Java并发机制之Volatile关键字
2016-04-03 22:27
549 查看
在多线程并发编程中synchronized和volatile都是很重要的关键字,简单来说,synchronized保持和代码块中代码的同步下,valatile保证了共享变量的可见性。
volatile的定义与实现原理:
Java语言允许线程访问共享变量,为了确保共享变量能被准备和一致的更新,线程应该确保通过排它锁单独获得这个变量。java语言提供了volatile,我们可以把它当成一个轻量级的锁。
volatile底层实现是因为我们在堆volatile变量修辞的共享变量进行写操作的时候会多出一个叫lock的汇编代码,Lock前缀的指令在多核处理器下会引发两件事情。
1.讲当前处理器缓存行的数据写回到系统内容。
2.这个写回内存的操作会使其他CPU里缓存了该内存地址的地址的数据无效。
public static void main(String[] args) throws InterruptedException {
Thread1 t1 = new Thread1();
t1.start();
Thread1 t2 = new Thread1();
t2.plzStop();
t2.start();
Thread1 t3 = new Thread1();
t3.start();
}
}
class Thread1 extends Thread {
private volatile boolean flag = true;
@Override
public void run() {
int i = 0;
while (flag) {
i++;
try {
System.out.println(i);
} catch (Exception e) {
e.printStackTrace();
}
if (i > 9) {
flag = false;
}
}
}
public void plzStop() throws InterruptedException{
flag = false;
}
}上面这段代码应该只会执行两个线程里面的循环,但是事实并非如此,因为我们在多线程的情况下。处理器是不知道我们什么时候改变了flag的值的,所以并不能及时的给出相应。如果加上volatite关键字就可以;下面来讲讲volatile的实现原则。
为了提高处理速度,处理器不直接和内存进行通信而是先将系统内存的数据读到内部缓存后再进行操作,但操作完不知道何时回写到内存。如果声明了volatile的变量进行写操作,JVM就会向处理器发送一条Loca前缀的指令,讲这个变量所在缓存行的数据写回到系统内存。但是,就算写到内存,如果其他处理器的缓存的值还是旧的,再执行操作还是会有问题,所以,在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,当处理器发现自己的缓存行对应的内存地址被修改,就会将当前缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
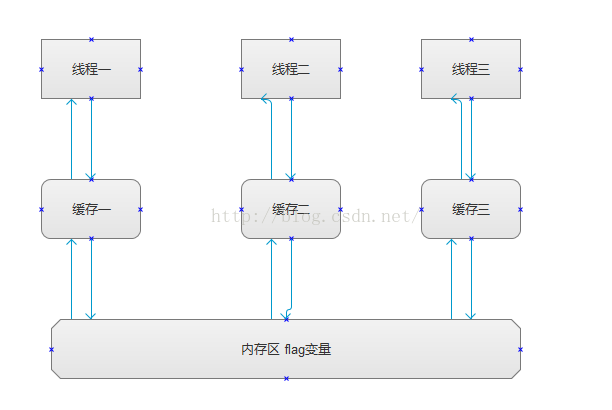
当我们在多线程下执行操作flag变量的时候,他会去复制这个变量到我们的缓存里面,所以我们的线程读的也是这个缓存里面的这个变量,当我们某个线程修改了这个变量的值的时候,内存区的flag变量如果不能得到及时的响应就会造成数据不同步的问题。
下面具体讲解volatile的实现原则。
1:Lock前缀指令会引起处理器缓存回写到内存。Loca前缀指令会锁缓存,在锁操作时,总是在总线上声明LOCk#信号。他会锁住一个具体的缓存,当这个缓存回写到内存后,并使用缓存一致性机制来确保修改的原子性,此操作被称为“缓存锁定”。也就是相当于把我们写缓存的动作给同步了,相对于synchronized来说要轻量的多。
2:一个处理器的缓存回写到内存会导致其他处理器的缓存无效。这个也就是说,当我们缓存执行回写的时候,处理器使用嗅探技术保证它的内部缓存,系统内存中和其他处理器的缓存的数据在总线上保存一致。也就是说当我们的缓存一改变flag状态的时候,会强制是使缓存二和缓存三里面的flag状态无效,当我们下次访问相同内存地址的时候,强制把flag变量从内存中填充进来;
Volatile的使用优化
追加字节优化性能
这种方式看起来很神奇,但如果深入理解处理器架构就能理解其中的奥秘,因为对于英特尔酷睿I7,酷睿和一些其他的处理器,高速缓存行是64个字节宽,不支持部分填充行,这意味着,如果队列的头节点和尾节点都不足64字节的话,处理器会讲他们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同意的头,尾节点。使用追加到64字节的方式来填满高速缓存区,就是为了避免头和尾加载到一个缓存行,使头尾不会互相锁定,影响效率;
但是在使用的时候要注意,缓存行非64字节的处理器的时候不要使用这种方法;如果是32处理器的啦,填满32字节也不错。如果共享变量不被频繁读写的话,那么没必要去填充字节;
volatile的定义与实现原理:
Java语言允许线程访问共享变量,为了确保共享变量能被准备和一致的更新,线程应该确保通过排它锁单独获得这个变量。java语言提供了volatile,我们可以把它当成一个轻量级的锁。
volatile底层实现是因为我们在堆volatile变量修辞的共享变量进行写操作的时候会多出一个叫lock的汇编代码,Lock前缀的指令在多核处理器下会引发两件事情。
1.讲当前处理器缓存行的数据写回到系统内容。
2.这个写回内存的操作会使其他CPU里缓存了该内存地址的地址的数据无效。
public static void main(String[] args) throws InterruptedException {
Thread1 t1 = new Thread1();
t1.start();
Thread1 t2 = new Thread1();
t2.plzStop();
t2.start();
Thread1 t3 = new Thread1();
t3.start();
}
}
class Thread1 extends Thread {
private volatile boolean flag = true;
@Override
public void run() {
int i = 0;
while (flag) {
i++;
try {
System.out.println(i);
} catch (Exception e) {
e.printStackTrace();
}
if (i > 9) {
flag = false;
}
}
}
public void plzStop() throws InterruptedException{
flag = false;
}
}上面这段代码应该只会执行两个线程里面的循环,但是事实并非如此,因为我们在多线程的情况下。处理器是不知道我们什么时候改变了flag的值的,所以并不能及时的给出相应。如果加上volatite关键字就可以;下面来讲讲volatile的实现原则。
为了提高处理速度,处理器不直接和内存进行通信而是先将系统内存的数据读到内部缓存后再进行操作,但操作完不知道何时回写到内存。如果声明了volatile的变量进行写操作,JVM就会向处理器发送一条Loca前缀的指令,讲这个变量所在缓存行的数据写回到系统内存。但是,就算写到内存,如果其他处理器的缓存的值还是旧的,再执行操作还是会有问题,所以,在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,当处理器发现自己的缓存行对应的内存地址被修改,就会将当前缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
当我们在多线程下执行操作flag变量的时候,他会去复制这个变量到我们的缓存里面,所以我们的线程读的也是这个缓存里面的这个变量,当我们某个线程修改了这个变量的值的时候,内存区的flag变量如果不能得到及时的响应就会造成数据不同步的问题。
下面具体讲解volatile的实现原则。
1:Lock前缀指令会引起处理器缓存回写到内存。Loca前缀指令会锁缓存,在锁操作时,总是在总线上声明LOCk#信号。他会锁住一个具体的缓存,当这个缓存回写到内存后,并使用缓存一致性机制来确保修改的原子性,此操作被称为“缓存锁定”。也就是相当于把我们写缓存的动作给同步了,相对于synchronized来说要轻量的多。
2:一个处理器的缓存回写到内存会导致其他处理器的缓存无效。这个也就是说,当我们缓存执行回写的时候,处理器使用嗅探技术保证它的内部缓存,系统内存中和其他处理器的缓存的数据在总线上保存一致。也就是说当我们的缓存一改变flag状态的时候,会强制是使缓存二和缓存三里面的flag状态无效,当我们下次访问相同内存地址的时候,强制把flag变量从内存中填充进来;
Volatile的使用优化
追加字节优化性能
这种方式看起来很神奇,但如果深入理解处理器架构就能理解其中的奥秘,因为对于英特尔酷睿I7,酷睿和一些其他的处理器,高速缓存行是64个字节宽,不支持部分填充行,这意味着,如果队列的头节点和尾节点都不足64字节的话,处理器会讲他们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同意的头,尾节点。使用追加到64字节的方式来填满高速缓存区,就是为了避免头和尾加载到一个缓存行,使头尾不会互相锁定,影响效率;
但是在使用的时候要注意,缓存行非64字节的处理器的时候不要使用这种方法;如果是32处理器的啦,填满32字节也不错。如果共享变量不被频繁读写的话,那么没必要去填充字节;

相关文章推荐
- 20145225《Java程序设计》 第5周学习总结
- Step by Step into Spring (AOP)
- jdk8——Stream API
- 【jdk1.8】PriorityQueue源码分析
- 20145109 《Java程序设计》第五周学习总结
- java多线程调用 单例类中一个的方法
- 20145201 《Java程序设计》第五周学习总结
- 20145227 《Java程序设计》第5周学习总结
- 20145235 《Java程序设计》第5周学习总结
- Java的Integer缓存
- JavaEE中向数据库写入数据乱码的问题
- 20145211《Java程序设计》第5周学习总结——独上高楼,望尽天涯路
- Java使用线程池递归压缩文件夹下面的所有子文件
- java泛型
- Spring.Net学习笔记(7)-事务
- 关于Spring MVC分页
- Java开发环境搭建与Intellij的安装和初始配置
- 通过Java字节码发现有趣的内幕之String篇(上)(转)
- jdk 1.7中HashMap的HashIterator实现细节小记
- Java命令学习系列(7):Javap(转)