达式的一个弊端:符号定义越多,正则越大,阅读性越差。
分割原理图:
比如以zhangsan,lisi,wangwu为例:
(3)替换。
String replaceAll(String regex,String replacement):使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串。
示例:
String str="hoaheo29409275028jsi ho jf09w39u93594399";
(1)将超过5个数字替换成"#"。
String regex="\\d{5,}";
str.replaceAll(regex,"#");
(2)将叠词替换成单个词。
Stirng regex="(.)\\1+";
str.replaceAll(regex,"$1");
Ps:$也是获取组的符号。
(4)获取。
将字符串中符合规则的子串取出。
这个功能必须要用到java.util.regex包中的Pattern类和Matcher类。
Pattern类中没有构造方法。
操作步骤:
1)将正则表达式封装成对象。
Pattern类中的方法:
static Pattern compile(String regex):将给定的正则表达式编译到模式中。
2)让正则对象和要操作的字符串相关联。关联后,获取正则匹配引擎。
Pattern类中的方法:
Macher matcher(CharSequence input):创建匹配给定输入与此模式的匹配器。
3)通过引擎对符合规则的子串进行操作,比如取出。
Macher类中的方法:
boolean find():尝试查找与该模式匹配的输入序列的下一个子序列。
String group():返回由以前匹配操作所匹配的输入子序列。即符合规则的字符子串。
int start():返回以前匹配的初始索引。即符合规则的字符子串的初始位置。
int end():返回最后匹配字符之后的偏移量。即符合规则的字符子串的结束位置。
ps:拿到匹配器对象,就可以对字符串进行很多操作。比如:
matches(),其实String类中的matches方法,用的就是Pattern和Matcher对象来完成的。只不过被String的方法封装后,用起来较为简单。但是功能却单一。
下面用代码来体现:
需求:现在想获取一行字符串中三个字母组成的单词。
import java.util.regex.*;
class GetDemo
{
public static void main(String[] args)
{
getDemo();
}
public static void getDemo()
{
String str="main ini fidn jai jain jij";
/*"\b":是一个表示单词边界的字符。属于边界匹配器。*/
String regex="\\b[a-z]{4}\\b";
//1.将正则表达式封装成对象。
Pattern p=Pattern.compile(regex);
//2.将正则对象和要作用的字符串相关联,获取匹配器对象。
Matcher m=p.matcher(str);
//3.对通过匹配器对象对字符串进行操作。
/*
boolean flag1=m.find();
System.out.println(flag1);
String str1=m.group();
System.out.println(str1);
boolean flag2=m.find();
System.out.println(flag2);
String str2=m.group();
System.out.println(str2);
boolean flag3=m.find();
System.out.println(flag3);
String str3=m.group();
System.out.println(str3);
*/
while(m.find())
{
System.out.println(m.group());
System.out.println(m.start()+"...."+m.end());
}
}
}
运行结果:
这里注意一个小问题:
import java.util.regex.*;
class GetDemo
{
public static void main(String[] args)
{
getDemo();
}
public static void getDemo()
{
String str="main ini fidn jai jain jij";
/*"\b":是一个表示单词边界的字符。属于边界匹配器。*/
String regex="\\b[a-z]{4}\\b";
//1.将正则表达式封装成对象。
Pattern p=Pattern.compile(regex);
//2.将正则对象和要作用的字符串相关联,获取匹配器对象。
Matcher m=p.matcher(str);
//3.对通过匹配器对象对字符串进行操作。
System.out.println("matches:"+m.matches());
while(m.find())
{
System.out.println(m.group());
System.out.println(m.start()+"...."+m.end());
}
}
}
加了这句话之后,运行结果如下:
同一个匹配器的时候,它用的是同一个指针。m.matches()匹配失败以后,进入循环以后,指针就进入下一个单词进行匹配判断了。
3、正则表达式(练习)
(1)将下列字符串转化成:我要学编程。
String str="我我....我我....我要...要要..要要..学学学..学学..学.. 编编..编编....程程....程程程....程";
import java.util.regex.*;
class RegexDemo
{
public static void main(String[] args)
{
String str=
"我我....我我....我要...要要..学学..学..编编....程程....程";
/*
思路:将已有字符串变成另一个字符串。使用替换功能。
1.将"."去掉。
2.将多个相同字符变成单个字符。
*/
str=str.replaceAll("\\.","");
System.out.println(str);
str=str.replaceAll("(.)\\1+","$1");
System.out.println(str);
}
}
运行结果:
(2)将下列ip地址进行地址段顺序的排序。
192.68.1.254 102.49.23.0 12.3.56.2 2.4.5.7
import java.util.regex.*;
import java.util.*;
class RegexDemo
{
public static void main(String[] args)
{
/*
还按照字符串自然顺序,只要让它们每一段都是3位即可。
1、按照每一段需要的最多的0进行补齐,那么每一段就会
至少保留有3位。
2、将每一段只保留3位。这样,所有的ip地址都是每一段3位。
*/
String str="192.68.1.254 102.49.23.0 12.3.56.2 2.4.5.7";
str=str.replaceAll("(\\d+)","00$1");
System.out.println(str);
str=str.replaceAll("0*(\\d{3})","$1");
System.out.println(str);
String[] arr=str.split(" +");
TreeSet<String> ts=new TreeSet<String>();
for(String s:arr)
{
ts.add(s);
}
for(String s:ts)
{
System.out.println(s.replaceAll("0*(\\d+)","$1"));
}
}
}
运行结果:
(3)定义规则对邮件地址进行校验。
1)较为精确的匹配。
import java.util.regex.*;
import java.util.*;
class RegexDemo
{
public static void main(String[] args)
{
/*
String str="34A5a25@sina.com";
String regex="[a-zA-z_0-9]+@[a-zA-z_0-9]+\\.[a-zA-z]+";
System.out.println(str.matches(regex));
str="34A5a25@sina.com.cn";
regex="[a-zA-z_0-9]+@[a-zA-z_0-9]+\\.[a-zA-z]+\\.[a-zA-Z]+";
System.out.println(str.matches(regex));
*/
String str="34A5a25@sina.com.cn";
String regex="[a-zA-z_0-9]+@[a-zA-z_0-9]+(\\.[a-zA-z]+)+";
System.out.println(str.matches(regex));
}
}
2)较为不精确的匹配。
import java.util.regex.*;
import java.util.*;
class RegexDemo
{
public static void main(String[] args)
{
String str="34A5a25@sina.com.cn";
//String regex="[a-zA-z_0-9]+@[a-zA-z_0-9]+(\\.[a-zA-z]+)+"
String regex="\\w+@\\w+(\\.\\w+)+";
System.out.println(str.matches(regex));
}
}
4、拓展:正则表达式在网页爬虫中的应用
什么是网页爬虫呢?
所谓的网页爬虫(蜘蛛):一段小程序(功能),去爬互联网上的一些指定信息。但是,爬虫之前得有数据源。
下面我们说一个较实际的需求:
互联网兴起以后,很多人想打广告,想让很多人知道我这个网站,但是我不想花更多的前,想找一些小公司获或者找个人来做。个人怎么做的呢?就是发垃圾邮件,这种方式比较直观一点,就是说我给你发到邮箱里边去,你点开邮箱以后呢,你就愿意去看这个网站,你只要一点,我这个网站就可以赚钱了。那么有个问题就是,我们得搞个邮箱啊。早期那帮哥们就自己算邮箱,怎么算呢,就是用随机的方式或者顺序的方式去产生,如ABC1、ABC2、ABC3等用户名,这样就算出邮箱来,紧接着写个邮件程序,往这一匹邮箱里发指定的广告页面。可是算了好多个邮箱,只有几个是已经被注册过了,是有用的,又很多邮箱是没注册过的,是废的,中奖率不高,因此,就想去互联网上去获取一匹已经存在的邮箱。怎么获取呢?我们知道,网络上有很多邮箱地址怎么来的呢?比如,去技术论坛发帖看帖的时候就会看到这种现象:“各位坛友们,我手里边有本java葵花宝典,那位需要,请留下邮箱”。于是,下面就会有很多人要,并且留下了邮箱,那哥们就将所有的邮箱都复制过来放在自己的邮件里边去,来个群发。那么这个论坛的网页是有很多邮箱地址,搞一个爬虫过去,把网页获取到以后把里边的数据一行行扫,把凡是符合邮箱的数据全取出。这些邮箱地址都是真实的,可用的,存在的。这个就是爬邮箱的实例,还可以爬其他的东西。百度就是做这个的。
假设我现在有c盘下有一个.html文件,文件中有好多行文字,文字里边呢也有很多邮箱地址。我们想将这个文件中的邮箱地址取出来。
import java.io.*;
import java.util.regex.*;
class PachonDemo
{
public static void main(String[] args)throws Exception
{
BufferedReader bufr=
new BufferedReader(new FileReader("C:\\mail.txt"));
String regex="\\w+@\\w+(\\.\\w+)+";
Pattern p=Pattern.compile(regex);
String line=null;
while((line=bufr.readLine())!=null)
{
Matcher m=p.matcher(line);
while(m.find())
{
System.out.println(m.group());
}
}
}
}
拓展:如果这个文件是网络上的呢?即数据源从网络上获取。
我们先将这个html格式的文件放在tomcat服务器上。如:放在F:\tomcat\webapps\myweb目录下。将tomcat服务器打开。
编写代码,然后运行,就可以出现想要的结果。
import java.io.*;
import java.util.regex.*;
class PachonDemo
{
public static void main(String[] args)throws Exception
{
URL url=new URL("http://127.0.0.1:8080/myweb/demo.html");
Connection conn=url.openConnection();
BufferedReader bufr=
new BufferedReader(new InputStreamReader(conn.getInputStream()));
String regex="\\w+@\\w+(\\.\\w+)+";
Pattern p=Pattern.compile(regex);
String line=null;
while((line=bufr.readLine())!=null)
{
Matcher m=p.matcher(line);
while(m.find())
{
System.out.println(m.group());
}
}
}
}
2016-04-23至
2016-04-24著

相关文章推荐
- Gradle 笔记——Java构建入门
- 使用 Git 改进工作方式
- 我的学习之路-JAVA-01
- 20145308刘昊阳 《Java程序设计》第8周学习总结
- MyEclipse做的项目导入到Eclipse中错误
- spring aop的xml配置详解
- eclipse开发velocity实例(初学)
- 《Java程序设计》第8周学习总结
- 关于Java的散列桶, 以及附上一个案例-重写map集合
- Dubbo与Zookeeper、SpringMVC整合和使用(负载均衡、容错)(转)
- JAVA模式之责任链模式
- 20145229吴姗珊 《Java程序设计》第8周学习总结
- spring 技术内幕--IOC
- Spring总结3—AOP
- javaGC机制之我见
- Spring官网下载dist.zip的几种方法
- 20145315 《Java程序设计》实验三实验报告
- java代理机制
- spring mvc CommonsMultipartResolver文件上传maxUploadSize限制大小
- java毕向东听课笔记25(集合框架-Set集合TreeSet)