深度学习与传统神经网络算法
2016-04-08 12:14
621 查看
传统的神经网络中采用的是BP算法,存在的主要问题:
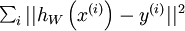
,其中参数
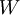
是要优化的参数。对深度网络而言,这种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,因而使用梯度下降法(或者像共轭梯度下降法,L-BFGS等方法)效果并不好。
与梯度弥散问题紧密相关的问题是:当神经网络中的最后几层含有足够数量神经元的时候,可能单独这几层就足以对有标签数据进行建模,而不用最初几层的帮助。因此,对所有层都使用随机初始化的方法训练得到的整个网络的性能将会与训练得到的浅层网络(仅由深度网络的最后几层组成的浅层网络)的性能相似。
未完待续......
参考:Deep Network:Overview
数据获取问题
我们需要依赖于有标签的数据才能进行训练。然而有标签的数据通常是稀缺的,因此对于许多问题,我们很难获得足够多的样本来拟合一个复杂模型的参数。例如,考虑到深度网络具有强大的表达能力,在不充足的数据上进行训练将会导致过拟合。局部极值问题
使用监督学习方法来对浅层网络(只有一个隐藏层)进行训练通常能够使参数收敛到合理的范围内。但是当用这种方法来训练深度网络的时候,并不能取得很好的效果。特别的,使用监督学习方法训练神经网络时,通常会涉及到求解一个高度非凸的优化问题(例如最小化训练误差,其中参数
是要优化的参数。对深度网络而言,这种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,因而使用梯度下降法(或者像共轭梯度下降法,L-BFGS等方法)效果并不好。
梯度弥散问题
梯度下降法(以及相关的L-BFGS算法等)在使用随机初始化权重的深度网络上效果不好的技术原因是:梯度会变得非常小。具体而言,当使用反向传播方法计算导数的时候,随着网络的深度的增加,反向传播的梯度(从输出层到网络的最初几层)的幅度值会急剧地减小。结果就造成了整体的损失函数相对于最初几层的权重的导数非常小。这样,当使用梯度下降法的时候,最初几层的权重变化非常缓慢,以至于它们不能够从样本中进行有效的学习。这种问题通常被称为“梯度的弥散”.与梯度弥散问题紧密相关的问题是:当神经网络中的最后几层含有足够数量神经元的时候,可能单独这几层就足以对有标签数据进行建模,而不用最初几层的帮助。因此,对所有层都使用随机初始化的方法训练得到的整个网络的性能将会与训练得到的浅层网络(仅由深度网络的最后几层组成的浅层网络)的性能相似。
未完待续......
参考:Deep Network:Overview

相关文章推荐
- Android OkHttp完全解析 是时候来了解OkHttp了
- 导入WEB工程报HttpServlet相关报找不到解决方法
- 实测Kubernetes和Mesos在高并发下的网络性能
- Fiddler(二) - 使用Fiddler做抓包分析
- Java 通过HttpURLConnection Post方式提交xml,并从服务端返回数据
- hisi平台mii网络模式和rmii网络模式的uboot制作
- Android编程实现TCP客户端的方法
- 使用telnet玩一下http
- 网络刷博器爬虫(while应用)
- jsp编译完成后显示的HTTP Status 404 - /MyWebBBS/servlet/RegisterServlet%20%7D其中的%20%7D什么意思
- HTTP学习笔记--HTTP报文
- Linux traceroute --追踪网络数据包
- jQuery ajax 请求HttpServlet返回[HTTP/1.1 405 Method not allowed]
- Flash存储的故事(http://alanwu.blog.51cto.com/3652632/1426457)
- 利用听云Server和听云Network实测Kubernetes和Mesos在高并发下的网络性能
- OC网络下载
- POCO库下访问HTTPS获取返回的JSON数据
- 如何从网络上获取图片转换成字节流或者保存到本地
- Linux netstat --检验本机各端口的网络连接情况
- Linux nc --网络工具