struts2、hibernate工作原理和流程
2016-04-21 00:00
155 查看
摘要: 在struts2的应用中,从用户请求到服务器返回相应响应给用户端的过程中,包含了许多组件如:Controller、ActionProxy、ActionMapping、Configuration Manager、ActionInvocation、Inerceptor、Action、Result等。
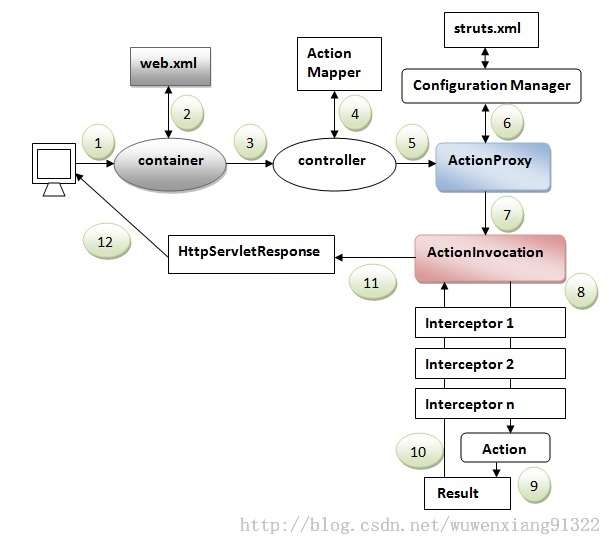
(1) 客户端(Client)向Action发用一个请求(Request)
(2) Container通过web.xml映射请求,并获得控制器(Controller)的名字
(3) 容器(Container)调用控制器(StrutsPrepareAndExecuteFilter或FilterDispatcher)。在 Struts2.1以前调用FilterDispatcher,Struts2.1以后调用 StrutsPrepareAndExecuteFilter
(4) 控制器(Controller)通过ActionMapper获得Action的信息
(5) 控制器(Controller)调用ActionProxy
(6) ActionProxy读取struts.xml文件获取action和interceptor stack的信息。
(7) ActionProxy把request请求传递给ActionInvocation
(8) ActionInvocation依次调用action和interceptor
(9) 根据action的配置信息,产生result
(10) Result信息返回给ActionInvocation
(11) 产生一个HttpServletResponse响应
(12) 产生的响应行为发送给客服端。
视图:主要由JSP生成页面完成视图,Struts提供丰富的JSP 标签库: Html,Bean,Logic,Template等,这有利于分开在Struts中,承担MVC中Controller角色的是一个Servlet,叫 ActionServlet。ActionServlet是一个通用的控制组件。这个控制组件提供了处理所有发送到Struts的HTTP请求的入口点。 它截取和分发这些请求到相应的动作类(这些动作类都是Action类的子类)。另外控制组件也负责用相应的请求参数填充 Action From(通常称之为FromBean),并传给动作类(通常称之为ActionBean)。动作类实现核心商业逻辑,它可以访问Java bean 或调用EJB。最后动作类把控制权传给后续的JSP 文件,后者生成视图。所有这些控制逻辑利用Struts-config.xml文件来配置。表现逻辑和程序逻辑。
模型:模型以一个或多个java bean的形式存在。这些bean分为三类:Action Form、Action、JavaBean or EJB。Action Form通常称之为FormBean,封装了来自于Client的用户请求信息,如表单信息。Action通常称之为ActionBean,获取从 ActionSevlet传来的FormBean,取出FormBean中的相关信息,并做出相关的处理,一般是调用Java Bean或EJB等。
流程:在Struts中,用户的请求一般以.do作为请求服务名,所有的.do 请求均被指向ActionSevlet,ActionSevlet根据Struts-config.xml中的配置信息,将用户请求封装成一个指定名称的 FormBean,并将此FormBean传至指定名称的ActionBean,由ActionBean完成相应的业务操作,如文件操作,数据库操作等。每一个*.do均有对应的FormBean名称和ActionBean名称,这些在Struts-config.xml中配置。
Struts2和struts1的比较
struts2相对于struts1来说简单了很多,并且功能强大了很多,我们可以从几个方面来看:
从体系结构来看:struts2大量使用拦截器来出来请求,从而允许与业务逻辑控制器 与 servlet-api分离,避免了侵入性;而struts1.x在action中明显的侵入了servlet-api.
从线程安全分析:struts2.x是线程安全的,每一个对象产生一个实例,避免了线程安全问题;而struts1.x在action中属于单线程。
性能方面:struts2.x测试可以脱离web容器,而struts1.x依赖servlet-api,测试需要依赖web容器。
请求参数封装对比:struts2.x使用ModelDriven模式,这样我们 直接 封装model对象,无需要继承任何struts2的基类,避免了侵入性。
标签的优势:标签库几乎可以完全替代JSTL的标签库,并且 struts2.x支持强大的ognl表达式。
当然,struts2和struts1相比,在 文件上传,数据校验 等方面也 方便了好多。在这就不详谈了。
hibernate是一个开源框架,它是对象关联关系映射的框架,它对JDBC做了轻量级的封装,而我们java程序员可以使用面向对象的思想来操纵数据库。
hibernate核心接口
session:负责被持久化对象CRUD操作
sessionFactory:负责初始化hibernate,创建session对象
configuration:负责配置并启动hibernate,创建SessionFactory
Transaction:负责事物相关的操作
Query和Criteria接口:负责执行各种数据库查询
hibernate工作原理:
1.通过Configuration config = new Configuration().configure();//读取并解析hibernate.cfg.xml配置文件
2.由hibernate.cfg.xml中的读取并解析映射信息
3.通过SessionFactory sf = config.buildSessionFactory();//创建SessionFactory
4.Session session = sf.openSession();//打开Sesssion
5.Transaction tx = session.beginTransaction();//创建并启动事务Transation
6.persistent operate操作数据,持久化操作
7.tx.commit();//提交事务
8.关闭Session
9.关闭SesstionFactory
为什么要用hibernate:
1. 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
2. Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
3. hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
4. hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
Hibernate是如何延迟加载?get与load的区别
对于Hibernate get方法,Hibernate会确认一下该id对应的数据是否存在,首先在session缓存中查找,然后在二级缓存中查找,还没有就查询数据库,数据 库中没有就返回null。
Hibernate load方法加载实体对象的时候,根据映射文件上类级别的lazy属性的配置(默认为true),分情况讨论:
(1)若为true,则首先在Session缓存中查找,看看该id对应的对象是否存在,不存在则使用延迟加载,返回实体的代理类对象(该代理类为实体类 的子类,由CGLIB动态生成)。等到具体使用该对象(除获取OID以外)的时候,再查询二级缓存和数据库,若仍没发现符合条件的记录,则会抛出一个 ObjectNotFoundException。
(2)若为false,就跟Hibernateget方法查找顺序一样,只是最终若没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
这里get和load有两个重要区别:
如果未能发现符合条件的记录,Hibernate get方法返回null,而load方法会抛出一个ObjectNotFoundException。
load方法可返回没有加载实体数据的代 理类实例,而get方法永远返回有实体数据的对象。
总之对于get和load的根本区别,一句话,hibernate对于 load方法认为该数据在数据库中一定存在,可以放心的使用代理来延迟加载,如果在使用过程中发现了问题,只能抛异常;而对于get方 法,hibernate一定要获取到真实的数据,否则返回null。
Hibernate中怎样实现类之间的关系?(如:一对多、多对多的关系)
类与类之间的关系主要体现在表与表之间的关系进行操作,它们都是对对象进行操作,我们程序中把所有的表与类都映射在一起,它们通过配置文件中的many-to-one、one-to-many、many-to-many、
说下Hibernate的缓存机制:
Hibernate缓存的作用:
Hibernate是一个持久层框架,经常访问物理数据库,为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据
Hibernate缓存分类:
Hibernate缓存包括两大类:Hibernate一级缓存和Hibernate二级缓存
Hibernate一级缓存又称为“Session的缓存”,它是内置的,意思就是说,只要你使用hibernate就必须使用session缓存。由于 Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是事务范围的缓存。在第一级缓存中,持久化类的每个实例都具有唯一的 OID。
Hibernate二级缓存又称为“SessionFactory的缓存”,由于SessionFactory对象的生命周期和应用程序的整个过程对应, 因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔 离级别。第二级缓存是可选的,是一个可配置的插件,在默认情况下,SessionFactory不会启用这个插件。
什么样的数据适合存放到第二级缓存中?
1 很少被修改的数据
2 不是很重要的数据,允许出现偶尔并发的数据
3 不会被并发访问的数据
4 常量数据
不适合存放到第二级缓存的数据?
1经常被修改的数据
2 .绝对不允许出现并发访问的数据,如财务数据,绝对不允许出现并发
3 与其他应用共享的数据。
Hibernate查找对象如何应用缓存?
当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查;查不到,如果配置了二级缓存,那么从二级缓存中查;如果都查不到,再查询数据库,把结果按照ID放入到缓存
删除、更新、增加数据的时候,同时更新缓存
Hibernate管理缓存实例
无论何时,我们在管理Hibernate缓存(Managing the caches)时,当你给save()、update()或saveOrUpdate()方法传递一个对象时,或使用load()、 get()、list()、iterate() 或scroll()方法获得一个对象时, 该对象都将被加入到Session的内部缓存中。
当随后flush()方法被调用时,对象的状态会和数据库取得同步。 如果你不希望此同步操作发生,或者你正处理大量对象、需要对有效管理内存时,你可以调用evict() 方法,从一级缓存中去掉这些对象及其集合。
Hibernate的查询方式
Sql、Criteria,object comptosition
Hql:
1、 属性查询
2、 参数查询、命名参数查询
3、 关联查询
4、 分页查询
5、 统计函数
如何优化Hibernate?
1.使用双向一对多关联,不使用单向一对多
2.灵活使用单向一对多关联
3.不用一对一,用多对一取代
4.配置对象缓存,不使用集合缓存
5.一对多集合使用Bag,多对多集合使用Set
6. 继承类使用显式多态
7. 表字段要少,表关联不要怕多,有二级缓存撑腰
hibernate的开发步骤:
开发步骤
1)搭建好环境
引入hibernate最小的jar包
准备Hibernate.cfg.xml启动配置文件
2)写实体类(pojo)
3)为实体类写映射文件”User.hbm.xml”
在hibernate.cfg.xml添加映射的实体
4)创建库表
5)写测试类
获得Configuration
创建SessionFactory
打开Session
开启事务
使用session操作数据
提交事务
关闭资源
struts2原理
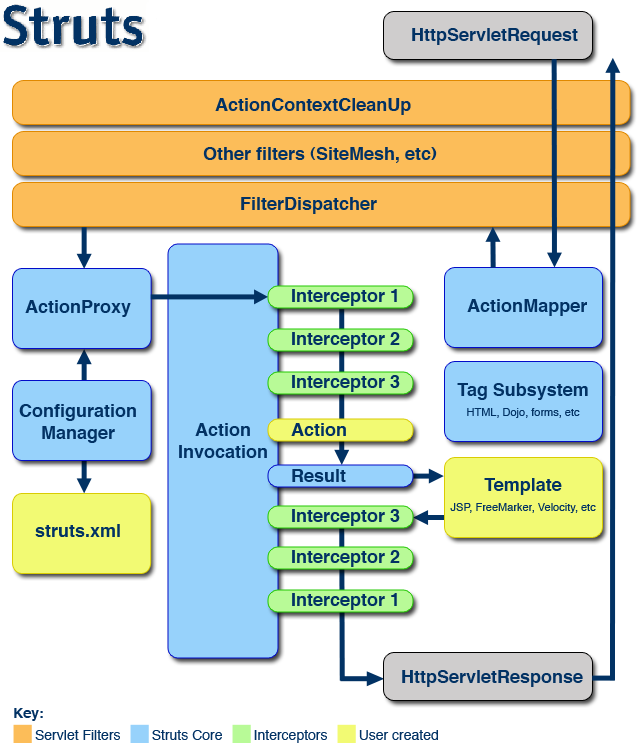
在struts2的应用中,从用户请求到服务器返回相应响应给用户端的过程中,包含了许多组件如:Controller、ActionProxy、 ActionMapping、Configuration Manager、ActionInvocation、Inerceptor、Action、Result等。(1) 客户端(Client)向Action发用一个请求(Request)
(2) Container通过web.xml映射请求,并获得控制器(Controller)的名字
(3) 容器(Container)调用控制器(StrutsPrepareAndExecuteFilter或FilterDispatcher)。在 Struts2.1以前调用FilterDispatcher,Struts2.1以后调用 StrutsPrepareAndExecuteFilter
(4) 控制器(Controller)通过ActionMapper获得Action的信息
(5) 控制器(Controller)调用ActionProxy
(6) ActionProxy读取struts.xml文件获取action和interceptor stack的信息。
(7) ActionProxy把request请求传递给ActionInvocation
(8) ActionInvocation依次调用action和interceptor
(9) 根据action的配置信息,产生result
(10) Result信息返回给ActionInvocation
(11) 产生一个HttpServletResponse响应
(12) 产生的响应行为发送给客服端。
视图:主要由JSP生成页面完成视图,Struts提供丰富的JSP 标签库: Html,Bean,Logic,Template等,这有利于分开在Struts中,承担MVC中Controller角色的是一个Servlet,叫 ActionServlet。ActionServlet是一个通用的控制组件。这个控制组件提供了处理所有发送到Struts的HTTP请求的入口点。 它截取和分发这些请求到相应的动作类(这些动作类都是Action类的子类)。另外控制组件也负责用相应的请求参数填充 Action From(通常称之为FromBean),并传给动作类(通常称之为ActionBean)。动作类实现核心商业逻辑,它可以访问Java bean 或调用EJB。最后动作类把控制权传给后续的JSP 文件,后者生成视图。所有这些控制逻辑利用Struts-config.xml文件来配置。表现逻辑和程序逻辑。
模型:模型以一个或多个java bean的形式存在。这些bean分为三类:Action Form、Action、JavaBean or EJB。Action Form通常称之为FormBean,封装了来自于Client的用户请求信息,如表单信息。Action通常称之为ActionBean,获取从 ActionSevlet传来的FormBean,取出FormBean中的相关信息,并做出相关的处理,一般是调用Java Bean或EJB等。
流程:在Struts中,用户的请求一般以.do作为请求服务名,所有的.do 请求均被指向ActionSevlet,ActionSevlet根据Struts-config.xml中的配置信息,将用户请求封装成一个指定名称的 FormBean,并将此FormBean传至指定名称的ActionBean,由ActionBean完成相应的业务操作,如文件操作,数据库操作等。每一个*.do均有对应的FormBean名称和ActionBean名称,这些在Struts-config.xml中配置。
Struts2和struts1的比较
struts2相对于struts1来说简单了很多,并且功能强大了很多,我们可以从几个方面来看:
从体系结构来看:struts2大量使用拦截器来出来请求,从而允许与业务逻辑控制器 与 servlet-api分离,避免了侵入性;而struts1.x在action中明显的侵入了servlet-api.
从线程安全分析:struts2.x是线程安全的,每一个对象产生一个实例,避免了线程安全问题;而struts1.x在action中属于单线程。
性能方面:struts2.x测试可以脱离web容器,而struts1.x依赖servlet-api,测试需要依赖web容器。
请求参数封装对比:struts2.x使用ModelDriven模式,这样我们 直接 封装model对象,无需要继承任何struts2的基类,避免了侵入性。
标签的优势:标签库几乎可以完全替代JSTL的标签库,并且 struts2.x支持强大的ognl表达式。
当然,struts2和struts1相比,在 文件上传,数据校验 等方面也 方便了好多。在这就不详谈了。
hibernate原理
hibernate 简介:hibernate是一个开源框架,它是对象关联关系映射的框架,它对JDBC做了轻量级的封装,而我们java程序员可以使用面向对象的思想来操纵数据库。
hibernate核心接口
session:负责被持久化对象CRUD操作
sessionFactory:负责初始化hibernate,创建session对象
configuration:负责配置并启动hibernate,创建SessionFactory
Transaction:负责事物相关的操作
Query和Criteria接口:负责执行各种数据库查询
hibernate工作原理:
1.通过Configuration config = new Configuration().configure();//读取并解析hibernate.cfg.xml配置文件
2.由hibernate.cfg.xml中的读取并解析映射信息
3.通过SessionFactory sf = config.buildSessionFactory();//创建SessionFactory
4.Session session = sf.openSession();//打开Sesssion
5.Transaction tx = session.beginTransaction();//创建并启动事务Transation
6.persistent operate操作数据,持久化操作
7.tx.commit();//提交事务
8.关闭Session
9.关闭SesstionFactory
为什么要用hibernate:
1. 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
2. Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
3. hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
4. hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
Hibernate是如何延迟加载?get与load的区别
对于Hibernate get方法,Hibernate会确认一下该id对应的数据是否存在,首先在session缓存中查找,然后在二级缓存中查找,还没有就查询数据库,数据 库中没有就返回null。
Hibernate load方法加载实体对象的时候,根据映射文件上类级别的lazy属性的配置(默认为true),分情况讨论:
(1)若为true,则首先在Session缓存中查找,看看该id对应的对象是否存在,不存在则使用延迟加载,返回实体的代理类对象(该代理类为实体类 的子类,由CGLIB动态生成)。等到具体使用该对象(除获取OID以外)的时候,再查询二级缓存和数据库,若仍没发现符合条件的记录,则会抛出一个 ObjectNotFoundException。
(2)若为false,就跟Hibernateget方法查找顺序一样,只是最终若没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
这里get和load有两个重要区别:
如果未能发现符合条件的记录,Hibernate get方法返回null,而load方法会抛出一个ObjectNotFoundException。
load方法可返回没有加载实体数据的代 理类实例,而get方法永远返回有实体数据的对象。
总之对于get和load的根本区别,一句话,hibernate对于 load方法认为该数据在数据库中一定存在,可以放心的使用代理来延迟加载,如果在使用过程中发现了问题,只能抛异常;而对于get方 法,hibernate一定要获取到真实的数据,否则返回null。
Hibernate中怎样实现类之间的关系?(如:一对多、多对多的关系)
类与类之间的关系主要体现在表与表之间的关系进行操作,它们都是对对象进行操作,我们程序中把所有的表与类都映射在一起,它们通过配置文件中的many-to-one、one-to-many、many-to-many、
说下Hibernate的缓存机制:
Hibernate缓存的作用:
Hibernate是一个持久层框架,经常访问物理数据库,为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据
Hibernate缓存分类:
Hibernate缓存包括两大类:Hibernate一级缓存和Hibernate二级缓存
Hibernate一级缓存又称为“Session的缓存”,它是内置的,意思就是说,只要你使用hibernate就必须使用session缓存。由于 Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是事务范围的缓存。在第一级缓存中,持久化类的每个实例都具有唯一的 OID。
Hibernate二级缓存又称为“SessionFactory的缓存”,由于SessionFactory对象的生命周期和应用程序的整个过程对应, 因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔 离级别。第二级缓存是可选的,是一个可配置的插件,在默认情况下,SessionFactory不会启用这个插件。
什么样的数据适合存放到第二级缓存中?
1 很少被修改的数据
2 不是很重要的数据,允许出现偶尔并发的数据
3 不会被并发访问的数据
4 常量数据
不适合存放到第二级缓存的数据?
1经常被修改的数据
2 .绝对不允许出现并发访问的数据,如财务数据,绝对不允许出现并发
3 与其他应用共享的数据。
Hibernate查找对象如何应用缓存?
当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查;查不到,如果配置了二级缓存,那么从二级缓存中查;如果都查不到,再查询数据库,把结果按照ID放入到缓存
删除、更新、增加数据的时候,同时更新缓存
Hibernate管理缓存实例
无论何时,我们在管理Hibernate缓存(Managing the caches)时,当你给save()、update()或saveOrUpdate()方法传递一个对象时,或使用load()、 get()、list()、iterate() 或scroll()方法获得一个对象时, 该对象都将被加入到Session的内部缓存中。
当随后flush()方法被调用时,对象的状态会和数据库取得同步。 如果你不希望此同步操作发生,或者你正处理大量对象、需要对有效管理内存时,你可以调用evict() 方法,从一级缓存中去掉这些对象及其集合。
Hibernate的查询方式
Sql、Criteria,object comptosition
Hql:
1、 属性查询
2、 参数查询、命名参数查询
3、 关联查询
4、 分页查询
5、 统计函数
如何优化Hibernate?
1.使用双向一对多关联,不使用单向一对多
2.灵活使用单向一对多关联
3.不用一对一,用多对一取代
4.配置对象缓存,不使用集合缓存
5.一对多集合使用Bag,多对多集合使用Set
6. 继承类使用显式多态
7. 表字段要少,表关联不要怕多,有二级缓存撑腰
hibernate的开发步骤:
开发步骤
1)搭建好环境
引入hibernate最小的jar包
准备Hibernate.cfg.xml启动配置文件
2)写实体类(pojo)
3)为实体类写映射文件”User.hbm.xml”
在hibernate.cfg.xml添加映射的实体
4)创建库表
5)写测试类
获得Configuration
创建SessionFactory
打开Session
开启事务
使用session操作数据
提交事务
关闭资源

相关文章推荐
- struts2 jquery 打造无限层次的树
- 使用struts2+Ajax+jquery验证用户名是否已被注册
- struts2入门Demo示例
- 通过Ajax两种方式讲解Struts2接收数组表单的方法
- Hibernate Oracle sequence的使用技巧
- jsp Hibernate批量更新和批量删除处理代码
- jsp hibernate的分页代码第1/3页
- Struts2+Hibernate实现数据分页的方法
- Hibernate环境搭建与配置方法(Hello world配置文件版)
- ajax交互Struts2的action(客户端/服务器端)
- JAVA+Hibernate 无限级分类
- SSH整合中 hibernate托管给Spring得到SessionFactory
- jsp hibernate 数据保存操作的原理
- struts2 spring整合fieldError问题
- Struts2的s:radio标签使用及用jquery添加change事件
- hibernate中的增删改查实现代码
- 解决hibernate+mysql写入数据库乱码
- java优化hibernate性能的几点建议
- java Hibernate延迟加载
- 使用Hibernate