BP神经网络中的过拟合现象
2016-04-19 21:28
239 查看
现象
毕设:基于BP神经网络的网络病毒预测模型发现对历年数据进行拟合,拟合效果非常好,甚至已经和原始数据基本没有差别。如图(拟合误差不超过0.3%)
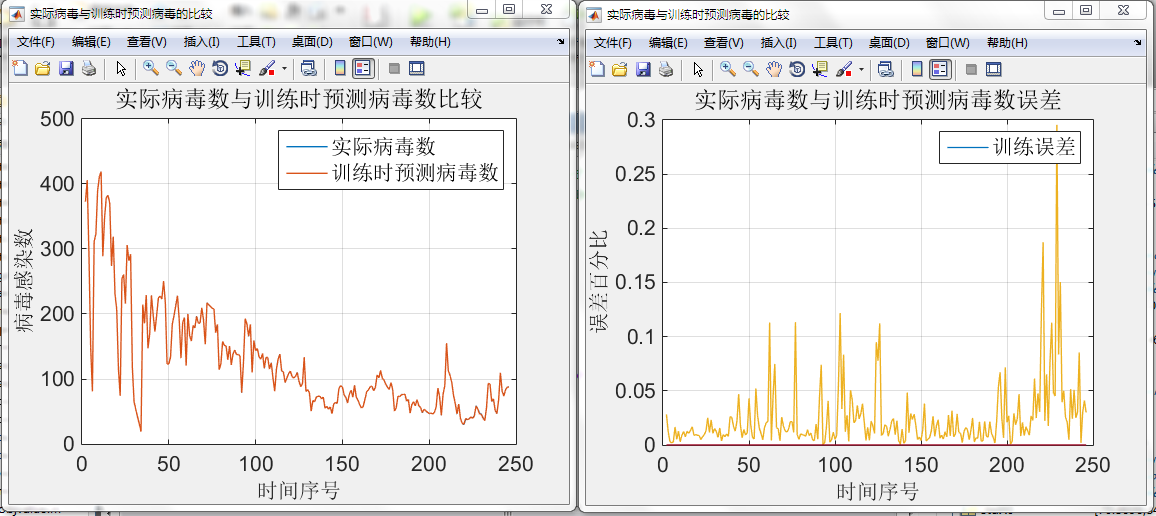
但是预测误差却大的吓人。
如图(最大甚至超过300%,不过刚开始误差基本控制在30%以内)
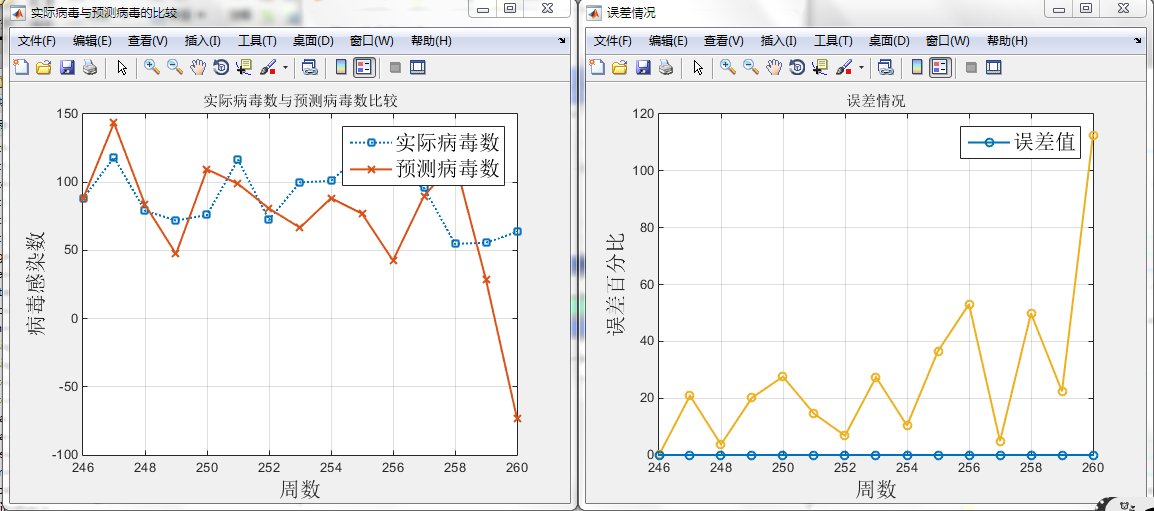
由于刚刚开始使用神经网络,对神经网络还存在一些误解甚至一些神化。我在今天以前一直认为“随着拟合精度的提高,预测的精度也会随着一起提高”而事实却给我了一记响亮的耳光。并不是这样的!!!
————————————————————————————
标准的BP神经网络的训练准则是要求所有样本的期望值与输出值的误差平方和(或者说是拟合误差)小于给定的足够小的允许误差e。一般,e越小拟合精度越高,网络的预测精度也越高。但实际应用表名:随着拟合误差的减小,开始预测误差也随着减小,但随着拟合误差减小到某个值之后,预测误差反而增大,说明泛化能力降低。这就是BP神经网络建模过程中遇到的“过拟合”现象。
查询论文得知防止“过拟合”现象有如下几种方法
1.调整法
2.提前停止法
3.隐层结点自动生成法
(PS:参考论文)
4.交叉验证的方法
在Matalab R2014B中主要使用了提前停止法来防止”过拟合”
我们在使用BP神经网络的时候如何防止“过拟合”呢?
(1)增加L1正则和L2正则
(2)增加训练样本数目
(3)减少模型的参数个数
(4)将训练方法改为trainbr(trainbr训练方法是改变了性能函数,其他方法的性能函数基本上是以训练样本误差方差,而trainbr训练方法则在其中加入了权值方值的和,此项是为了减少有效权值的个数。像你所说的贝叶斯算法是调整性能函数这两部分的比重)

相关文章推荐
- Android开发本地及网络Mp3音乐播放器(四)实现音乐播放
- Android开发本地及网络Mp3音乐播放器(四)实现音乐播放
- Android网络之数据解析----SAX方式解析XML数据
- Android系列之网络(二)----HTTP请求头与响应头
- Android系列之网络(三)----使用HttpClient发送HTTP请求(分别通过GET和POST方法发送数据)
- HTTP状态码302、303和307的故事
- Spark和Scala的网络资源汇集
- Exception in thread "http-bio-8089-exec-8" java.lang.OutOfMemoryError: PermGen space
- Android系列之网络(一)----使用HttpClient发送HTTP请求(通过get方法获取数据)
- 计算机网络——概述
- 倍福WinCE网络配置问题
- IOS网络入门-Socket套接字
- [网络流24题] 方格取数问题 (最大权独立集---网络最小割)
- Trigger script exited with code: 1 From https://github.com/CocoaPods/Specs 9967bbf..de7b3da master -
- https://dzone.com/articles/r-and-hadoop-data-analytics
- TCP/IP协议三次握手与四次握手流程解析
- HTTP调试 抓包 工具 Fiddle 简介 示例
- 计算机网络自顶向下方法之一一一第九章
- TCP相关面试题总结
- tomcat强制https访问