JAVA IO 字节流与字符流
2016-04-01 00:37
405 查看
文章出自:听云博客
题主将以三个章节的篇幅来讲解JAVA IO的内容 。
第一节JAVA IO包的框架体系和源码分析,第二节,序列化反序列化和IO的设计模块,第三节异步IO。
本文是第一节。
IO框架
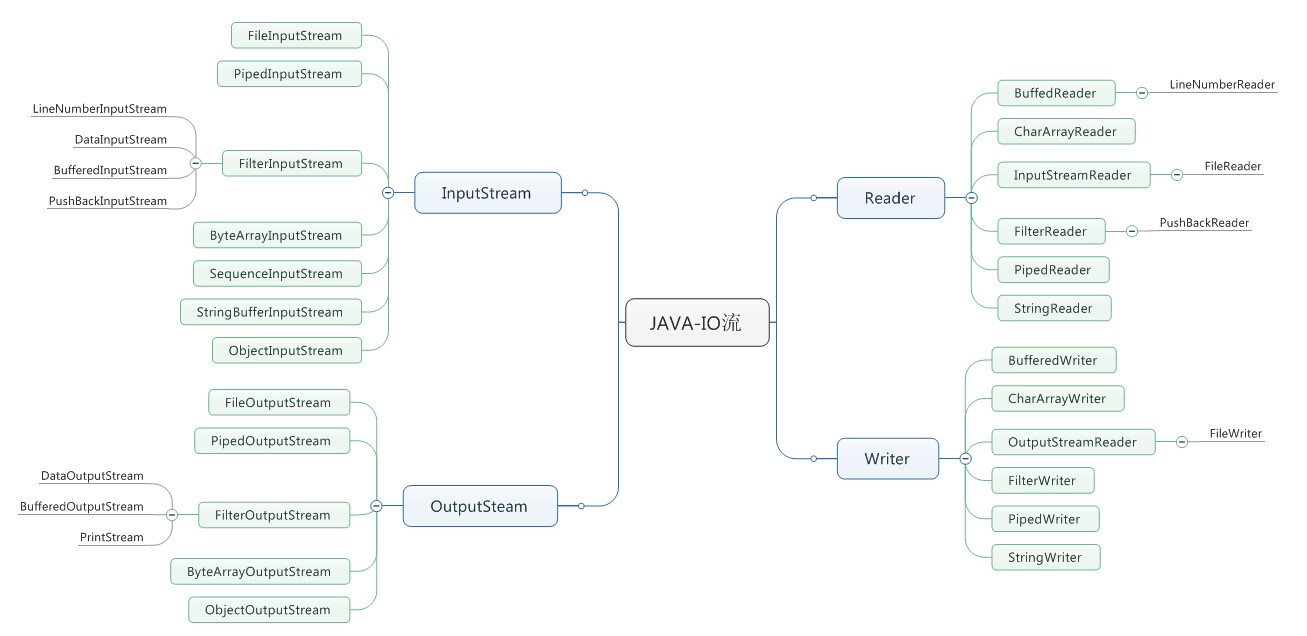
从上图我们可以看出IO可以分为两大块 字节流和字符流
字节流是 InputStream 和 OutputStream 分别对应输入与输出
字符流是Reader和Writer分别对应输入与输出
ByteArrayInputStream
它字节数组输入流。继承于InputStream。它包含一个数组实现的缓冲区ByteArrayInputStream也是数组实现的,提供read()来读取数据,内部有一个计数器用来确定下一个要读取的字节。
分析源码
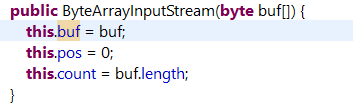
//pos是下一个会被读取字节的索引
//count字节流的长度
//pos为0就是从0开始读取
//读取下一个字节, &0xff的意思是将高8位全部置0

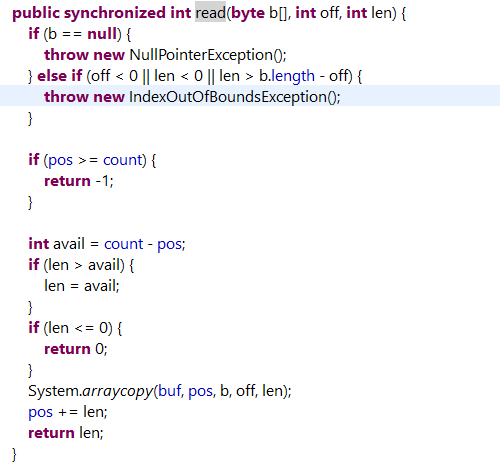
// 将“字节流的数据写入到字节数组b中”
// off是“字节数组b的偏移地址”,表示从数组b的off开始写入数据
// len是“写入的字节长度”
ByteArrayOutputStream
它是字节数组输出流。继承于OutputStream。ByteArrayOutputStream 实际也是数组实现的,它维护一个字节数组缓冲。缓冲区会自动扩容。
源码分析


//我们看到不带参的构造方法默认值是32 数组大小必须大于0否则会报 Negative initial size错误 ByteArrayOutputStream本质是一个byte数组
//是将字节数组buffer写入到输出流中,offset是从buffer中读取数据的起始下标,len是写入的长度。
//ensureCapacity方法是判断数组是否需要扩容
//System.arraycopy是写入的实现

//数组如果已经写满则grow
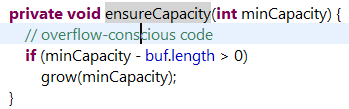
//int Capacity=oldCapacity<<1,简单粗暴容量X2

Piped(管道)
多线程可以通过管道实现线程中的通讯,在使用管道时必须PipedInputStream,PipedOutputStream配套缺一不可
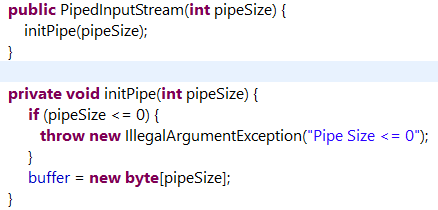
PipedInputStream

//初始化管道
//链接管道
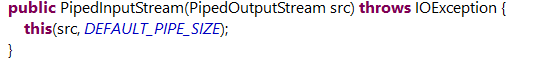

//将“管道输入流”和“管道输出流”绑定。
//调用的是PipedOutputStream的connect方法

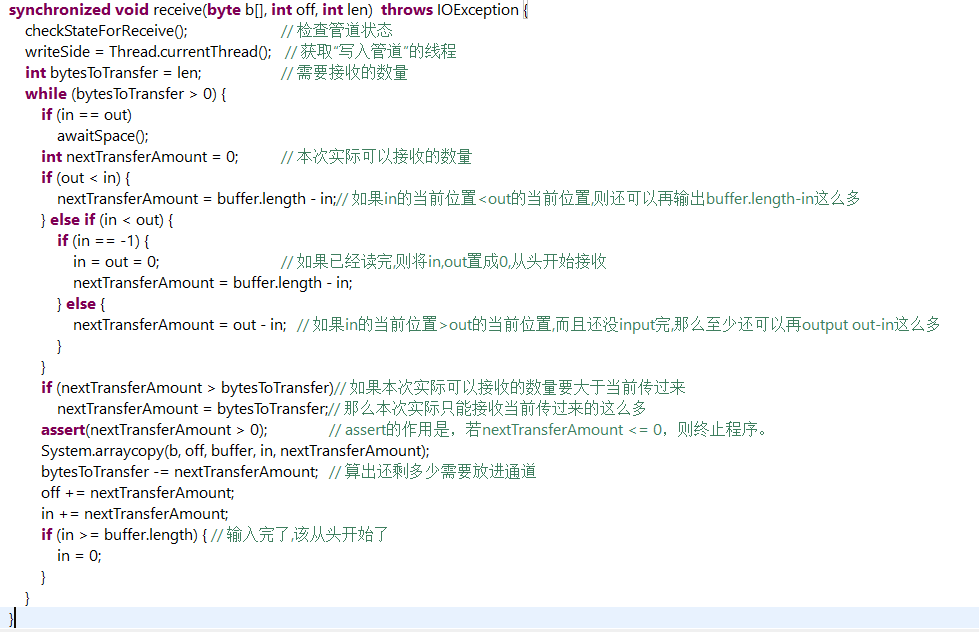
PipedOutputStream
//指定配对的PedpedInputStream



示例
ObjectInputStream 和 ObjectOutputStream
Object流可以将对象进行序列化操作。ObjectOutputStream可以持久化存储对象, ObjectInputStream,可以读出这些这些对象。
源码很简单直接上例子,关于序列化的内容题主将于下一节叙述
FileInputStream 和 FileOutputStream
FileInputStream 是文件输入流,它继承于InputStream。我们使用FileInputStream从某个文件中获得输入字节。
FileOutputStream 是文件输出流,它继承于OutputStream。我们使用FileOutputStream 将数据写入 File 或 FileDescriptor 的输出流。
File操作十分简单,这里就不再展示示例了。
FilterInputStream
它的作用是用来封装其它的输入流,并为它们提供额外的功能。它的常用的子类有BufferedInputStream和DataInputStream和PrintStream。。
BufferedInputStream的作用就是为“输入流提供缓冲功能,以及mark()和reset()功能”。
DataInputStream 是用来装饰其它输入流,它允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型。应用程序可以使用 DataOutputStream(数据输出流)写入由DataInputStream(数据输入流)读取的数据
(01) BufferedOutputStream的作用就是为“输出流提供缓冲功能”。
(02) DataOutputStream 是用来装饰其它输出流,将DataOutputStream和DataInputStream输入流配合使用,“允许应用程序以与机器无关方式从底层输入流中读写基本 Java 数据类型”。
(03) PrintStream 是用来装饰其它输出流。它能为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
主要了解一下Buffered流
BufferedInputStream
它是缓冲输入流。它继承于FilterInputStream。它的作用是为另一个输入流添加一些功能,例如,提供“缓冲功能”以及支持“mark()标记”和“reset()重置方法”。它本质上是通过一个内部缓冲区数组实现的
源码分析
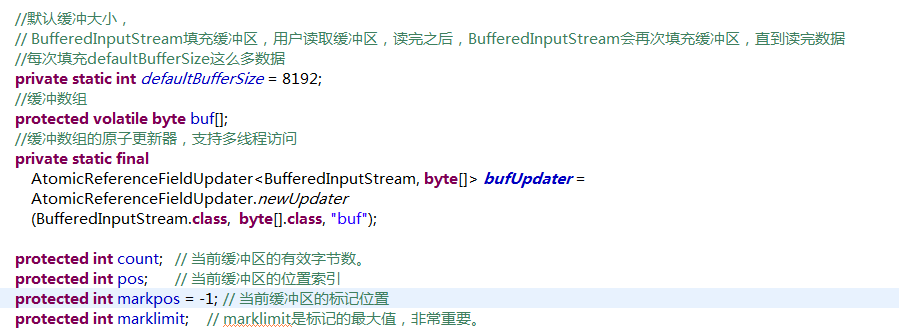
方法不再一一解读,重点讲两个方法 read1 和 fill


根据fill()中的判断条件可以分为五种情况
情况1:读取完buffer中的数据,并且buffer没有被标记
(01) if (markpos < 0) 它的作用是判断“输入流是否被标记”。若被标记,则markpos大于/等于0;否则markpos等于-1。
(02) 在这种情况下:通过getInIfOpen()获取输入流,然后接着从输入流中读取buffer.length个字节到buffer中。
(03) count = n + pos; 这是根据从输入流中读取的实际数据的多少,来更新buffer中数据的实际大小。
情况2:读取完buffer中的数据,buffer的标记位置>0,并且buffer中没有多余的空间
这种情况发生的情况是 — — 输入流中有很长的数据,我们每次从中读取一部分数据到buffer中进行操作。当我们读取完buffer中的数据之后,并且此时输入流存在标记时;那么,就发生情况2。此时,我们要保留“被标记位置”到“buffer末尾”的数据,然后再从输入流中读取下一部分的数据到buffer中。
其中,判断是否读完buffer中的数据,是通过 if (pos >= count) 来判断的;
判断输入流有没有被标记,是通过 if (markpos < 0) 来判断的。
判断buffer中没有多余的空间,是通过 if (pos >= buffer.length) 来判断的。
理解这个思想之后,我们再对这种情况下的fill()代码进行分析,就特别容易理解了。
(01) int sz = pos - markpos; 作用是“获取‘被标记位置’到‘buffer末尾’”的数据长度。
(02) System.arraycopy(buffer, markpos, buffer, 0, sz); 作用是“将buffer中从markpos开始的数据”拷贝到buffer中(从位置0开始填充,填充长度是sz)。接着,将sz赋值给pos,即pos就是“被标记位置”到“buffer末尾”的数据长度。
(03) int n = getInIfOpen().read(buffer, pos, buffer.length - pos); 从输入流中读取出“buffer.length - pos”的数据,然后填充到buffer中。
(04) 通过第(02)和(03)步组合起来的buffer,就是包含了“原始buffer被标记位置到buffer末尾”的数据,也包含了“从输入流中新读取的数据”。
情况3:读取完buffer中的数据,buffer被标记位置=0,buffer中没有多余的空间,并且buffer.length>=marklimit
执行流程如下,
(01) read() 函数中调用 fill()
(02) fill() 中的 else if (pos >= buffer.length) ...
(03) fill() 中的 else if (buffer.length >= marklimit) ...
说明:这种情况的处理非常简单。首先,就是“取消标记”,即 markpos = -1;然后,设置初始化位置为0,即pos=0;最后,再从输入流中读取下一部分数据到buffer中。
情况4:读取完buffer中的数据,buffer被标记位置=0,buffer中没有多余的空间,并且buffer.length<marklimit
执行流程如下,
(01) read() 函数中调用 fill()
(02) fill() 中的 else if (pos >= buffer.length) ...
(03) fill() 中的 else { int nsz = pos * 2; ... }
这种情况的处理非常简单。
(01) 新建一个字节数组nbuf。nbuf的大小是“pos*2”和“marklimit”中较小的那个数。
(02) 接着,将buffer中的数据拷贝到新数组nbuf中。通过System.arraycopy(buffer, 0, nbuf, 0, pos)
(03) 最后,从输入流读取部分新数据到buffer中。通过getInIfOpen().read(buffer, pos, buffer.length - pos);
注意:在这里,我们思考一个问题,“为什么需要marklimit,它的存在到底有什么意义?”我们结合“情况2”、“情况3”、“情况4”的情况来分析。
假设,marklimit是无限大的,而且我们设置了markpos。当我们从输入流中每读完一部分数据并读取下一部分数据时,都需要保存markpos所标记的数据;这就意味着,我们需要不断执行情况4中的操作,要将buffer的容量扩大……随着读取次数的增多,buffer会越来越大;这会导致我们占据的内存越来越大。所以,我们需要给出一个marklimit;当buffer>=marklimit时,就不再保存markpos的值了。
情况5:除了上面4种情况之外的情况
执行流程如下,
(01) read() 函数中调用 fill()
(02) fill() 中的 count = pos...
这种情况的处理非常简单。直接从输入流读取部分新数据到buffer中。
BufferedOutputStream
BufferedOutputStream 是缓冲输出流。它继承于FilterOutputStream。
BufferedOutputStream 的作用是为另一个输出流提供“缓冲功能”。
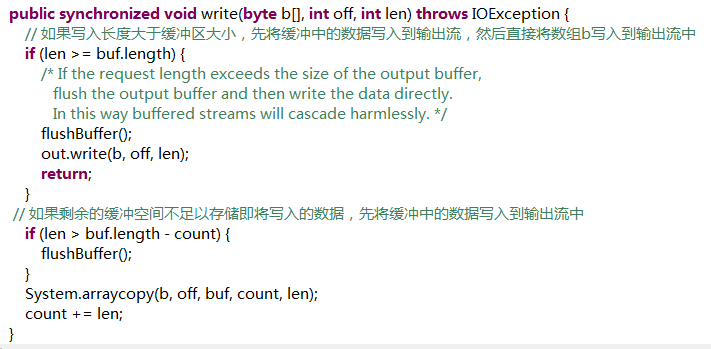
代码很简单,就不一一分析了 这里只分析一下write方法
字符流和字符流的区别和使用
字符流的实现与字节流基本相同,最大的区别是字节流是通过byte[]实现的,字符流是通过char[]实现的,这里就不在一一介绍了
按照以下分类我们就可以很清楚的了解在何时使用字节流或字符流
一、按数据源分类:
1 、是文件: FileInputStream, FileOutputStream, ( 字节流 )FileReader, FileWriter( 字符 )
2 、是 byte[] : ByteArrayInputStream, ByteArrayOutputStream( 字节流 )
3 、是 Char[]: CharArrayReader, CharArrayWriter( 字符流 )
4 、是 String: StringBufferInputStream, StringBufferOuputStream ( 字节流 )StringReader, StringWriter( 字符流 )
5 、网络数据流: InputStream, OutputStream,( 字节流 ) Reader, Writer( 字符流 )
二、按是否格式化输出分:要格式化输出: PrintStream, PrintWriter
三、按是否要缓冲分:要缓冲: BufferedInputStream, BufferedOutputStream,( 字节流 ) BufferedReader, BufferedWriter( 字符流 )
四、按数据格式分:
1 、二进制格式(只要不能确定是纯文本的) : InputStream, OutputStream 及其所有带 Stream 结束的子类
2 、纯文本格式(含纯英文与汉字或其他编码方式); Reader, Writer 及其所有带 Reader, Writer 的子类
五、按输入输出分:
1 、输入: Reader, InputStream 类型的子类
2 、输出: Writer, OutputStream 类型的子类
六、特殊需要:
1 、从 Stream 到 Reader,Writer 的转换类: InputStreamReader, OutputStreamWriter
2 、对象输入输出: ObjectInputStream, ObjectOutputStream
3 、进程间通信: PipeInputStream, PipeOutputStream, PipeReader, PipeWriter
4 、合并输入: SequenceInputStream
5 、更特殊的需要: PushbackInputStream, PushbackReader, LineNumberInputStream, LineNumberReader
原文链接:http://blog.tingyun.com/web/article/detail/351
题主将以三个章节的篇幅来讲解JAVA IO的内容 。
第一节JAVA IO包的框架体系和源码分析,第二节,序列化反序列化和IO的设计模块,第三节异步IO。
本文是第一节。
IO框架
从上图我们可以看出IO可以分为两大块 字节流和字符流
字节流是 InputStream 和 OutputStream 分别对应输入与输出
字符流是Reader和Writer分别对应输入与输出
ByteArrayInputStream
它字节数组输入流。继承于InputStream。它包含一个数组实现的缓冲区ByteArrayInputStream也是数组实现的,提供read()来读取数据,内部有一个计数器用来确定下一个要读取的字节。
分析源码
//pos是下一个会被读取字节的索引
//count字节流的长度
//pos为0就是从0开始读取
//读取下一个字节, &0xff的意思是将高8位全部置0
// 将“字节流的数据写入到字节数组b中”
// off是“字节数组b的偏移地址”,表示从数组b的off开始写入数据
// len是“写入的字节长度”
ByteArrayOutputStream
它是字节数组输出流。继承于OutputStream。ByteArrayOutputStream 实际也是数组实现的,它维护一个字节数组缓冲。缓冲区会自动扩容。
源码分析
//我们看到不带参的构造方法默认值是32 数组大小必须大于0否则会报 Negative initial size错误 ByteArrayOutputStream本质是一个byte数组
//是将字节数组buffer写入到输出流中,offset是从buffer中读取数据的起始下标,len是写入的长度。
//ensureCapacity方法是判断数组是否需要扩容
//System.arraycopy是写入的实现
//数组如果已经写满则grow
//int Capacity=oldCapacity<<1,简单粗暴容量X2
Piped(管道)
多线程可以通过管道实现线程中的通讯,在使用管道时必须PipedInputStream,PipedOutputStream配套缺一不可
PipedInputStream
//初始化管道
//链接管道
//将“管道输入流”和“管道输出流”绑定。
//调用的是PipedOutputStream的connect方法
PipedOutputStream
//指定配对的PedpedInputStream
示例
package ioEx;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
import java.io.IOException;
public class PipedStreamEx {
public static void main(String[] args) {
Writer t1 = new Writer();
Reader t2 = new Reader();
//获取输入输出流
PipedOutputStream out = t1.getOutputStream();
PipedInputStream in = t2.getInputStream();
try {
//将管道连接 也可以这样写 out.connect(in);
in.connect(out);
t1.start();
t2.start();
} catch (IOException e) {
e.printStackTrace();
}
}
}
class Reader extends Thread {
private PipedInputStream in = new PipedInputStream();
// 获得“管道输入流”对象
public PipedInputStream getInputStream(){
return in;
}
@Override
public void run(){
readOne() ;
//readWhile() ;
}
public void readOne(){
// 虽然buf的大小是2048个字节,但最多只会从输入流中读取1024个字节。
// 输入流的buffer的默认大小是1024个字节。
byte[] buf = new byte[2048];
try {
System.out.println(new String(buf,0,in.read(buf)));
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
// 从输入流中读取1024个字节
public void readWhile() {
int total=0;
while(true) {
byte[] buf = new byte[1024];
try {
int len = in.read(buf);
total += len;
System.out.println(new String(buf,0,len));
// 若读取的字节总数>1024,则退出循环。
if (total > 1024)
break;
} catch (IOException e) {
e.printStackTrace();
}
}
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
class Writer extends Thread {
private PipedOutputStream out = new PipedOutputStream();
public PipedOutputStream getOutputStream(){
return out;
}
@Override
public void run(){
writeSmall1024();
//writeBigger1024();
}
// 向输出流中写入1024字节以内的数据
private void writeSmall1024() {
String strInfo = "I < 1024" ;
try {
out.write(strInfo.getBytes());
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
// 向“管道输出流”中写入一则较长的消息
private void writeBigger1024() {
StringBuilder sb = new StringBuilder();
for (int i=0; i<103; i++)
sb.append("0123456789");
try {
// sb的长度是1030 将1030个字节写入到输出流中, 测试一次只能读取1024个字节
out.write( sb.toString().getBytes());
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}ObjectInputStream 和 ObjectOutputStream
Object流可以将对象进行序列化操作。ObjectOutputStream可以持久化存储对象, ObjectInputStream,可以读出这些这些对象。
源码很简单直接上例子,关于序列化的内容题主将于下一节叙述
package ioEx;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.util.Map;
import java.util.Map.Entry;
import java.util.HashMap;
import java.util.Iterator;
public class ObjectStreamTest {
private static final String FILE_NAME= "test.txt";
public static void main(String[] args) {
testWrite();
testRead();
}
private static void testWrite() {
try {
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(FILE_NAME));
out.writeByte((byte)1);
out.writeChar('a');
out.writeInt(20160329);
out.writeFloat(3.14F);
out.writeDouble(Math.PI);
out.writeBoolean(true);
// 写入HashMap对象
Map<String,String> map = new HashMap<String,String>();
map.put("one", "one");
map.put("two", "two");
map.put("three", "three");
out.writeObject(map);
// 写入自定义的Box对象,Box实现了Serializable接口
Test test = new Test("a", 1, "a");
out.writeObject(test);
out.close();
} catch (Exception ex) {
ex.printStackTrace();
}
}
private static void testRead() {
try {
ObjectInputStream in = new ObjectInputStream(new FileInputStream(FILE_NAME));
System.out.println(in.readBoolean());
System.out.println(in.readByte()&0xff);
System.out.println(in.readChar());
System.out.println(in.readInt());
System.out.println(in.readFloat());
System.out.println(in.readDouble());
Map<String,String> map = (HashMap) in.readObject();
Iterator<Entry<String, String>> iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry<String, String> entry = (Map.Entry<String, String>)iter.next();
System.out.println(entry.getKey()+":"+ entry.getValue());
}
Test test = (Test) in.readObject();
System.out.println("test: " + test);
in.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
class Test implements Serializable {
private String a;
private int b;
private String c;
public Test(String a, int b, String c) {
this.a = a;
this.b = b;
this.c = c;
}
@Override
public String toString() {
return "a, "+b+", c";
}
}FileInputStream 和 FileOutputStream
FileInputStream 是文件输入流,它继承于InputStream。我们使用FileInputStream从某个文件中获得输入字节。
FileOutputStream 是文件输出流,它继承于OutputStream。我们使用FileOutputStream 将数据写入 File 或 FileDescriptor 的输出流。
File操作十分简单,这里就不再展示示例了。
FilterInputStream
它的作用是用来封装其它的输入流,并为它们提供额外的功能。它的常用的子类有BufferedInputStream和DataInputStream和PrintStream。。
BufferedInputStream的作用就是为“输入流提供缓冲功能,以及mark()和reset()功能”。
DataInputStream 是用来装饰其它输入流,它允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型。应用程序可以使用 DataOutputStream(数据输出流)写入由DataInputStream(数据输入流)读取的数据
(01) BufferedOutputStream的作用就是为“输出流提供缓冲功能”。
(02) DataOutputStream 是用来装饰其它输出流,将DataOutputStream和DataInputStream输入流配合使用,“允许应用程序以与机器无关方式从底层输入流中读写基本 Java 数据类型”。
(03) PrintStream 是用来装饰其它输出流。它能为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
主要了解一下Buffered流
BufferedInputStream
它是缓冲输入流。它继承于FilterInputStream。它的作用是为另一个输入流添加一些功能,例如,提供“缓冲功能”以及支持“mark()标记”和“reset()重置方法”。它本质上是通过一个内部缓冲区数组实现的
源码分析
方法不再一一解读,重点讲两个方法 read1 和 fill
根据fill()中的判断条件可以分为五种情况
情况1:读取完buffer中的数据,并且buffer没有被标记
(01) if (markpos < 0) 它的作用是判断“输入流是否被标记”。若被标记,则markpos大于/等于0;否则markpos等于-1。
(02) 在这种情况下:通过getInIfOpen()获取输入流,然后接着从输入流中读取buffer.length个字节到buffer中。
(03) count = n + pos; 这是根据从输入流中读取的实际数据的多少,来更新buffer中数据的实际大小。
情况2:读取完buffer中的数据,buffer的标记位置>0,并且buffer中没有多余的空间
这种情况发生的情况是 — — 输入流中有很长的数据,我们每次从中读取一部分数据到buffer中进行操作。当我们读取完buffer中的数据之后,并且此时输入流存在标记时;那么,就发生情况2。此时,我们要保留“被标记位置”到“buffer末尾”的数据,然后再从输入流中读取下一部分的数据到buffer中。
其中,判断是否读完buffer中的数据,是通过 if (pos >= count) 来判断的;
判断输入流有没有被标记,是通过 if (markpos < 0) 来判断的。
判断buffer中没有多余的空间,是通过 if (pos >= buffer.length) 来判断的。
理解这个思想之后,我们再对这种情况下的fill()代码进行分析,就特别容易理解了。
(01) int sz = pos - markpos; 作用是“获取‘被标记位置’到‘buffer末尾’”的数据长度。
(02) System.arraycopy(buffer, markpos, buffer, 0, sz); 作用是“将buffer中从markpos开始的数据”拷贝到buffer中(从位置0开始填充,填充长度是sz)。接着,将sz赋值给pos,即pos就是“被标记位置”到“buffer末尾”的数据长度。
(03) int n = getInIfOpen().read(buffer, pos, buffer.length - pos); 从输入流中读取出“buffer.length - pos”的数据,然后填充到buffer中。
(04) 通过第(02)和(03)步组合起来的buffer,就是包含了“原始buffer被标记位置到buffer末尾”的数据,也包含了“从输入流中新读取的数据”。
情况3:读取完buffer中的数据,buffer被标记位置=0,buffer中没有多余的空间,并且buffer.length>=marklimit
执行流程如下,
(01) read() 函数中调用 fill()
(02) fill() 中的 else if (pos >= buffer.length) ...
(03) fill() 中的 else if (buffer.length >= marklimit) ...
说明:这种情况的处理非常简单。首先,就是“取消标记”,即 markpos = -1;然后,设置初始化位置为0,即pos=0;最后,再从输入流中读取下一部分数据到buffer中。
情况4:读取完buffer中的数据,buffer被标记位置=0,buffer中没有多余的空间,并且buffer.length<marklimit
执行流程如下,
(01) read() 函数中调用 fill()
(02) fill() 中的 else if (pos >= buffer.length) ...
(03) fill() 中的 else { int nsz = pos * 2; ... }
这种情况的处理非常简单。
(01) 新建一个字节数组nbuf。nbuf的大小是“pos*2”和“marklimit”中较小的那个数。
(02) 接着,将buffer中的数据拷贝到新数组nbuf中。通过System.arraycopy(buffer, 0, nbuf, 0, pos)
(03) 最后,从输入流读取部分新数据到buffer中。通过getInIfOpen().read(buffer, pos, buffer.length - pos);
注意:在这里,我们思考一个问题,“为什么需要marklimit,它的存在到底有什么意义?”我们结合“情况2”、“情况3”、“情况4”的情况来分析。
假设,marklimit是无限大的,而且我们设置了markpos。当我们从输入流中每读完一部分数据并读取下一部分数据时,都需要保存markpos所标记的数据;这就意味着,我们需要不断执行情况4中的操作,要将buffer的容量扩大……随着读取次数的增多,buffer会越来越大;这会导致我们占据的内存越来越大。所以,我们需要给出一个marklimit;当buffer>=marklimit时,就不再保存markpos的值了。
情况5:除了上面4种情况之外的情况
执行流程如下,
(01) read() 函数中调用 fill()
(02) fill() 中的 count = pos...
这种情况的处理非常简单。直接从输入流读取部分新数据到buffer中。
BufferedOutputStream
BufferedOutputStream 是缓冲输出流。它继承于FilterOutputStream。
BufferedOutputStream 的作用是为另一个输出流提供“缓冲功能”。
代码很简单,就不一一分析了 这里只分析一下write方法
字符流和字符流的区别和使用
字符流的实现与字节流基本相同,最大的区别是字节流是通过byte[]实现的,字符流是通过char[]实现的,这里就不在一一介绍了
按照以下分类我们就可以很清楚的了解在何时使用字节流或字符流
一、按数据源分类:
1 、是文件: FileInputStream, FileOutputStream, ( 字节流 )FileReader, FileWriter( 字符 )
2 、是 byte[] : ByteArrayInputStream, ByteArrayOutputStream( 字节流 )
3 、是 Char[]: CharArrayReader, CharArrayWriter( 字符流 )
4 、是 String: StringBufferInputStream, StringBufferOuputStream ( 字节流 )StringReader, StringWriter( 字符流 )
5 、网络数据流: InputStream, OutputStream,( 字节流 ) Reader, Writer( 字符流 )
二、按是否格式化输出分:要格式化输出: PrintStream, PrintWriter
三、按是否要缓冲分:要缓冲: BufferedInputStream, BufferedOutputStream,( 字节流 ) BufferedReader, BufferedWriter( 字符流 )
四、按数据格式分:
1 、二进制格式(只要不能确定是纯文本的) : InputStream, OutputStream 及其所有带 Stream 结束的子类
2 、纯文本格式(含纯英文与汉字或其他编码方式); Reader, Writer 及其所有带 Reader, Writer 的子类
五、按输入输出分:
1 、输入: Reader, InputStream 类型的子类
2 、输出: Writer, OutputStream 类型的子类
六、特殊需要:
1 、从 Stream 到 Reader,Writer 的转换类: InputStreamReader, OutputStreamWriter
2 、对象输入输出: ObjectInputStream, ObjectOutputStream
3 、进程间通信: PipeInputStream, PipeOutputStream, PipeReader, PipeWriter
4 、合并输入: SequenceInputStream
5 、更特殊的需要: PushbackInputStream, PushbackReader, LineNumberInputStream, LineNumberReader
原文链接:http://blog.tingyun.com/web/article/detail/351

相关文章推荐
- JDK source 之 LinkedHashMap原理浅谈
- Java的接口回调与回调函数的解析
- eclipse导入android工程无法生成R文件
- spring 定时任务的配置
- Spring 4 支持的 Java 8 特性
- 3.1java数据类型-注释-命名规范-简介
- Java——面向对象
- The substring() Method in JDK 6 and JDK 7
- Strange java.lang.ArrayIndexOutOfBoundsException thrown on jetty startup
- 简单工厂模式——加减乘除
- Supported on JUnit 4.9 through Spring 4.12
- Java 8 特性—— Streams 构造树结构
- eclipse的插件未安装成功
- XStream基本使用
- Java入门基础
- Java运算符
- 探秘Collections.sort
- 各种排序算法的分析及java实现
- JAVA获取指定格式日期
- [javaEE] web应用的目录结构&配置虚拟主机