数据结构之并查集
2016-04-16 21:31
239 查看
1. 前言
在计算机科学中,并查集是一种树型的数据结构,其保持着用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。应用很多,如其求无向图的连通分量个数等。最完美的应用当属:实现Kruskar算法求最小生成树。在机试中遇到连通路问题没有做出来,回来寻找解决方法,遂记录之。下面大部分内容是从网上抄录的,网址已附上。2. 并查集的基本操作
有一个联合-查找算法(union-find algorithm)定义了两个操作用于此数据结构。1. Find:确定元素属于哪一个子集。其精髓是找到这个元素所在集合的祖先(这点从树中得来)!它可以被用来确定两个元素是否属于同一子集。祖先相同即即属于同一个集合。这个才是并查集判断和合并的最终依据。
举例来说:全国县长的上一级是市长,市长上一级是省长,省长上面有国家主席,所以无论从哪个县长都能追溯到国家主席,并查集中术语叫有相同祖先,县长们就是一个集合A。但是对于国外的底层官员向上级追溯就不可能追溯到我们的主席,叫做集合B。所以A,B就不是一个集合。(想以美帝举例,但是他们没有明显的上下级制约关系)
2. Union:将两个子集合并成同一个集合。
还是以上例说明,假如我党吞并了某国(此加入不成立违反我国外交政策),某国从上到下臣服于我国,祖先就是一个了,因此集合也就合并了
还有一个操作:
3. makeSet初始化:
初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变)。
3. 并查集的优化
1、Find_Set(x)时 路径压缩寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find_Set(x)都是O(n)的复杂度,因此我们想办法提高效率,这就是路径压缩,即当我们经过”递推”找到祖先节点后,”回溯”的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find_Set(x)时复杂度就变成O(1)了,如下图所示;可见,路径压缩方便了以后的查找。
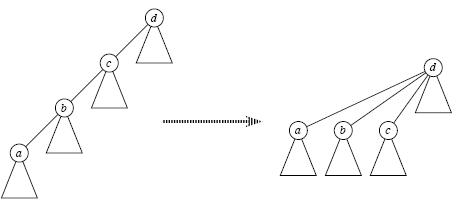
2、Union(x,y)时 按秩合并
即合并的时候将元素少的集合合并到元素多的集合中,这样合并之后树的高度会相对较小。
4. c++代码实现
class UFSet
{
public:
UFSet(int nsize)
{
size = nsize;
parent = new int[size];
};
~UFSet()
{
delete[] parent;
parent = NULL;
};
void makeSet(int n);////初始化每个元素的祖先为自身
int findSet(int x);//找到元素x的祖先元素
void unionSet(int a, int b);//若两个元素的祖先不同,则将x元素的祖先设置为y元素的祖先
int getSets(int n);//获取集合数量
private:
int *parent;//存放祖先节点,例如x=parent[i],元素i的祖先节点为元素x
int size;
};
void UFSet::makeSet(int n) //初始化
{
//初始化每一个元素都各自为一个独立的集合,其祖先均设定为自身
for (size_t i = 1; i <= n; i++)
parent[i] = i;
}
int UFSet::findSet(int x)
{
//找到元素所在的集合,也就是找到自己的最高的祖先,
//这也是判断两个元素是否在同一个集合中的主要依据。
if (parent[x] == x)
return x;
parent[x] = findSet(parent[x]);//找到祖先,而不是父节点
return parent[x];
}
void UFSet::unionSet(int x, int y)
{
//将x和y所在的集合进行合并,利用findSet()判断x和y所在的集合是否相同,
//如果不同,则要把其中一个元素的祖先指向另一个元素的祖先。
int ux = findSet(x);//获取节点x的祖先
int uy = findSet(y);
if (ux != uy)
parent[ux] = uy;
}
int UFSet::getSets(int n)
{
int count = 0;
for (int i = 1; i <= n; i++)
{//如果存在某一个节点的祖先是自身说明他是孤立的或者本身就是祖先
if (parent[i] == i)
count++;
}
return count;
}并查集的空间复杂度是 O(n) 的。find 和 union操作都可以看成是常数级的,或者准确来说,在一个包含 n 个元素的并查集中,进行 mm 次查找或合并操作,最坏情况下所需的时间为 O(mα(n)),这里的 α是 Ackerman 函数的某个反函数,在极大的范围内(比可观察到的宇宙中估计的原子数量 10801080 还大很多)都可以认为是不大于 4 的。
5. 应用举例
村庄修路成本问题。(华为实习生机试题类似)题目描述:
地区修路目标是使任何两个村庄间都可以实现公路交通(但不一定有直接的公路相连,只要能间接通过公路可达即可),每个村庄之间修路成本不同,要求铺设的公路总成本为最小。请计算最小的公路总成本。
输入:
测试输入包含若干测试用例。每个测试用例的第1行给出村庄数目N ( < 100 );随后的N(N-1)/2行对应村庄间的修路成本,每行给出一对正整数,分别是两个村庄的编号,以及此两村庄间的修路成本。为简单起见,村庄从1到N编号。
当N为0时,输入结束,该用例不被处理。
输出:
对每个测试用例,在1行里输出最小的公路总成本。
样例输入:
3
1 2 1
1 3 2
2 3 4
4
1 2 1
1 3 4
1 4 1
2 3 3
2 4 2
3 4 5
0
样例输出:
3
5
#include "vector"
#include "string"
#include "algorithm"
#include <iostream>
#include "stack"
#include <cmath>
#include <set>
using namespace std;
class Edge
{
public:
Edge()
{
cost= 0;
}
int acity;//城市a
int bcity;//城市b
int cost; //建成a到b的路的花费
bool operator < (const Edge &q) const//注意返回值的类型,运算符重载。
{
return cost<q.cost;
}
};
Edge edge[10000];
class UFSet
{
public:
UFSet(int nsize)
{
size = nsize;
parent = new int[size + 1];
};
~UFSet()
{
delete[] parent;
parent = NULL;
};
// 初始化每个元素的祖先
void makeSet(int n);
// 找到元素x的祖先元素
int findSet(int x);
// 获取最小花费
int getMinCost(int m);
private:
int *parent;//存放祖先节点,例如x=parent[i],元素i的祖先节点为元素x
int size;
};
void UFSet::makeSet(int n) //初始化
{
//初始化每一个元素都各自为一个独立的集合,其祖先均设定为自身
for (size_t i = 1; i <= n; i++)
parent[i] = i;
}
int UFSet::findSet(int x)
{
//找到元素所在的集合,也就是找到自己的最高的祖先,
//这也是判断两个元素是否在同一个集合中的主要依据。
if (parent[x] == x)//递归截止条件(最高祖先的祖先是其自身)
return x;
parent[x] = findSet(parent[x]);//递归,最终找到x的最高祖先,并且沿途找到所有的最高祖先
return parent[x];
}
int UFSet::getMinCost(int m)
{
sort(edge, edge + m);//必须先对边排序(根据边的修建费用),这样才能贪心的形成最小花费
int sum = 0;
for (int i = 0; i<m; i++)
{
int baseA = findSet(edge[i].acity);//找到城市a的祖先(要么是自身要么是城市b的编号)
int baseB = findSet(edge[i].bcity);
//祖先不同,即不是同一个集合,就要修路连起来。祖先相同就不管了。
if (baseA != baseB)
{
parent[baseA] = baseB;//将城市a的祖先设置成b的祖先这个式子等价于parent[edge[i].acity] = edge[i].bcity
sum += edge[i].cost;
}
}
return sum;
}
int main()
{
int n = 0;
while (cin >> n, n > 0)
{
int m = n*(n - 1) / 2;
UFSet uset(100);
uset.makeSet(n);//初始化每个城市的祖先为自身
for (int i = 0; i < m; i++)
cin >> edge[i].acity >> edge[i].bcity >> edge[i].cost;
int mincost = uset.getMinCost(m);
cout << mincost << endl;
}
return 0;
}参考:
1.http://www.cnblogs.com/cherish_yimi/archive/2009/10/11/1580839.html
2. http://blog.csdn.net/ebowtang/article/details/41699497

相关文章推荐
- C#数据结构之顺序表(SeqList)实例详解
- Lua教程(七):数据结构详解
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- C#数据结构之队列(Quene)实例详解
- C#数据结构揭秘一
- C#数据结构之单链表(LinkList)实例详解
- 数据结构之Treap详解
- 用C语言举例讲解数据结构中的算法复杂度结与顺序表
- C#数据结构之堆栈(Stack)实例详解
- C#数据结构之双向链表(DbLinkList)实例详解
- JavaScript数据结构和算法之图和图算法
- Java数据结构及算法实例:冒泡排序 Bubble Sort
- Java数据结构及算法实例:插入排序 Insertion Sort
- Java数据结构及算法实例:考拉兹猜想 Collatz Conjecture
- java数据结构之java实现栈
- java数据结构之实现双向链表的示例
- Java数据结构及算法实例:选择排序 Selection Sort
- Java数据结构及算法实例:朴素字符匹配 Brute Force
- Java数据结构及算法实例:汉诺塔问题 Hanoi
- Java数据结构及算法实例:快速计算二进制数中1的个数(Fast Bit Counting)