Google数据中心B4网络具体实现
2016-04-22 11:21
423 查看
① 背景介绍
Google的网络有两种,一种是数据中心内部网络,另外一种是WAN网,其中WAN网又分为两种:一是数据中心之间的互联网络,属于内部网络(G-Scale Network),另外一种是面向Internet用户访问的网络(Internet-facing WAN 即 I-Scale Network),Google选择使用基于SDN来改造数据中心之间互联的G-Scale网络,因为这个网络相对简单,设备类型以及功能都比较单一,而且该网络的链路成本太高(都是长距离传输光缆,甚至包括海底光缆),改造价值大。Google的数据中心之间传输的数据可以分为三大类:
用户数据备份 到远程数据中心,以保证数据可用性和持久性。这个数据量最小,对延迟最敏感,优先级最高。
扩数据中心存储访问 比如据算资源和存储资源分布在不同的数据中心,进行 MapReduce 之类的分布式计算。
大规模数据同步 以同步多个数据中心之间的状态。这个流量最大,对延迟不敏感,优先级最低。
促使Google使用SDN改造WAN网络的最大原因是当前连接WAN网络的链路带宽利用率很低,因为现在用的是基于静态Hash的负载均衡方式,这种方式并不是绝对均衡,会出现有的路径负载高,有的路径负载低的情况,为了避免很大的流量都被分发到同一个链路上导致对包,Google不得不使用过量链路,提供比实际需要多得多的带宽,导致实际链路带宽利用率只有30%左右,且仍不可避免有些链路会发生拥塞,而且设备必须支持很大的包缓存,成本太高。除此之外,增加网络可见性、稳定性,简化管理,都是动机之一。以上原因也决定了Google这个基于SDN的网络,最主要的应用时流量工程(TE,Traffic Engineering)。
Google对B4网络的改造方法,充分考虑了他们网络的一些特性以及想用达到的主要目标,一切都是围绕这几个事实或者期望:
B4网络绝大多数流量都是来自于数据中心之间的数据同步应用,这些应用希望给它们的带宽越大越好,但是可以容忍偶尔的拥塞丢包、链路不通以及高延时。
Google数据中心的数量是有限的,这个特点意味着Controller的可扩展性的压力相对小很多。
Google能够控制应用数据以及每个数据中心的边界网络,希望通过控制应用数据的优先级和网络边缘的突发流量(Burst)来优化路径,缓解带宽压力,而不是靠无限制地增大出口带宽。
② 具体实现
控制该网络的系统分为三个层次:物理设备层(Switch Hardware)、局部网络控制层(Site Controller)和全局控制层(global)。一个Site就是一各数据中心。第一层的硬件交换机和第二层的Controller在每个数据中心的内部出口的地方都有部署,而第三层的SDN网关和TE服务器则是在一个全局统一的控制器。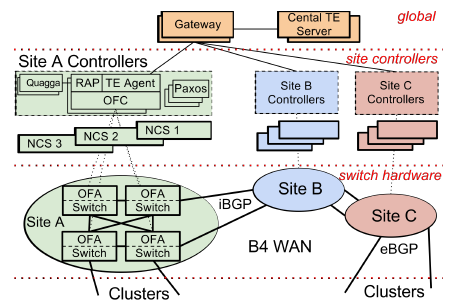

● 第一层的硬件交换机是Google自己设计的。交换机里面运行了OpenFlow协议,但是它并非仅仅使用了一般的OpenFlow交换机最常使用的ACL表,而是用了TTP(Table Typing Patterns)方式,包括ACL表、路由表、Tunnel表等。但是向上提供的是OpenFlow接口。这些交换机会把BGP/IS-IS协议报文发送到Controller供Controller处理。
● 第二层最为复杂,该层在每个数据中心出口并不是只有一台服务器,而是有一个服务器集群,每个服务器上都运行一个Controller,Google用的Controller是基于分布式的Onix Controller来改造的。一台交换机可以连接到多个Controller,但是只有其中一个处于工作状态(Master),一个控制器控制多台交换机,一个名叫Paxos的程序用来进行leader选举(即选举Master)。
在Controller之上运行着两个应用:RAP,TE Agent。
RAP即Routing Application Proxy的意思,负责OFA和OFC之间的互联,作为SDN应用跟Quagga通信。Quagga是一个开源的三层路由协议栈,支持很多路由协议,Google使用了BGP和IS-IS。数据中心内部的路由器间运行eBGP,跟其它数据中心WAN中的设备间运行iBGP。Onix Controller收到下面交换机送上来的路由协议报文以及链路状态变化通知的时候,自己并不处理,而是通过RAP把它送给Quagga协议栈。Controller会把它所管理的所有交换机的端口信息都通过RAP告诉Quagga,Quagga协议栈惯例了所有这些端口。Quagga协议计算出来的路由会在Controller里面保留一份(放在一个叫NIB的数据库里面,即Network Information Base,类似于传统路由中的RIB),同时会下发给交换机,路由的下一跳可以是ECMP,即有多个等价下一跳,通过Hash选择一个出口。这是最标准的路由传统路由转发
/360/360se6/User Data/temp/81bd2f4170c64ccede2f1757137e9b941.png)
。
Quagga 路由协议栈中的 RIB 保存着路由规则,如发往某个子网的包要从某两个端口选一个出去。数据中心网络中一个 packet 一般会有多条路线可走,一方面提高冗余度,一方面充分利用带宽,常用的协议是 Equal Cost Multiple Path (ECMP),即如果有多条最短路,就从其中随机选一条走。在OFC中,RIB被分解为 Flows和 Groups。要理解这个拆分的必要性,先要理解网络交换设备是怎样工作的。现代网络交换设备的核心是 match-action table。Match 部分就是 Content Addressable Memory (CAM),所有条目可以并行地匹配,匹配结果经过 Mux 选出优先级最高的一条;Action 则是对数据包进行的动作,比如修改包头、减少 TTL、送到哪个端口、丢弃数据包。在 OFC 中,Flows 对应着 Match 部分,匹配得出 Action 规则编号;Groups 对应着 Action 部分,采用交换机中现有的 ECMP Hash 支持,随机选择一个出口。
TE Agent,负责跟全局的Gateway通信,每个OpenFlow交换机的链路状态(包括带宽信息)会通过TE Agent发送给全局的Gateway,Gateway汇总后送给TE Server进行路径计算。
● 第三层中,全局的TE服务器通过SDN Gateway从各个数据中心的控制器收集链路信息,从而掌握路径信息,这些路径被以IP-In-IP Tunnel的方式创建而不是TE最经常使用的MPLS Tunnel,通过Gateway到Onix Controller,最终下发到交换机中。当一个新业务数据要开始传输的时候,应用程序会评估该应用所需要耗用的带宽,为它选择一条最优路径(比如负载最轻的但非最短路径即不丢包但时延大),然后把这个应用对应的流通过Controller下发到交换机,从而整体上使链路带宽利用率到达最优。

相关文章推荐
- 内容来至(http://blog.csdn.net/dadaadao/rss/list)
- python 创建httpserver
- HttpServletRequest学习
- tcpdump来抓取执行的sql语句
- TCP三次握手
- Linux 内核态 Socket TCP 编程
- iOS应用网络安全之HTTPS
- 解决方案 错误:HttpServlet was not found on the Java build path
- kindeditor富文本注释掉上传网络图片
- Http协议与TCP协议简单理解
- 揪出bug!解析调试神经网络的技巧
- HttpWebRequest操作已超时
- HttpClient返回403 forbiddenn问题
- XMLHttpRequest
- SIP协议之场景分析
- nginx ssL +tomcat实现https
- 几种开放源代码的TCPIP协议栈分析
- OkHttp
- TCP socket的accept/connect成功返回可是对端却不辞而别
- uva 10806 Dijkstra, Dijkstra. dj和网络