小小图片爬虫
2016-04-15 09:45
645 查看
前言
事前准备
项目结构
项目环境
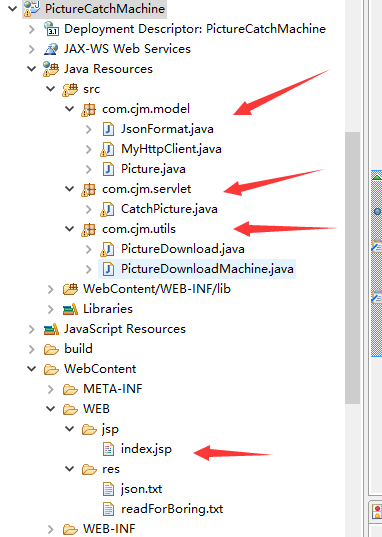
项目说明
项目目录
项目编码
页面
indexjsp
comcjmservlet
CatchPciture
comcjmmodel
JsonFormat
MyHttpClient
Picture
comcjmutils
PictureDownload
PictureDownloadMachine
最后再说几句
资源下载路径
世界上第一个爬虫叫做“互联网漫游者”(www waderer),他是由麻省理工学院(MIT)的学生马休·格雷在1993年写的。
假定我们从一家门户网站的首页出发,先下载这个网页,通过分析这个网页,可以找到藏在它里面的超链接,就知道这家门户网站所有链接的网页。
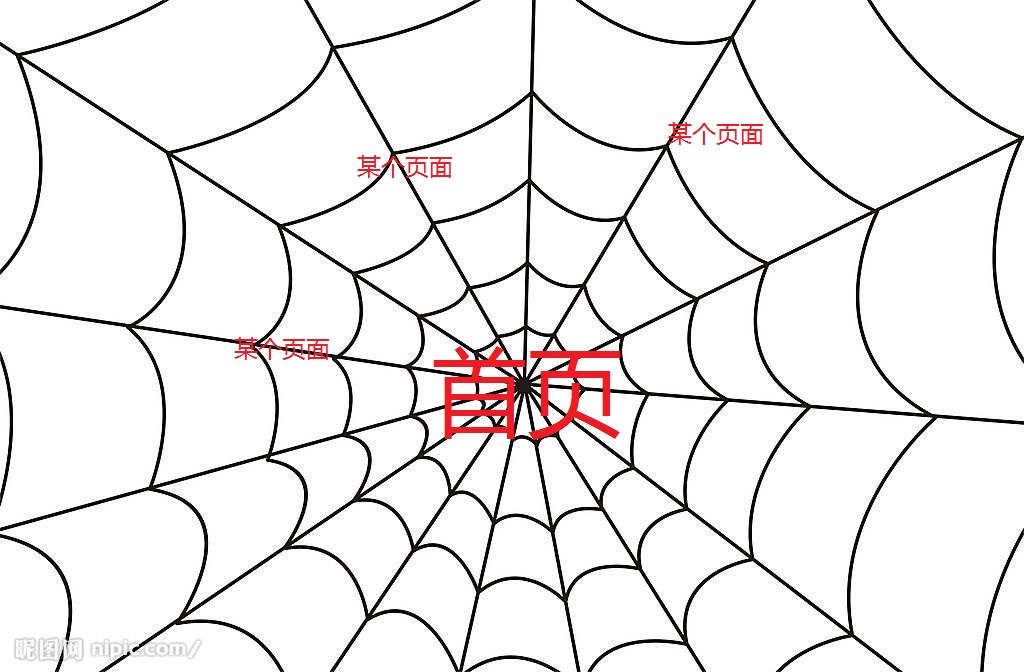
爬虫就是从某个节点(某个网页)开始,爬取链接中隐藏的秘宝。
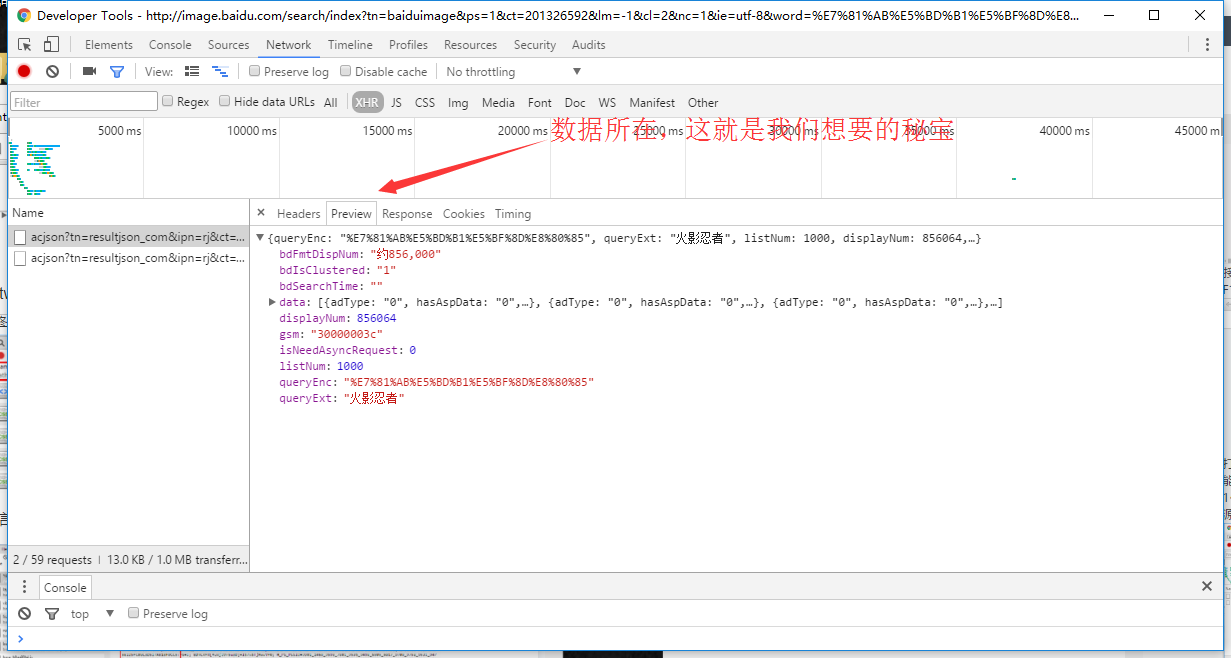
接着我们打开浏览器的开发者,如果实在是找不到,那就直接点击F12,效果是一样的
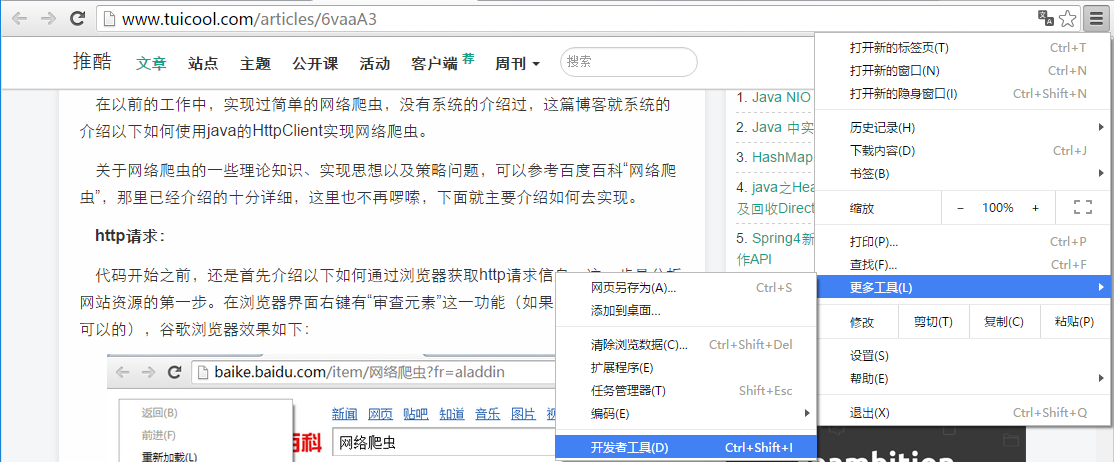
打开开发者之后,我们要选择其中的Network,通过这个栏目,我们就能看到所有的http请求和响应等等信息。
1代表我们选择的Network,2是我们想要的链接资源,3就是链接资源。
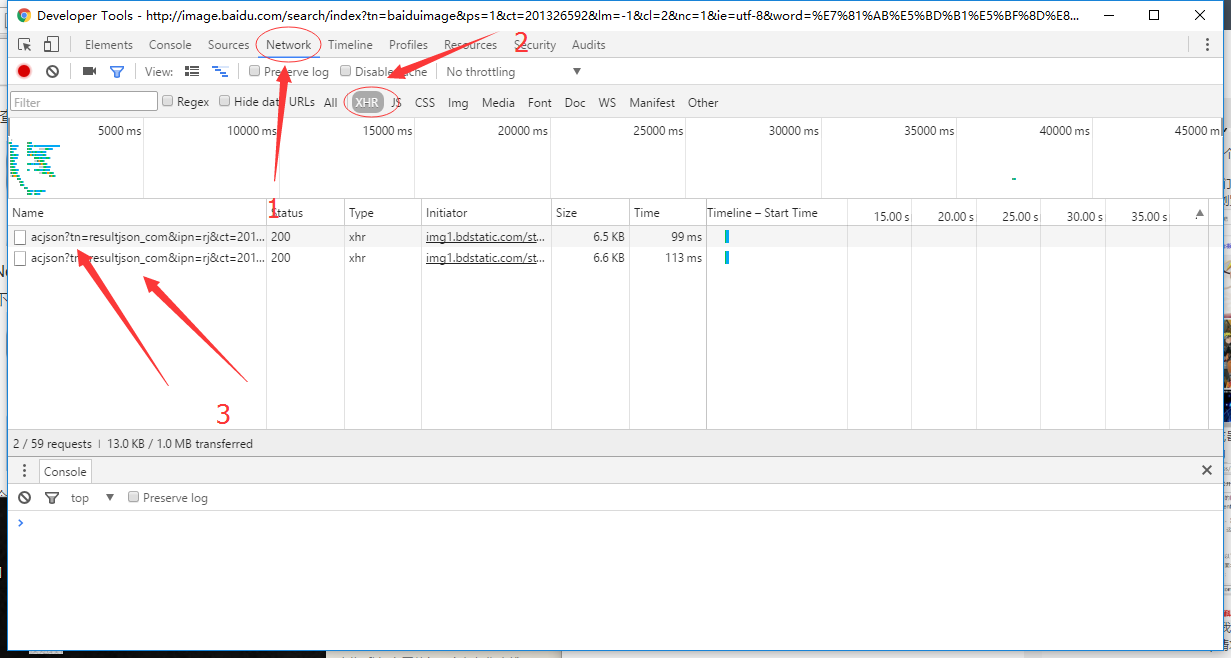
点击http请求(即点击3)我们就能看到所有的详细信息,如下图所示
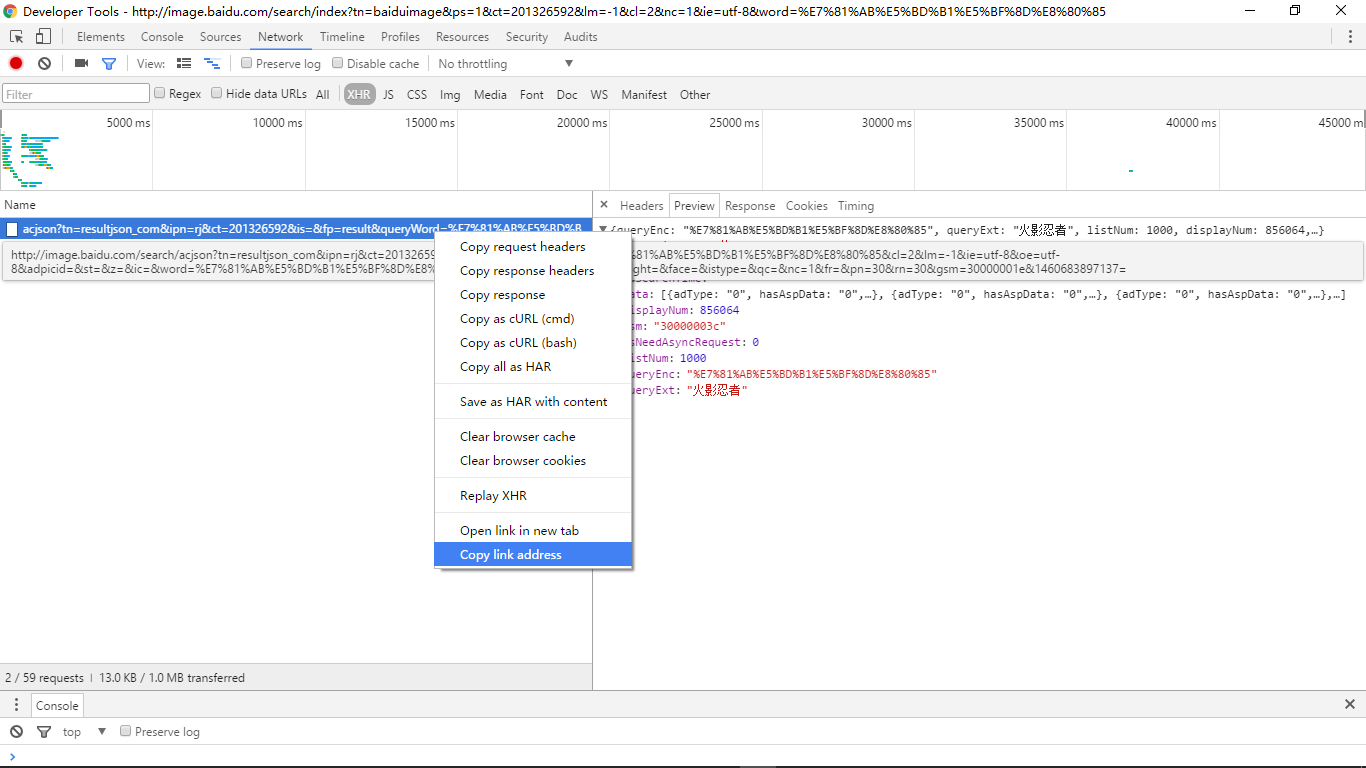
之后,就可以准备我们要的第一个材料,一个链接操作如下,我们右击一个http链接,然后把它复制下来。
存放一些对象的model层
存放响应的servlet层
存放工具的utils层
还有就是一个页面index.jsp
/* 其实让我写这个页面的时候,我是拒绝的,因为这个小爬虫是不需要页面的,增加页面只是为了直观而已,所以我就写了一个简单的页面,当然你可以使用APP、WindowsForm、swing的界面,或者什么界面都不要,直接输入参数就行。因为后台要的只是参数 */
该文章为原创文章,转载的时候请附上我的微博链接,谢谢。
事前准备
项目结构
项目环境
项目说明
项目目录
项目编码
页面
indexjsp
comcjmservlet
CatchPciture
comcjmmodel
JsonFormat
MyHttpClient
Picture
comcjmutils
PictureDownload
PictureDownloadMachine
最后再说几句
资源下载路径
前言
通过对HttpClient的学习,打开了我对后台的理解,在我的眼中,后台不再是依赖前端的存在,它可以是一种无浏览器,无APP界面的存在。这篇博客将尽详细的介绍HttpClient实现网络爬虫。世界上第一个爬虫叫做“互联网漫游者”(www waderer),他是由麻省理工学院(MIT)的学生马休·格雷在1993年写的。
假定我们从一家门户网站的首页出发,先下载这个网页,通过分析这个网页,可以找到藏在它里面的超链接,就知道这家门户网站所有链接的网页。
爬虫就是从某个节点(某个网页)开始,爬取链接中隐藏的秘宝。
事前准备
在代码的开始,我们需要先准备我们需要的那个节点,我们打开我们浏览器(这里以谷歌浏览器为示例),我们输入搜索自己喜欢的内容页面接着我们打开浏览器的开发者,如果实在是找不到,那就直接点击F12,效果是一样的
打开开发者之后,我们要选择其中的Network,通过这个栏目,我们就能看到所有的http请求和响应等等信息。
1代表我们选择的Network,2是我们想要的链接资源,3就是链接资源。
点击http请求(即点击3)我们就能看到所有的详细信息,如下图所示
之后,就可以准备我们要的第一个材料,一个链接操作如下,我们右击一个http链接,然后把它复制下来。
项目结构
项目环境
环境Encoding:UTF-8项目说明
项目包括:存放一些对象的model层
存放响应的servlet层
存放工具的utils层
还有就是一个页面index.jsp
/* 其实让我写这个页面的时候,我是拒绝的,因为这个小爬虫是不需要页面的,增加页面只是为了直观而已,所以我就写了一个简单的页面,当然你可以使用APP、WindowsForm、swing的界面,或者什么界面都不要,直接输入参数就行。因为后台要的只是参数 */
项目目录
项目编码
页面
index.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>输入页面</title>
</head>
<body>
<script type="text/javascript">
function checkForm() {
var keyWord=document.getElementById("keyWord");
var pageNum=document.getElementById("pageNum");
var fileUri=document.getElementById("fileUri");
var num=new RegExp("^[0-9]*$");//判断正整数 /^[1-9]+[0-9]*]*$/
if(!num.test(pageNum.value)) {
alert("请输入数字");
return false;
} else if(keyWord.value==""||pageNum.value==""||fileUri==""){
alert("请填完整内容");
return false;
}
return true;
}
</script>
<%
String message=(String)request.getAttribute("message");
if(message!=null) {
out.print(message);
}
%>
<form action="CatchPicture" method="post" onsubmit="return checkForm()">
<label for="keyWord">关键字</label>
<input type="text" value="火影忍者" id="keyWord" name="keyWord"/>
<label for="pageNum">获得页数</label>
<input type="text" value="1" name="pageNum" id="pageNum"/><br/>
<label for="file">保存到</label>
<input type="text" name="fileUri" id="fileUri" value="C:\Users\CHEN\Desktop\save"/>
<input type=button value="选择文件夹"/>
<input type="submit" value="提交"/>
</form>
</body>
</html>com.cjm.servlet
CatchPciture
package com.cjm.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.http.client.ClientProtocolException;
import com.cjm.model.Picture;
import com.cjm.utils.PictureDownload;
/**
* @time 2016年4月14日
* @author CHEN
* @param
* @about 一个图片下载的系统
*/
@WebServlet("/WEB/jsp/CatchPicture")
public class CatchPicture extends HttpServlet {
private static final long serialVersionUID = 1L;
private static Picture picture;
/**
* @see HttpServlet#HttpServlet()
*/
public CatchPicture() {
super();
// TODO Auto-generated constructor stub
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
doPost(request, response);
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
//提示将要下载图片
/* 获得当前线程的名字
* Thread current = Thread.currentThread();
System.outPw.println(current.getName()); */
//输出一些提示的信息,当然最好是写在日志中,我在这里就精简了这部分内容
System.out.println("下载图片");
//设置编码
response.setCharacterEncoding("utf-8");
request.setCharacterEncoding("utf-8");
//设置返回提示信息
PrintWriter outPwPw=response.getWriter();
//获得用户输入内容
String keyWordStr=request.getParameter("keyWord");//获得关键字
String pageNumStr=request.getParameter("pageNum");//获得页数
String fileUriStr=request.getParameter("fileUri");//获得文件夹路径
//构造Picture对象
picture=new Picture(keyWordStr,pageNumStr,fileUriStr);
if(keyWordStr==null||"".equals(keyWordStr)) {//返回失败的提示
//当然你可以设置更多的检验,但是有更好的处理方式,之后我会使用异常处理去使系统具有恢复性
request.setAttribute("message", "<script type='text/javascript'>alert('请输入关键字');</script>");
} else {//万事俱备
//调用下载过程函数
//这里为什么要使用线程呢,关于线程的小秘密,我之后也会写
//请注意我这里使用了内部匿名类
Thread thread =new Thread(){
public void run() {
try {
PictureDownload.downloadPicture(picture);//调用了整个系统最关键的部分
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
};
thread.setName("pictureCatchMachine");//给他起个名字
thread.start();
}
request.getRequestDispatcher("index.jsp").forward(request, response);//返回展示页面
}
}com.cjm.model
JsonFormat
package com.cjm.model;
/**
* @time 2016年4月14日
* @author CHEN
* @param
* jsonStr:需要格式化的json字符串
* jonFormat:格式化的json字符串,建议就是当需要进行很多字符串拼接的时候,使用
* StringBuffer,至于为什么可以看看我写的String、StringBuffer、StringBuild的区别
* @about 对jsonStr进行格式化
* 对jsonStr的格式化其实就是
* 1、使用适量的换行
* 2、使用适当的缩进
* 例子:
* {
"data": {
"id": 1,
"name": "junming",
"wife": [
{
"id": 1,
"name": "yingli"
},
{
"id": 2,
"name": "yingli"
}
]
}
}
*/
public class JsonFormat {
public static String format(String jsonStr) {
int level = 0;
StringBuffer jsonFormatStr = new StringBuffer();
for(int i=0;i<jsonStr.length();i++){
char c = jsonStr.charAt(i);//取出jsonStr中的所有字符
if(level>0&&'\n'==jsonFormatStr.charAt(jsonFormatStr.length()-1)){
jsonFormatStr.append(getLevelStr(level));
}
switch (c) {//换行//缩进
case '{':
case '[':
jsonFormatStr.append(c+"\n");
level++;
break;
case ',':
jsonFormatStr.append(c+"\n");
break;
case '}':
case ']':
jsonFormatStr.append("\n");
level--;
jsonFormatStr.append(getLevelStr(level));
jsonFormatStr.append(c);
break;
default:
jsonFormatStr.append(c);
break;
}
}
return jsonFormatStr.toString();
}
private static String getLevelStr(int level){
StringBuffer levelStr = new StringBuffer();
for(int levelI = 0;levelI<level ; levelI++){
levelStr.append("\t");//增加空格
}
return levelStr.toString();
}
}MyHttpClient
package com.cjm.model;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import jdk.internal.org.xml.sax.InputSource;
import org.apache.commons.httpclient.HttpClientError;
import org.apache.commons.httpclient.HttpState;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.protocol.HTTP;
/**
* @time 2016年4月14日
* @author CHEN
* @param
* @about 获得json返回值
*/
public class MyHttpClient {
/**
* @about 通过url获得json返回内容
* @param url
* @return
* @throws ClientProtocolException
* @throws IOException
*/
public static String getJsonDate(String url) throws ClientProtocolException, IOException {
HttpClient client=new DefaultHttpClient();
HttpPost post=new HttpPost(url);
//获得响应对象
HttpResponse response = client.execute(post);
//响应状态
Integer statusCode=response.getStatusLine().getStatusCode();
if(statusCode!=HttpStatus.SC_OK) {
throw new HttpClientError("http status is ERROR");
}
HttpEntity entityRsp=response.getEntity();
StringBuffer result=new StringBuffer();
BufferedReader rd=new BufferedReader(new InputStreamReader(
entityRsp.getContent(),HTTP.UTF_8));
String tempLine=rd.readLine();
while(tempLine!=null) {
result.append(tempLine);
tempLine=rd.readLine();
}
if(entityRsp!=null) {
entityRsp.consumeContent();
}
return result.toString();
}
}Picture
package com.cjm.model;
/**
* @time 2016年4月14日
* @author CHEN
* @param Picture:对象的关键词、文件路径、页数
*/
public class Picture {
private String keyWord;//关键词
private String pageNum;//下载的页数
private String fileUri;//文件夹路径
public Picture() {
super();
}
public Picture(String keyWord,String pageNum,String fileUri) {
super();
this.keyWord=keyWord;
this.pageNum=pageNum;
this.fileUri=fileUri;
}
public String getKeyWord() {
return keyWord;
}
public void setKeyWord(String keyWord) {
this.keyWord = keyWord;
}
public String getPageNum() {
return pageNum;
}
public void setPageNum(String pageNum) {
this.pageNum = pageNum;
}
public String getFileUri() {
return fileUri;
}
public void setFileUri(String fileUri) {
this.fileUri = fileUri;
}
}com.cjm.utils
PictureDownload
package com.cjm.utils;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.net.URLEncoder;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import org.apache.http.client.ClientProtocolException;
import com.cjm.model.MyHttpClient;
import com.cjm.model.Picture;
/**
* @time 2016年4月14日
* @author CHEN
* @param
* picture:要下载对象的关键词、文件路径、页数
* @about 一个图片下载的系统
*/
public class PictureDownload {
//下载图片的功能
public static void downloadPicture(Picture picture) throws ClientProtocolException, IOException {
//获得下载的页数
int pageCount=(int)Double.parseDouble(picture.getPageNum());
//URLEncoder.encode(picture.getKeyWord()):将关键字转化成url格式
for(int i=0;i<=pageCount;i++) {
//爬取的图片来自百度
String uri="http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj"
+ "&ct=201326592&is=&fp=result&queryWord=" + URLEncoder.encode(picture.getKeyWord())
+ "&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0"
+ "&word=" + URLEncoder.encode(picture.getKeyWord())
+ "&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=" + 30 * i
+ "&rn=30&gsm=7000096&1460517144785=";
//获得返回的json字符串
String jsonStr= MyHttpClient.getJsonDate(uri);
//将jsonStr字符串格式化之后写入文件
String rootPathStr=Thread.currentThread().getContextClassLoader().getResource("/").getPath();
//File file=new File(rootPathStr+"json.txt");
//if(!file.exists()) {
// file.createNewFile();//新建文件
//}
//System.out.println("记录文件的地址"+file.getAbsolutePath());//最好是记在日志中
//开始记录入文件
/*
*装饰者
*FileWriter 被装饰者
*BufferWriter 装饰者
*就是加了一个缓存,这样等到缓存满了再写到硬盘,提高了性能
*/
//FileWriter outFw=new FileWriter(file);
//BufferedWriter outPw=new BufferedWriter(outFw);
//outPw.write(jsonStr,0,jsonStr.length());//要写入的内容、起始的位置、结束的位置
//outPw.close();//这是很重要的,关闭流
JSONObject objRoot=JSONObject.fromObject(jsonStr);//将jsonStr字符串转成JSONObject对象
JSONArray imgsJson=(JSONArray) objRoot.get("data");//获得data节点内容
for(int i1=0;i1<imgsJson.size()-1;i1++) {
JSONObject jsonObject=imgsJson.getJSONObject(i1);//获得数组的JSONObject对象
String objUri=(String)jsonObject.get("hoverURL");
//输出下载的图片地址
System.out.println(objUri);
//下载图片
PictureDownloadMachine.downloadImage(objUri,picture);
}
}
}
}PictureDownloadMachine
package com.cjm.utils;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.file.Paths;
import com.cjm.model.Picture;
/**
* @time 2016年4月14日
* @author CHEN
* @param
* @about 一个图片下载的具体实现
*/
public class PictureDownloadMachine {
/**
* @param objUri:图片的地址
* picture:提供图片存放的地址
*/
public static void downloadImage(String objUri,Picture picture) throws IOException {
//获得图片流
byte[] btImg=getImageFromNetByUrl(objUri);
if(null!=btImg&&btImg.length>0) {
//图片流存在写入硬盘
String pathStr=Paths.get(picture.getFileUri(), objUri.substring(objUri.lastIndexOf("/")+1)).toString();//拼接路径
writeImageToDisk(btImg,pathStr);//写入硬盘
}
}
private static byte[] getImageFromNetByUrl(String strUrl) {
try {
URL url=new URL(strUrl);//将链接转成URL
HttpURLConnection conn=(HttpURLConnection)url.openConnection();
//伪装成浏览器
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2700.0 Safari/537.36");
//伪装主机
conn.setRequestProperty("Host" ,"image.baidu.com");
//设置接收方式
conn.setRequestProperty("Accept" ,"text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01");
//设置字符
conn.setRequestProperty("Accept-Encoding" ,"gzip, deflate, sdch");
//设置连接状态
conn.setRequestProperty("Connection" ,"keep-alive");
//伪装请求方
conn.setRequestProperty("Referer" ,"http://image.baidu.com");
conn.setRequestProperty("X-Requested-With" ,"XMLHttpRequest");
conn.setRequestMethod("GET");
conn.setConnectTimeout(5*1000);
//获得返回流
InputStream inStream =conn.getInputStream();
byte[]btImg=readInputStream(inStream);
return btImg;
} catch(Exception e) {
e.printStackTrace();
return null;
}
}
/**
* @about 捕获内容缓冲区的数据,转换成字节数组
* @param inputStream :输入流
* byteArrayOutputStream :输出流(存储容器)
*/
private static byte[] readInputStream(InputStream inputStream) throws IOException {
ByteArrayOutputStream byteArrayOutputStream=new ByteArrayOutputStream();
byte[]buffer=new byte[1024];
int len=0;
while ((len=inputStream.read(buffer))!=-1) {
byteArrayOutputStream.write(buffer,0,len);
}
inputStream.close();
return byteArrayOutputStream.toByteArray();
}
private static void writeImageToDisk(byte[] btImg, String fileUri) throws IOException {
File file=new File(fileUri);//新建一个文件空壳
FileOutputStream fileOutputStream=new FileOutputStream(file);//文件输出流
fileOutputStream.write(btImg);//把图片写到了文件空壳中
fileOutputStream.flush();//把缓存的内容都写完
fileOutputStream.close();
}
}最后再说几句
在写这个项目的时候,遇到了jar包的问题,httpclient.jar推荐使用4.3版本的。不然有可能会报ClassNotFoundException:org.apache.http.message.TokenParser该文章为原创文章,转载的时候请附上我的微博链接,谢谢。
资源下载路径
小小图片爬虫
相关文章推荐
- Python3写爬虫(四)多线程实现数据爬取
- Scrapy的架构介绍
- 爬虫笔记
- 按右键另存图片只能存BMP
- photoshop去除图片上的水印
- upload上传单张图片
- 图片引发的溢出危机(图)
- C#实现把彩色图片灰度化代码分享
- 基于C#实现网页爬虫
- C#将图片和字节流互相转换并显示到页面上
- C#监控文件夹并自动给图片文件打水印的方法
- 纯CSS实现的当鼠标移上图片添加阴影效果代码
- 如何使用C#从word文档中提取图片
- C#实现打开画图的同时载入图片、最大化显示画图窗体的方法
- C#图片添加水印的实现代码
- 随鼠标移动的图片或文字特效代码
- CSS 图片横向排列实现代码
- C#实现将Email地址转成图片显示的方法
- C#实现图片加相框的方法
- 超级经典一套鼠标控制左右滚动图片带自动翻滚