oracle查询语句
2016-03-28 11:18
441 查看
几乎没用过oracle数据库 今天临时遇到需求,百度之后发现一篇好文章 共享之
Oracle查询语句
select * from scott.emp ;
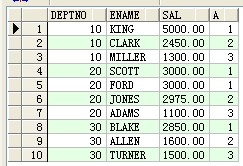
1.--dense_rank()分析函数(查找每个部门工资最高前三名员工信息)
select * from (select deptno,ename,sal,dense_rank() over(partition by deptno order by sal desc) a from scott.emp) where a<=3 order by deptno asc,sal desc ;
结果:
--rank()分析函数(运行结果与上语句相同)
select * from (select deptno,ename,sal,rank() over(partition by deptno order by sal desc) a from scott.emp ) where a<=3 order by deptno asc,sal desc ;
结果:
--row_number()分析函数(运行结果与上相同)
select * from(select deptno,ename,sal,row_number() over(partition by deptno order by sal desc) a from scott.emp) where a<=3 order by deptno asc,sal desc ;
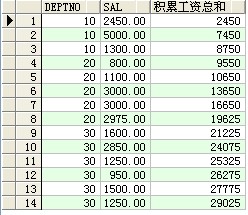
--rows unbounded preceding 分析函数(显示各部门的积累工资总和)
select deptno,sal,sum(sal) over(order by deptno asc rows unbounded preceding) 积累工资总和 from scott.emp ;
结果:
--rows 整数值 preceding(显示每最后4条记录的汇总值)
select deptno,sal,sum(sal) over(order by deptno rows 3 preceding) 每4汇总值 from scott.emp ;
结果:
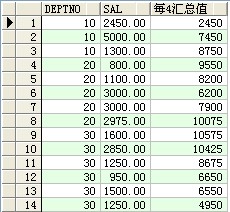
--rows between 1 preceding and 1 following(统计3条记录的汇总值【当前记录居中】)
select deptno,ename,sal,sum(sal) over(order by deptno rows between 1 preceding and 1 following) 汇总值 from scott.emp ;
结果:
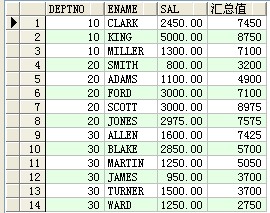
--ratio_to_report(显示员工工资及占该部门总工资的比例)
select deptno,sal,ratio_to_report(sal) over(partition by deptno) 比例 from scott.emp ;
结果:
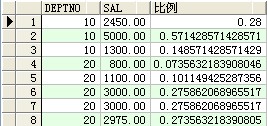
--查看所有用户
select * from dba_users ;
select count(*) from dba_users ;
select * from all_users ;
select * from user_users ;
select * from dba_roles ;
--查看用户系统权限
select * from dba_sys_privs ;
select * from user_users ;
--查看用户对象或角色权限
select * from dba_tab_privs ;
select * from all_tab_privs ;
select * from user_tab_privs ;
--查看用户或角色所拥有的角色
select * from dba_role_privs ;
select * from user_role_privs ;
-- rownum:查询10至12信息
select * from scott.emp a where rownum<=3 and a.empno not in(select b.empno from scott.emp b where rownum<=9);
结果:

--not exists;查询emp表在dept表中没有的数据
select * from scott.emp a where not exists(select * from scott.dept b where a.empno=b.deptno) ;
结果:

--rowid;查询重复数据信息
select * from scott.emp a where a.rowid>(select min(x.rowid) from scott.emp x where x.empno=a.empno);
--根据rowid来分页(一万条数据,查询10000至9980时间大概在0.03秒左右)
select * from scott.emp where rowid in(select rid from(select rownum rn,rid from(select rowid rid,empno from scott.emp order by empno desc) where rownum<10)where rn>=1)order by empno desc ;
结果:

--根据分析函数分页(一万条数据,查询10000至9980时间大概在1.01秒左右)
select * from(select a.*,row_number() over(order by empno desc) rk from scott.emp a ) where rk<10 and rk>=1;
结果:

--rownum分页(一万条数据,查询10000至9980时间大概在0.01秒左右)
select * from(select t.*,rownum rn from(select * from scott.emp order by empno desc)t where rownum<10) where rn>=1;
select * from(select a.*,rownum rn from (select * from scott.emp) a where rownum<=10) where rn>=5 ;
--left outer join:左连接
select a.*,b.* from scott.emp a left outer join scott.dept b on a.deptno=b.deptno ;
--right outer join:右连接
select a.*,b.* from scott.emp a right outer join scott.dept b on a.deptno=b.deptno ;
--inner join
select a.*,b.* from scott.emp a inner join scott.dept b on a.deptno=b.deptno ;
--full join
select a.*,b.* from scott.emp a full join scott.dept b on a.deptno=b.deptno ;
select a.*,b.* from scott.emp a,scott.dept b where a.deptno(+)=b.deptno ;
select distinct ename,sal from scott.emp a group by sal having ;
select * from scott.dept ;
select * from scott.emp ;
--case when then end (交叉报表)
select ename,sal,case deptno when 10 then '会计部' when 20 then '研究部' when 30 then '销售部' else '其他部门' end 部门 from scott.emp ;
结果:
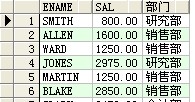
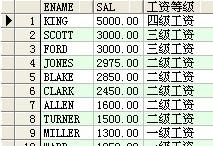
select ename,sal,case when sal>0 and sal<1500 then '一级工资' when sal>=1500 and sal<3000 then '二级工资' when sal>=3000 and sal<4500 then '三级工资' else '四级工资' end 工资等级 from scott.emp order by sal desc ;
结果:
--交叉报表是使用分组函数与case结构一起实现
select 姓名,sum(case 课程 when '数学' then 分数 end)数学,sum(case 课程 when '历史' then 分数 end)历史 from 学生 group by 姓名 ;
--decode 函数
select 姓名,sum(decode(课程,'数学',分数,null))数学,sum(decode(课程,'语文',分数,null))语文,sum(decode(课程,'历史','分数',null))历史 from 学生 group by 姓名 ;
--level。。。。connect by(层次查询)
select level,emp.* from scott.emp connect by prior empno = mgr order by level ;
结果:

--sys_connect_by_path函数
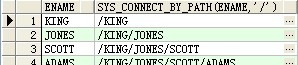
select ename,sys_connect_by_path(ename,'/') from scott.emp start with mgr is null connect by prior empno=mgr ;
结果:
--start with connect by prior 语法
select lpad(ename,3*(level),'')姓名,lpad(ename,3*(level),'')姓名 from scott.emp where job<>'CLERK' start with mgr is null connect by prior mgr = empno ;
--level与prior关键字
select level,emp.* from scott.emp start with ename='SCOTT' connect by prior empno=mgr;
select level,emp.* from scott.emp start with ename='SCOTT' connect by empno = prior mgr ;
结果:

--等值连接
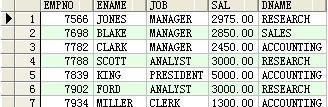
select empno,ename,job,sal,dname from scott.emp a,scott.dept b where a.deptno=b.deptno and (a.deptno=10 or sal>2500);
结果:
--非等值连接
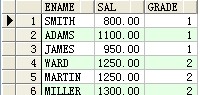
select a.ename,a.sal,b.grade from scott.emp a,scott.salgrade b where a.sal between b.losal and b.hisal ;
结果:
--自连接
select a.ename,a.sal,b.ename from scott.emp a,scott.emp b where a.mgr=b.empno ;
结果:
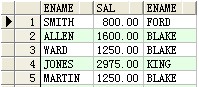
--左外连接
select a.ename,a.sal,b.ename from scott.emp a,scott.emp b where a.mgr=b.empno(+);
结果:
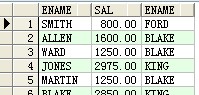
--多表连接
select * from scott.emp ,scott.dept,scott.salgrade where scott.emp.deptno=scott.dept.deptno and scott.emp.sal between scott.salgrade.losal and scott.salgrade.hisal ;
结果:

select * from scott.emp a join scott.dept b on a.deptno=b.deptno join scott.salgrade s on a.sal between s.losal and s.hisal where a.sal>1000;
select * from(select * from scott.emp a join scott.dept b on a.deptno=b.deptno where a.sal>1000) c join scott.salgrade s on c.sal between s.losal and s.hisal ;
--单行子查询
select * from scott.emp a where a.deptno=(select deptno from scott.dept where loc='NEW YORK');
select * from scott.emp a where a.deptno in (select deptno from scott.dept where loc='NEW YORK');
结果:

--单行子查询在 from 后
select scott.emp.*,(select deptno from scott.dept where loc='NEW YORK') a from scott.emp ;
--使用 in ,all,any 多行子查询
--in:表示等于查询出来的对应数据
select ename,job,sal,deptno from scott.emp where job in(select distinct job from scott.emp where deptno=10);
--all:表示大于所有括号中查询出来的对应的数据信息
select ename,sal,deptno from scott.emp where sal>all(select sal from scott.emp where deptno=30);
--any:表示大于括号查询出来的其中任意一个即可(只随机一个)
select ename,sal,deptno from scott.emp where sal>any(select sal from scott.emp where deptno=30);
--多列子查询
select ename,job,sal,deptno from scott.emp where(deptno,job)=(select deptno,job from scott.emp where ename='SCOTT');
select ename,job,sal,deptno from scott.emp where(sal,nvl(comm,-1)) in(select sal,nvl(comm,-1) from scott.emp where deptno=30);
--非成对比较
select ename,job,sal,deptno from scott.emp where sal in(select sal from scott.emp where deptno=30) and nvl(comm,-1) in(select nvl(comm,-1) from scott.emp where deptno=30);
--其他子查询
select ename,job,sal,deptno from scott.emp where exists(select null from scott.dept where scott.dept.deptno=scott.emp.deptno and scott.dept.loc='NEW YORK');
select ename,job,sal from scott.emp join(select deptno,avg(sal) avgsal,null from scott.emp group by deptno) dept on emp.deptno=dept.deptno where sal>dept.avgsal ;
create table scott.test(
ename varchar(20),
job varchar(20)
);
--drop table test ;
select * from scott.test ;
--Insert与子查询(表间数据的拷贝)
insert into scott.test(ename,job) select ename,job from scott.emp ;
--Update与子查询
update scott.test set(ename,job)=(select ename,job from scott.emp where ename='SCOTT' and deptno ='10');
--创建表时,还可以指定列名
create table scott.test_1(ename,job) as select ename,job from scott.emp ;
select * from scott.test_1 ;
--delete与子查询
delete from scott.test where ename in('');
--合并查询
--union语法(合并且去除重复行,且排序)
select ename,sal,deptno from scott.emp where deptno>10 union select ename,sal,deptno from scott.emp where deptno<30 ;
select a.deptno from scott.emp a union select b.deptno from scott.dept b ;
--union all(直接将两个结果集合并,不排序)
select ename,sal,deptno from scott.emp where deptno>10 union all select ename,sal,deptno from scott.emp where deptno<30 ;
select a.deptno from scott.emp a union all select b.deptno from scott.dept b ;
--intersect:取交集
select ename,sal,deptno from scott.emp where deptno>10 intersect select ename,sal,deptno from scott.emp where deptno<30;
--显示部门工资总和高于雇员工资总和三分之一的部门名及工资总和
select dname as 部门,sum(sal) as 工资总和 from scott.emp a,scott.dept b where a.deptno=b.deptno group by dname having sum(sal)>(select sum(sal)/3 from scott.emp c,scott.dept d where c.deptno=d.deptno);
结果:

--使用with得到以上同样的结果
with test as (select dname ,sum(sal) sumsal from scott.emp ,scott.dept where scott.emp.deptno=scott.dept.deptno group by dname) select dname as 部门,sumsal as 工资总和 from scott.test where sumsal>(select sum(sumsal)/3 from scott.test);
结果:

--分析函数
select ename,sal,sum(sal) over(partition by deptno order by sal desc) from scott.emp ;
--rows n preceding(窗口子句一)
select deptno,sal,sum(sal) over(order by sal rows 5 preceding) from scott.emp ;
结果:
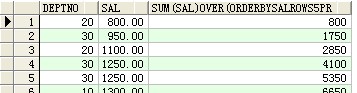
--rum(..) over(..)..
select sal,sum(1) over(order by sal) aa from scott.emp ;
select deptno,ename,sal,sum(sal) over(order by ename) 连续求和,sum(sal) over() 总和,100*round(sal/sum(sal) over(),4) as 份额 from scott.emp;
结果:
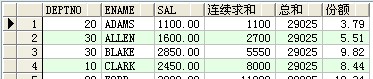
select deptno,ename,sal,sum(sal) over(partition by deptno order by ename) 部门连续求和,sum(sal) over(partition by deptno) 部门总和,100*round(sal/sum(sal) over(),4) as 总份额 from scott.emp;
结果:

select deptno,sal,rank() over (partition by deptno order by sal),dense_rank() over(partition by deptno order by sal) from scott.emp order by deptno ;
结果;

select * from (select rank() over(partition by 课程 order by 分数 desc) rk,分析函数_rank.* from 分析函数_rank) where rk<=3 ;
--dense_rank():有重复的数字不跳着排列
--row_number()
select deptno,sal,row_number() over(partition by deptno order by sal) rm from scott.emp ;
结果:
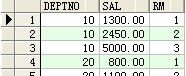
--lag()和lead()
select deptno,sal,lag(sal) over(partition by deptno order by sal) 上一个,lead(sal) over(partition by deptno order by sal) from scott.emp ;
结果:

--max(),min(),avg()
select deptno,sal,max(sal) over(partition by deptno order by sal)最大,min(sal) over(partition by deptno order by sal)最小,avg(sal) over(partition by deptno order by sal)平均 from scott.emp ;
结果:

--first_value(),last_value()
select deptno,sal,first_value(sal) over(partition by deptno)最前,last_value(sal) over(partition by deptno )最后 from scott.emp ;
结果:

--分组补充 group by grouping sets
select deptno ,sal,sum(sal) from scott.emp group by grouping sets(deptno,sal);
select null,sal,sum(sal) from scott.emp group by sal union all select deptno,null,sum(sal) from scott.emp group by deptno ;
结果:
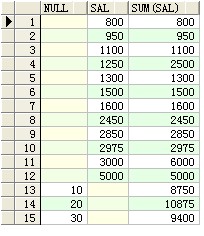
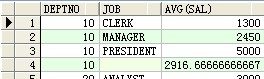
--rollup
select deptno,job,avg(sal) from scott.emp group by rollup(deptno,job) ;
--理解rollup等价于
select deptno,job,avg(sal) from scott.emp group by deptno,job union select deptno ,null,avg(sal) from scott.emp group by deptno union select null,null,avg(sal) from scott.emp ;
结果:
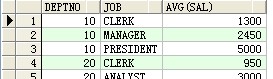
select deptno,job,avg(sal) a from scott.emp group by cube(deptno,job) ;
--理解CUBE
select deptno,job,avg(sal) from scott.emp group by cube(deptno,job) ;
--等价于
select deptno,job,avg(sal) from scott.emp group by grouping sets((deptno,job),(deptno),(job),());
结果:
--查询工资不在1500至2850之间的所有雇员名及工资
select ename,sal from scott.emp where sal not in(select sal from scott.emp where sal between 1500 and 2850 );
--部门10和30中的工资超过1500的雇员名及工资
select deptno,ename,sal from scott.emp a where a.deptno in(10,30) and a.sal>1500 order by sal desc ;
结果:
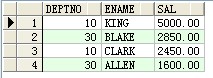
--在1981年2月1日至1981年5月1日之间雇佣的雇员名,岗位及雇佣日期,并以雇佣日期先后顺序排序
select ename as 姓名,job as 岗位,hiredate as 雇佣日期 from scott.emp a where a.hiredate between to_date('1981-02-01','yyyy-mm-dd') and to_date('1981-05-01','yyyy-mm-dd') order by a.hiredate asc ;
结果:

select * from scott.emp where hiredate >to_date('1981-02-01','yyyy-MM-dd');
--查询获得补助的所有雇佣名,工资及补助额,并以工资和补助的降序排序
select ename,sal,comm from scott.emp a where a.comm > all(0) order by comm desc;
--工资低于1500的员工增加10%的工资,工资在1500及以上的增加5%的工资并按工资高低排序(降序)
select ename as 员工姓名,sal as 补发前的工资,case when sal<1500 then (sal+sal*0.1) else (sal+sal*0.05) end 补助后的工资 from scott.emp order by sal desc ;
结果:
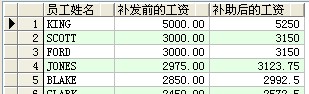
--查询公司每天,每月,每季度,每年的资金支出数额
select sum(sal/30) as 每天发的工资,sum(sal) as 每月发的工资,sum(sal)*3 as 每季度发的工资,sum(sal)*12 as 每年发的工资 from scott.emp;
结果:

--查询所有员工的平均工资,总计工资,最高工资和最低工资
select avg(sal) as 平均工资,sum(sal) as 总计工资,max(sal) as 最高工资,min(sal) as 最低工资 from scott.emp;
结果:

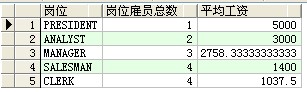
--每种岗位的雇员总数和平均工资
select job as 岗位,count(job) as 岗位雇员总数,avg(sal) as 平均工资 from scott.emp group by job order by 平均工资 desc;
结果:
--雇员总数以及获得补助的雇员数
select count(*) as 公司雇员总数,count(comm) as 获得补助的雇员人数 from scott.emp ;
--管理者的总人数
--雇员工资的最大差额
select max(sal),min(sal),(max(sal) - min(sal)) as 员工工资最大差额 from scott.emp ;
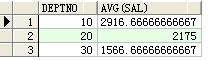
--每个部门的平均工资
select deptno,avg(sal) from scott.emp a group by a.deptno;
结果:
--查询每个岗位人数超过2人的所有职员信息
select * from scott.emp a,(select c.job,count(c.job) as sl from scott.emp c group by c.job ) b where b.sl>2 and a.job=b.job;
结果:

select * from scott.emp a where a.empno in(select mgr from scott.emp ) and (select count(mgr) from scott.emp)>2 ;
结果:
--处理重复行数据信息(删除,查找,修改)
select * from a1 a where not exists (select b.rd from (select rowid rd,row_number() over(partition by LOAN, BRANCH order by BEGIN_DATE desc) rn from a1) b where b.rn = 1 and a.rowid = b.rd);
--查询emp表数据信息重复问题
select * from scott.emp a where exists(select b.rd from(select rowid rd,row_number() over(partition by ename,job,mgr,hiredate,sal,comm,deptno order by empno asc) rn from scott.emp) b where b.rn=1 and a.rowid=b.rd);
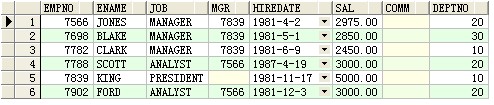
--initcap:返回字符串,字符串第一个字母大写
select initcap(ename) Upp from scott.emp ;
结果:
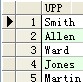
--ascii:返回与指定的字符对应的十进制数
select ascii(a.empno) as 编号,ascii(a.ename) as 姓名,ascii(a.job) as 岗位 from scott.emp a ;
结果:
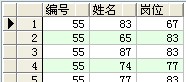
--chr:给出整数,返回对应的字符
select chr(ascii(ename)) as 姓名 from scott.emp ;
结果:

--concat:连接字符串
select concat(a.ename,a.job)|| a.empno as 字符连接 from scott.emp a;
结果:

--instr:在一个字符串中搜索指定的字符,返回发现指定的字符的位置
select instr(a.empno,a.mgr,1,1) from scott.emp a ;
--length:返回字符串的长度
select ename,length(a.ename) as 长度,a.job,length(a.job) as 长度 from scott.emp a ;
--lower:返回字符串,并将所返回的字符小写
select a.ename as 大写,lower(a.ename) as 小写 from scott.emp a ;
结果:
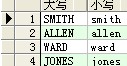
--upper:返回字符串,并将返回字符串都大写
select lower(a.ename) as 小写名字,upper(a.ename) as 大写名字 from scott.emp a ;
结果:
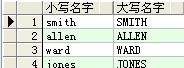
--rpad:在列的右边粘贴字符,lpad: 在列的左边粘贴字符(不够字符则用*来填满)
select lpad(rpad(a.ename,10,'*'),16,'*') as 粘贴 from scott.emp a ;
结果:
--like不同角度的使用
select * from scott.emp where ename like '%XXR%';
select * from scott.emp where ename like '%S';
select * from scott.emp where ename like 'J%';
select * from scott.emp where ename like 'S';
select * from scott.emp where ename like '%S_';
--每个部门的工资总和
select a.ename,sum(sal) from scott.emp a group by ename;
--每个部门的平均工资
select a.deptno,avg(sal) from scott.emp a group by deptno ;
--每个部门的最大工资
select a.deptno,max(sal) from scott.emp a group by deptno ;
--每个部门的最小工资
select a.deptno,min(sal) from scott.emp a group by deptno ;
--查询原工资占部门工资的比率
select deptno ,sal,ratio_to_report(sal) over(partition by deptno) sal_ratio from scott.emp ;
--查询成绩不及格的所有学生信息(提示:没有对应的表,只是意思意思。不及格人数大于等于三才能查)
select * from scott.emp where empno in(select distinct empno from scott.emp where 3<(select count(sal) from scott.emp where sal<3000) and empno in(select empno from scott.emp where sal<3000));
结果:

--查询每个部门的平均工资
select distinct deptno,avg(sal) from scott.emp group by deptno order by deptno desc;
--union组合查出的结果,但要求查出来的数据类型必须相同
select sal from scott.emp where sal >=all(select sal from scott.emp ) union select sal from scott.emp ;
select * from scott.emp a where a.empno between 7227 and 7369 ;--只能从小到大
---------创建表空间 要用拥有create tablespace权限的用户,比如sys
create tablespace tbs_dat datafile 'c:\oradata\tbs_dat.dbf' size 2000M;
---------添加数据文件
alter tablespace tbs_dat add datafile 'c:\oradata\tbs_dat2.dbf' size 100M;
---------改变数据文件大小
alter database datafile 'c:\oradata\tbs_dat.dbf' resize 250M;
---------数据文件自动扩展大小
alter database datafile 'c:\oradata\tbs_dat.dbf' autoextend on next 1m maxsize 20m;
---------修改表空间名称
alter tablespace tbs_dat rename to tbs_dat1;
---------删除表空间 and datafiles 表示同时删除物理文件
drop tablespace tbs_dat including contents and datafiles;
--substr(s1,s2,s3):截取s1字符串,从s2开始,结束s3
select substr(job,3,length(job)) from scott.emp ;
--replace:替换字符串
select replace(ename,'LL','aa') from scott.emp;
select * from scott.test;
insert into scott.test(ename,job) values('weather','好');
insert into scott.test(ename,job) values('wether','差');
--soundex:返回一个与给定的字符串读音相同的字符串
select ename from scott.test where soundex(ename)=soundex('wether');
--floor:取整数
select sal,floor(sal) as 整数 from scott.emp ;
--log(n,s):返回一个以n为低,s的对数
select empno,log(empno,2) as 对数 from scott.emp ;
--mod(n1,n2):返回一个n1除以n2的余数
select empno,mod(empno,2) as 余数 from scott.emp ;
结果:
--power(n1,n2):返回n1的n2次方根
select empno,power(empno,2) as 方根 from scott.emp ;
--round和trunc:按照指定的精度进行舍入
select round(41.5),round(-41.8),trunc(41.6),trunc(-41.9) from scott.emp ;
--sign:取数字n的符号,大于0返回1,小于0返回-1,等于0返回0
select sign(45),sign(-21),sign(0) from scott.emp ;
结果:
select * from scott.emp;
oracle相关的数据库SQL查询语句:
1. 在职员表中查询出基本工资比平均基本工资高的职工编号。
2. 查询一个或者多个部门的所有员工信息,该部门的所有员工工资都高于公司的平均工资。
3. 现有张三的出生日期:1985-01-15 01:27:36,请各自新建表,将此日期时间插入表中,并计算出张三的年龄,显示张三的生日。
4. 生日的输出格式要求为MM-DD(未满两位的用0不全),张三的生日为01-15。
5. 算年龄要求用三个方式实现。
6. 生日要求用两个方式实现。
7. 在数据库表中有以下字符数据,如:
13-1,14-2,13-15,13-2,13-108,13-3,13-10,13-200,13-18,100-11,14-1
现在希望通过一条SQL语句进行排序,并且首先要按照前半部分的数字进行排序,然后再按照后半部分的数字进行排序,输出要拍成如下所示:
13-1,13-2,13-3,13-10,13-15,13-18,13-108,13-200,14-1,14-2,100-11
数据库表名:SellRecord;字段ListNumber;
8. 显示所有雇员的姓名以及满10年服务年限后的日期。
9. 显示雇员姓名,根据其服务年限,将最老的雇员排在最前面。
10显示所有雇员的姓名和加入公司的年份和月份,按雇员受雇日期所在月排序,将最早年份的职员排在最前面。
10. 显示假设一个月为30天的情况下所有雇员的日薪金。
11. 找出在(任何年份的)2月受聘的所有雇员(用两种方式实现)。
12. 对于每个雇员,显示其加入公司的天数。
13. 以年,月和日的方式显示所有雇员的服务年限(入职多少年/入职了多少月/入职了多少天)。
14. 找出各月最后一天受雇的所有雇员。
15. 找出早于25年之前受雇的雇员(用两种方式实现)。
16. 工资最低1500的职员增加10%,1500以上的增加5%的工资,用一条update语句实现(用两种方式实现)。
17. 按照部门统计每种岗位的平均工资,要求输出的格式如下图所示:

18.

19.

20.

21,。

22.

Oracle查询语句
select * from scott.emp ;
1.--dense_rank()分析函数(查找每个部门工资最高前三名员工信息)
select * from (select deptno,ename,sal,dense_rank() over(partition by deptno order by sal desc) a from scott.emp) where a<=3 order by deptno asc,sal desc ;
结果:
--rank()分析函数(运行结果与上语句相同)
select * from (select deptno,ename,sal,rank() over(partition by deptno order by sal desc) a from scott.emp ) where a<=3 order by deptno asc,sal desc ;
结果:
--row_number()分析函数(运行结果与上相同)
select * from(select deptno,ename,sal,row_number() over(partition by deptno order by sal desc) a from scott.emp) where a<=3 order by deptno asc,sal desc ;
--rows unbounded preceding 分析函数(显示各部门的积累工资总和)
select deptno,sal,sum(sal) over(order by deptno asc rows unbounded preceding) 积累工资总和 from scott.emp ;
结果:
--rows 整数值 preceding(显示每最后4条记录的汇总值)
select deptno,sal,sum(sal) over(order by deptno rows 3 preceding) 每4汇总值 from scott.emp ;
结果:
--rows between 1 preceding and 1 following(统计3条记录的汇总值【当前记录居中】)
select deptno,ename,sal,sum(sal) over(order by deptno rows between 1 preceding and 1 following) 汇总值 from scott.emp ;
结果:
--ratio_to_report(显示员工工资及占该部门总工资的比例)
select deptno,sal,ratio_to_report(sal) over(partition by deptno) 比例 from scott.emp ;
结果:
--查看所有用户
select * from dba_users ;
select count(*) from dba_users ;
select * from all_users ;
select * from user_users ;
select * from dba_roles ;
--查看用户系统权限
select * from dba_sys_privs ;
select * from user_users ;
--查看用户对象或角色权限
select * from dba_tab_privs ;
select * from all_tab_privs ;
select * from user_tab_privs ;
--查看用户或角色所拥有的角色
select * from dba_role_privs ;
select * from user_role_privs ;
-- rownum:查询10至12信息
select * from scott.emp a where rownum<=3 and a.empno not in(select b.empno from scott.emp b where rownum<=9);
结果:
--not exists;查询emp表在dept表中没有的数据
select * from scott.emp a where not exists(select * from scott.dept b where a.empno=b.deptno) ;
结果:
--rowid;查询重复数据信息
select * from scott.emp a where a.rowid>(select min(x.rowid) from scott.emp x where x.empno=a.empno);
--根据rowid来分页(一万条数据,查询10000至9980时间大概在0.03秒左右)
select * from scott.emp where rowid in(select rid from(select rownum rn,rid from(select rowid rid,empno from scott.emp order by empno desc) where rownum<10)where rn>=1)order by empno desc ;
结果:
--根据分析函数分页(一万条数据,查询10000至9980时间大概在1.01秒左右)
select * from(select a.*,row_number() over(order by empno desc) rk from scott.emp a ) where rk<10 and rk>=1;
结果:
--rownum分页(一万条数据,查询10000至9980时间大概在0.01秒左右)
select * from(select t.*,rownum rn from(select * from scott.emp order by empno desc)t where rownum<10) where rn>=1;
select * from(select a.*,rownum rn from (select * from scott.emp) a where rownum<=10) where rn>=5 ;
--left outer join:左连接
select a.*,b.* from scott.emp a left outer join scott.dept b on a.deptno=b.deptno ;
--right outer join:右连接
select a.*,b.* from scott.emp a right outer join scott.dept b on a.deptno=b.deptno ;
--inner join
select a.*,b.* from scott.emp a inner join scott.dept b on a.deptno=b.deptno ;
--full join
select a.*,b.* from scott.emp a full join scott.dept b on a.deptno=b.deptno ;
select a.*,b.* from scott.emp a,scott.dept b where a.deptno(+)=b.deptno ;
select distinct ename,sal from scott.emp a group by sal having ;
select * from scott.dept ;
select * from scott.emp ;
--case when then end (交叉报表)
select ename,sal,case deptno when 10 then '会计部' when 20 then '研究部' when 30 then '销售部' else '其他部门' end 部门 from scott.emp ;
结果:
select ename,sal,case when sal>0 and sal<1500 then '一级工资' when sal>=1500 and sal<3000 then '二级工资' when sal>=3000 and sal<4500 then '三级工资' else '四级工资' end 工资等级 from scott.emp order by sal desc ;
结果:
--交叉报表是使用分组函数与case结构一起实现
select 姓名,sum(case 课程 when '数学' then 分数 end)数学,sum(case 课程 when '历史' then 分数 end)历史 from 学生 group by 姓名 ;
--decode 函数
select 姓名,sum(decode(课程,'数学',分数,null))数学,sum(decode(课程,'语文',分数,null))语文,sum(decode(课程,'历史','分数',null))历史 from 学生 group by 姓名 ;
--level。。。。connect by(层次查询)
select level,emp.* from scott.emp connect by prior empno = mgr order by level ;
结果:
--sys_connect_by_path函数
select ename,sys_connect_by_path(ename,'/') from scott.emp start with mgr is null connect by prior empno=mgr ;
结果:
--start with connect by prior 语法
select lpad(ename,3*(level),'')姓名,lpad(ename,3*(level),'')姓名 from scott.emp where job<>'CLERK' start with mgr is null connect by prior mgr = empno ;
--level与prior关键字
select level,emp.* from scott.emp start with ename='SCOTT' connect by prior empno=mgr;
select level,emp.* from scott.emp start with ename='SCOTT' connect by empno = prior mgr ;
结果:
--等值连接
select empno,ename,job,sal,dname from scott.emp a,scott.dept b where a.deptno=b.deptno and (a.deptno=10 or sal>2500);
结果:
--非等值连接
select a.ename,a.sal,b.grade from scott.emp a,scott.salgrade b where a.sal between b.losal and b.hisal ;
结果:
--自连接
select a.ename,a.sal,b.ename from scott.emp a,scott.emp b where a.mgr=b.empno ;
结果:
--左外连接
select a.ename,a.sal,b.ename from scott.emp a,scott.emp b where a.mgr=b.empno(+);
结果:
--多表连接
select * from scott.emp ,scott.dept,scott.salgrade where scott.emp.deptno=scott.dept.deptno and scott.emp.sal between scott.salgrade.losal and scott.salgrade.hisal ;
结果:
select * from scott.emp a join scott.dept b on a.deptno=b.deptno join scott.salgrade s on a.sal between s.losal and s.hisal where a.sal>1000;
select * from(select * from scott.emp a join scott.dept b on a.deptno=b.deptno where a.sal>1000) c join scott.salgrade s on c.sal between s.losal and s.hisal ;
--单行子查询
select * from scott.emp a where a.deptno=(select deptno from scott.dept where loc='NEW YORK');
select * from scott.emp a where a.deptno in (select deptno from scott.dept where loc='NEW YORK');
结果:
--单行子查询在 from 后
select scott.emp.*,(select deptno from scott.dept where loc='NEW YORK') a from scott.emp ;
--使用 in ,all,any 多行子查询
--in:表示等于查询出来的对应数据
select ename,job,sal,deptno from scott.emp where job in(select distinct job from scott.emp where deptno=10);
--all:表示大于所有括号中查询出来的对应的数据信息
select ename,sal,deptno from scott.emp where sal>all(select sal from scott.emp where deptno=30);
--any:表示大于括号查询出来的其中任意一个即可(只随机一个)
select ename,sal,deptno from scott.emp where sal>any(select sal from scott.emp where deptno=30);
--多列子查询
select ename,job,sal,deptno from scott.emp where(deptno,job)=(select deptno,job from scott.emp where ename='SCOTT');
select ename,job,sal,deptno from scott.emp where(sal,nvl(comm,-1)) in(select sal,nvl(comm,-1) from scott.emp where deptno=30);
--非成对比较
select ename,job,sal,deptno from scott.emp where sal in(select sal from scott.emp where deptno=30) and nvl(comm,-1) in(select nvl(comm,-1) from scott.emp where deptno=30);
--其他子查询
select ename,job,sal,deptno from scott.emp where exists(select null from scott.dept where scott.dept.deptno=scott.emp.deptno and scott.dept.loc='NEW YORK');
select ename,job,sal from scott.emp join(select deptno,avg(sal) avgsal,null from scott.emp group by deptno) dept on emp.deptno=dept.deptno where sal>dept.avgsal ;
create table scott.test(
ename varchar(20),
job varchar(20)
);
--drop table test ;
select * from scott.test ;
--Insert与子查询(表间数据的拷贝)
insert into scott.test(ename,job) select ename,job from scott.emp ;
--Update与子查询
update scott.test set(ename,job)=(select ename,job from scott.emp where ename='SCOTT' and deptno ='10');
--创建表时,还可以指定列名
create table scott.test_1(ename,job) as select ename,job from scott.emp ;
select * from scott.test_1 ;
--delete与子查询
delete from scott.test where ename in('');
--合并查询
--union语法(合并且去除重复行,且排序)
select ename,sal,deptno from scott.emp where deptno>10 union select ename,sal,deptno from scott.emp where deptno<30 ;
select a.deptno from scott.emp a union select b.deptno from scott.dept b ;
--union all(直接将两个结果集合并,不排序)
select ename,sal,deptno from scott.emp where deptno>10 union all select ename,sal,deptno from scott.emp where deptno<30 ;
select a.deptno from scott.emp a union all select b.deptno from scott.dept b ;
--intersect:取交集
select ename,sal,deptno from scott.emp where deptno>10 intersect select ename,sal,deptno from scott.emp where deptno<30;
--显示部门工资总和高于雇员工资总和三分之一的部门名及工资总和
select dname as 部门,sum(sal) as 工资总和 from scott.emp a,scott.dept b where a.deptno=b.deptno group by dname having sum(sal)>(select sum(sal)/3 from scott.emp c,scott.dept d where c.deptno=d.deptno);
结果:
--使用with得到以上同样的结果
with test as (select dname ,sum(sal) sumsal from scott.emp ,scott.dept where scott.emp.deptno=scott.dept.deptno group by dname) select dname as 部门,sumsal as 工资总和 from scott.test where sumsal>(select sum(sumsal)/3 from scott.test);
结果:
--分析函数
select ename,sal,sum(sal) over(partition by deptno order by sal desc) from scott.emp ;
--rows n preceding(窗口子句一)
select deptno,sal,sum(sal) over(order by sal rows 5 preceding) from scott.emp ;
结果:
--rum(..) over(..)..
select sal,sum(1) over(order by sal) aa from scott.emp ;
select deptno,ename,sal,sum(sal) over(order by ename) 连续求和,sum(sal) over() 总和,100*round(sal/sum(sal) over(),4) as 份额 from scott.emp;
结果:
select deptno,ename,sal,sum(sal) over(partition by deptno order by ename) 部门连续求和,sum(sal) over(partition by deptno) 部门总和,100*round(sal/sum(sal) over(),4) as 总份额 from scott.emp;
结果:
select deptno,sal,rank() over (partition by deptno order by sal),dense_rank() over(partition by deptno order by sal) from scott.emp order by deptno ;
结果;
select * from (select rank() over(partition by 课程 order by 分数 desc) rk,分析函数_rank.* from 分析函数_rank) where rk<=3 ;
--dense_rank():有重复的数字不跳着排列
--row_number()
select deptno,sal,row_number() over(partition by deptno order by sal) rm from scott.emp ;
结果:
--lag()和lead()
select deptno,sal,lag(sal) over(partition by deptno order by sal) 上一个,lead(sal) over(partition by deptno order by sal) from scott.emp ;
结果:
--max(),min(),avg()
select deptno,sal,max(sal) over(partition by deptno order by sal)最大,min(sal) over(partition by deptno order by sal)最小,avg(sal) over(partition by deptno order by sal)平均 from scott.emp ;
结果:
--first_value(),last_value()
select deptno,sal,first_value(sal) over(partition by deptno)最前,last_value(sal) over(partition by deptno )最后 from scott.emp ;
结果:
--分组补充 group by grouping sets
select deptno ,sal,sum(sal) from scott.emp group by grouping sets(deptno,sal);
select null,sal,sum(sal) from scott.emp group by sal union all select deptno,null,sum(sal) from scott.emp group by deptno ;
结果:
--rollup
select deptno,job,avg(sal) from scott.emp group by rollup(deptno,job) ;
--理解rollup等价于
select deptno,job,avg(sal) from scott.emp group by deptno,job union select deptno ,null,avg(sal) from scott.emp group by deptno union select null,null,avg(sal) from scott.emp ;
结果:
select deptno,job,avg(sal) a from scott.emp group by cube(deptno,job) ;
--理解CUBE
select deptno,job,avg(sal) from scott.emp group by cube(deptno,job) ;
--等价于
select deptno,job,avg(sal) from scott.emp group by grouping sets((deptno,job),(deptno),(job),());
结果:
--查询工资不在1500至2850之间的所有雇员名及工资
select ename,sal from scott.emp where sal not in(select sal from scott.emp where sal between 1500 and 2850 );
--部门10和30中的工资超过1500的雇员名及工资
select deptno,ename,sal from scott.emp a where a.deptno in(10,30) and a.sal>1500 order by sal desc ;
结果:
--在1981年2月1日至1981年5月1日之间雇佣的雇员名,岗位及雇佣日期,并以雇佣日期先后顺序排序
select ename as 姓名,job as 岗位,hiredate as 雇佣日期 from scott.emp a where a.hiredate between to_date('1981-02-01','yyyy-mm-dd') and to_date('1981-05-01','yyyy-mm-dd') order by a.hiredate asc ;
结果:
select * from scott.emp where hiredate >to_date('1981-02-01','yyyy-MM-dd');
--查询获得补助的所有雇佣名,工资及补助额,并以工资和补助的降序排序
select ename,sal,comm from scott.emp a where a.comm > all(0) order by comm desc;
--工资低于1500的员工增加10%的工资,工资在1500及以上的增加5%的工资并按工资高低排序(降序)
select ename as 员工姓名,sal as 补发前的工资,case when sal<1500 then (sal+sal*0.1) else (sal+sal*0.05) end 补助后的工资 from scott.emp order by sal desc ;
结果:
--查询公司每天,每月,每季度,每年的资金支出数额
select sum(sal/30) as 每天发的工资,sum(sal) as 每月发的工资,sum(sal)*3 as 每季度发的工资,sum(sal)*12 as 每年发的工资 from scott.emp;
结果:
--查询所有员工的平均工资,总计工资,最高工资和最低工资
select avg(sal) as 平均工资,sum(sal) as 总计工资,max(sal) as 最高工资,min(sal) as 最低工资 from scott.emp;
结果:
--每种岗位的雇员总数和平均工资
select job as 岗位,count(job) as 岗位雇员总数,avg(sal) as 平均工资 from scott.emp group by job order by 平均工资 desc;
结果:
--雇员总数以及获得补助的雇员数
select count(*) as 公司雇员总数,count(comm) as 获得补助的雇员人数 from scott.emp ;
--管理者的总人数
--雇员工资的最大差额
select max(sal),min(sal),(max(sal) - min(sal)) as 员工工资最大差额 from scott.emp ;
--每个部门的平均工资
select deptno,avg(sal) from scott.emp a group by a.deptno;
结果:
--查询每个岗位人数超过2人的所有职员信息
select * from scott.emp a,(select c.job,count(c.job) as sl from scott.emp c group by c.job ) b where b.sl>2 and a.job=b.job;
结果:
select * from scott.emp a where a.empno in(select mgr from scott.emp ) and (select count(mgr) from scott.emp)>2 ;
结果:
--处理重复行数据信息(删除,查找,修改)
select * from a1 a where not exists (select b.rd from (select rowid rd,row_number() over(partition by LOAN, BRANCH order by BEGIN_DATE desc) rn from a1) b where b.rn = 1 and a.rowid = b.rd);
--查询emp表数据信息重复问题
select * from scott.emp a where exists(select b.rd from(select rowid rd,row_number() over(partition by ename,job,mgr,hiredate,sal,comm,deptno order by empno asc) rn from scott.emp) b where b.rn=1 and a.rowid=b.rd);
--initcap:返回字符串,字符串第一个字母大写
select initcap(ename) Upp from scott.emp ;
结果:
--ascii:返回与指定的字符对应的十进制数
select ascii(a.empno) as 编号,ascii(a.ename) as 姓名,ascii(a.job) as 岗位 from scott.emp a ;
结果:
--chr:给出整数,返回对应的字符
select chr(ascii(ename)) as 姓名 from scott.emp ;
结果:
--concat:连接字符串
select concat(a.ename,a.job)|| a.empno as 字符连接 from scott.emp a;
结果:
--instr:在一个字符串中搜索指定的字符,返回发现指定的字符的位置
select instr(a.empno,a.mgr,1,1) from scott.emp a ;
--length:返回字符串的长度
select ename,length(a.ename) as 长度,a.job,length(a.job) as 长度 from scott.emp a ;
--lower:返回字符串,并将所返回的字符小写
select a.ename as 大写,lower(a.ename) as 小写 from scott.emp a ;
结果:
--upper:返回字符串,并将返回字符串都大写
select lower(a.ename) as 小写名字,upper(a.ename) as 大写名字 from scott.emp a ;
结果:
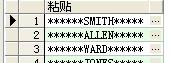
--rpad:在列的右边粘贴字符,lpad: 在列的左边粘贴字符(不够字符则用*来填满)
select lpad(rpad(a.ename,10,'*'),16,'*') as 粘贴 from scott.emp a ;
结果:
--like不同角度的使用
select * from scott.emp where ename like '%XXR%';
select * from scott.emp where ename like '%S';
select * from scott.emp where ename like 'J%';
select * from scott.emp where ename like 'S';
select * from scott.emp where ename like '%S_';
--每个部门的工资总和
select a.ename,sum(sal) from scott.emp a group by ename;
--每个部门的平均工资
select a.deptno,avg(sal) from scott.emp a group by deptno ;
--每个部门的最大工资
select a.deptno,max(sal) from scott.emp a group by deptno ;
--每个部门的最小工资
select a.deptno,min(sal) from scott.emp a group by deptno ;
--查询原工资占部门工资的比率
select deptno ,sal,ratio_to_report(sal) over(partition by deptno) sal_ratio from scott.emp ;
--查询成绩不及格的所有学生信息(提示:没有对应的表,只是意思意思。不及格人数大于等于三才能查)
select * from scott.emp where empno in(select distinct empno from scott.emp where 3<(select count(sal) from scott.emp where sal<3000) and empno in(select empno from scott.emp where sal<3000));
结果:
--查询每个部门的平均工资
select distinct deptno,avg(sal) from scott.emp group by deptno order by deptno desc;
--union组合查出的结果,但要求查出来的数据类型必须相同
select sal from scott.emp where sal >=all(select sal from scott.emp ) union select sal from scott.emp ;
select * from scott.emp a where a.empno between 7227 and 7369 ;--只能从小到大
---------创建表空间 要用拥有create tablespace权限的用户,比如sys
create tablespace tbs_dat datafile 'c:\oradata\tbs_dat.dbf' size 2000M;
---------添加数据文件
alter tablespace tbs_dat add datafile 'c:\oradata\tbs_dat2.dbf' size 100M;
---------改变数据文件大小
alter database datafile 'c:\oradata\tbs_dat.dbf' resize 250M;
---------数据文件自动扩展大小
alter database datafile 'c:\oradata\tbs_dat.dbf' autoextend on next 1m maxsize 20m;
---------修改表空间名称
alter tablespace tbs_dat rename to tbs_dat1;
---------删除表空间 and datafiles 表示同时删除物理文件
drop tablespace tbs_dat including contents and datafiles;
--substr(s1,s2,s3):截取s1字符串,从s2开始,结束s3
select substr(job,3,length(job)) from scott.emp ;
--replace:替换字符串
select replace(ename,'LL','aa') from scott.emp;
select * from scott.test;
insert into scott.test(ename,job) values('weather','好');
insert into scott.test(ename,job) values('wether','差');
--soundex:返回一个与给定的字符串读音相同的字符串
select ename from scott.test where soundex(ename)=soundex('wether');
--floor:取整数
select sal,floor(sal) as 整数 from scott.emp ;
--log(n,s):返回一个以n为低,s的对数
select empno,log(empno,2) as 对数 from scott.emp ;
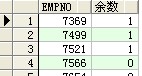
--mod(n1,n2):返回一个n1除以n2的余数
select empno,mod(empno,2) as 余数 from scott.emp ;
结果:
--power(n1,n2):返回n1的n2次方根
select empno,power(empno,2) as 方根 from scott.emp ;
--round和trunc:按照指定的精度进行舍入
select round(41.5),round(-41.8),trunc(41.6),trunc(-41.9) from scott.emp ;
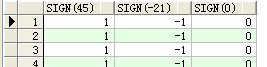
--sign:取数字n的符号,大于0返回1,小于0返回-1,等于0返回0
select sign(45),sign(-21),sign(0) from scott.emp ;
结果:
select * from scott.emp;
oracle相关的数据库SQL查询语句:
1. 在职员表中查询出基本工资比平均基本工资高的职工编号。
2. 查询一个或者多个部门的所有员工信息,该部门的所有员工工资都高于公司的平均工资。
3. 现有张三的出生日期:1985-01-15 01:27:36,请各自新建表,将此日期时间插入表中,并计算出张三的年龄,显示张三的生日。
4. 生日的输出格式要求为MM-DD(未满两位的用0不全),张三的生日为01-15。
5. 算年龄要求用三个方式实现。
6. 生日要求用两个方式实现。
7. 在数据库表中有以下字符数据,如:
13-1,14-2,13-15,13-2,13-108,13-3,13-10,13-200,13-18,100-11,14-1
现在希望通过一条SQL语句进行排序,并且首先要按照前半部分的数字进行排序,然后再按照后半部分的数字进行排序,输出要拍成如下所示:
13-1,13-2,13-3,13-10,13-15,13-18,13-108,13-200,14-1,14-2,100-11
数据库表名:SellRecord;字段ListNumber;
8. 显示所有雇员的姓名以及满10年服务年限后的日期。
9. 显示雇员姓名,根据其服务年限,将最老的雇员排在最前面。
10显示所有雇员的姓名和加入公司的年份和月份,按雇员受雇日期所在月排序,将最早年份的职员排在最前面。
10. 显示假设一个月为30天的情况下所有雇员的日薪金。
11. 找出在(任何年份的)2月受聘的所有雇员(用两种方式实现)。
12. 对于每个雇员,显示其加入公司的天数。
13. 以年,月和日的方式显示所有雇员的服务年限(入职多少年/入职了多少月/入职了多少天)。
14. 找出各月最后一天受雇的所有雇员。
15. 找出早于25年之前受雇的雇员(用两种方式实现)。
16. 工资最低1500的职员增加10%,1500以上的增加5%的工资,用一条update语句实现(用两种方式实现)。
17. 按照部门统计每种岗位的平均工资,要求输出的格式如下图所示:
18.
19.
20.
21,。
22.
Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是对于每个组返回多行,而聚合函数对于每个组只返回一行。 一、 over函数 over函数指定了分析函数工作的数据窗口的大小,这个数据窗口大小可能会随着行的变化而变化,例如: over(order by salary)按照salary排序进行累计,order by是个默认的开窗函数 over(partition by deptno) 按照部门分区 over(order by salary range between 50 preceding and 150 following)每行对应的数据窗口是之前行幅度值不超过50,之后行幅度值不超过150的数据记录 over(order by salary rows between 50 perceding and 150 following)前50行,后150行 over(order by salary rows between unbounded preceding and unbounded following)所有行 over(order by salary range between unbounded preceding and unbounded following)所有行 二、 sum函数 功能描述:该函数计算组中表达式的累积和。 SAMPLE:下例计算同一经理下员工的薪水累积值 SELECT manager_id, last_name, salary, SUM (salary) OVER (PARTITION BY manager_id ORDER BY salary RANGE UNBOUNDED PRECEDING) l_csum FROM employees WHERE manager_id in (101,103,108); 三、 应用实例 1, 测试环境设置 设有销售表t_sales (subcompany,branch,region,customer,sale_qty); 存储客户的销售明细,记录如下所示。 Subcompany Branch Region Customer Sale_qty 北京分公司 北京经营部 片区1 客户1 1 北京分公司 北京经营部 片区1 客户1 1 北京分公司 北京经营部 片区1 客户2 1 北京分公司 北京经营部 片区1 客户2 1 北京分公司 北京经营部 片区2 客户1 1 北京分公司 北京经营部 片区2 客户1 1 北京分公司 北京经营部 片区2 客户2 1 北京分公司 北京经营部 片区2 客户2 1 北京分公司 其他经营部 片区1 客户1 1 北京分公司 其他经营部 片区1 客户1 1 北京分公司 其他经营部 片区1 客户2 1 北京分公司 其他经营部 片区1 客户2 1 北京分公司 其他经营部 片区2 客户1 1 北京分公司 其他经营部 片区2 客户1 1 北京分公司 其他经营部 片区2 客户2 1 北京分公司 其他经营部 片区2 客户2 1 create table t_sales( subcompany varchar2(40), branch varchar2(40), region varchar2(40), customer varchar2(40), sale_qty numeric(18,4) ); comment on table t_sales is '销售表,分析函数测试'; comment on column t_sales.subcompany is '分公司'; comment on column t_sales.branch is '经营部'; comment on column t_sales.region is '片区'; comment on column t_sales.customer is '客户'; comment on column t_sales.sale_qty is '销售数量'; 2,问题提出 现在要求给出销售汇总报表,报表中需要提供的数据包括客户汇总,和客户在其上级机构中的销售比例。 Subcompany Branch Region Customer Sale_qty Rate 北京分公司 北京经营部 片区1 客户1 2 50% 北京分公司 北京经营部 片区1 客户2 2 50% 北京分公司 北京经营部 片区1 小计 4 50% 北京分公司 北京经营部 片区2 客户1 2 50% 北京分公司 北京经营部 片区2 客户2 2 50% 北京分公司 北京经营部 片区2 小计 4 50% 北京分公司 北京经营部 小计 小计 8 50% 北京分公司 北京经营部 片区1 客户1 2 50% 北京分公司 北京经营部 片区1 客户2 2 50% 北京分公司 北京经营部 片区1 小计 4 50% 北京分公司 北京经营部 片区2 客户1 2 50% 北京分公司 北京经营部 片区2 客户2 2 50% 北京分公司 北京经营部 片区2 小计 4 50% 北京分公司 北京经营部 小计 小计 8 50% 北京分公司 小计 小计 小计 16 100% 3,解决方案(方案1) 首先我们可以使用oracle对group by 的扩展功能rollup得到如下的聚合汇总结果。 select subcompany, branch, region, customer, sum(sale_qty) sale_qty from t_sales group by rollup(subcompany,branch,region,customer); Subcompany Branch Region Customer Sale_qty 北京分公司 北京经营部 片区1 客户1 2 北京分公司 北京经营部 片区1 客户2 2 北京分公司 北京经营部 片区1 4 北京分公司 北京经营部 片区2 客户1 2 北京分公司 北京经营部 片区2 客户2 2 北京分公司 北京经营部 片区2 4 北京分公司 北京经营部 8 北京分公司 其他经营部 片区1 客户1 2 北京分公司 其他经营部 片区1 客户2 2 北京分公司 其他经营部 片区1 4 北京分公司 其他经营部 片区2 客户1 2 北京分公司 其他经营部 片区2 客户2 2 北京分公司 其他经营部 片区2 4 北京分公司 其他经营部 8 北京分公司 16 16 分析上面的临时结果,我们看到: 明细到客户的汇总信息,其除数为当前的sum(sale_qty),被除数应该是到片区的小计信息。 明细到片区的汇总信息,其除数为片区的sum(sale_qty),被除数为聚合到经营部的汇总数据。 。。。 考虑到上述因素,我们可以使用oracle的开窗函数over,将数据定位到我们需要定位的记录。如下代码中,我们利用开窗函数over直接将数据定位到其上次的小计位置。 over(partition by decode(f_branch, 1, null, subcompany), decode(f_branch, 1, null, decode(f_region, 1, null, branch)), decode(f_branch, 1, null, decode(f_region, 1, null, decode(f_customer, 1, null, region))), null) 经整理后的查询语句如下。 select subcompany, decode(f_branch, 1,subcompany||'(С¼Æ)', branch), decode(f_region,1,branch||'(С¼Æ)',region), decode(f_customer,1,region||'(С¼Æ)', customer), sale_qty, trim(to_char(round(sale_qty/ sum(sale_qty) over(partition by decode(f_branch, 1, null, subcompany), decode(f_branch, 1, null, decode(f_region, 1, null, branch)), decode(f_branch, 1, null, decode(f_region, 1, null, decode(f_customer, 1, null, region))), null),2) *100,99990.99)) from (select grouping(branch) f_branch, grouping(region) f_region, grouping(customer) f_customer, subcompany, branch, region, customer, sum(sale_qty) sale_qty from t_sales group by subcompany, rollup(branch, region, customer)) Subcompany Branch Region Customer Sale_qty Rate 北京分公司 北京经营部 片区1 客户1 2 50.00 北京分公司 北京经营部 片区1 客户2 2 50.00 北京分公司 北京经营部 片区2 客户1 2 50.00 北京分公司 北京经营部 片区2 客户2 2 50.00 北京分公司 北京经营部 片区1 片区1(小计) 4 50.00 北京分公司 北京经营部 片区2 片区2(小计) 4 50.00 北京分公司 其他经营部 片区1 客户1 2 50.00 北京分公司 其他经营部 片区1 客户2 2 50.00 北京分公司 其他经营部 片区2 客户1 2 50.00 北京分公司 其他经营部 片区2 客户2 2 50.00 北京分公司 其他经营部 片区1 片区1(小计) 4 50.00 北京分公司 其他经营部 片区2 片区2(小计) 4 50.00 北京分公司 北京经营部 北京经营部(小计) (小计) 8 50.00 北京分公司 其他经营部 其他经营部(小计) (小计) 8 50.00 北京分公司 北京分公司(小计) (小计) (小计) 16 100.00 北京分公司 北京经营部 片区1 客户1 2 50.00 4,可能的另外一种解决方式(方案2) select subcompany, decode(f_branch, 1,subcompany||'(С¼Æ)', branch), decode(f_region,1,branch||'(С¼Æ)',region), decode(f_customer,1,region||'(С¼Æ)', customer), sale_qty, /* trim(to_char(round(sale_qty/*/ decode(f_branch+f_region+f_customer, 0, (sum(sale_qty) over(partition by subcompany,branch,region))/2, 1, (sum(sale_qty) over(partition by subcompany,branch))/3, 2, (sum(sale_qty) over(partition by subcompany))/4 , sum(sale_qty) over()/4 )/* ,2) *100,99990.99))*/ from (select grouping(branch) f_branch, grouping(region) f_region, grouping(customer) f_customer, subcompany, branch, region, customer, sum(sale_qty) sale_qty from t_sales group by subcompany, rollup(branch, region, customer)) 在上面的解决方式中,最大的问题在于开窗函数过大。导致每次计算涉及到的行数过多,影响到执行的速度和效率。并且需要额外的计算处理清除多余叠加进去的数值 。

相关文章推荐
- Oracle:Ora-01791 不是Selected表达式
- oracle中with的用法及用处
- ORACLE使用WITH AS和HINT MATERIALIZE优化SQL解决FILTER效率低下
- oracle新增修改表字段+注释
- oracle数据库导入导出命令
- ORACLE自动生成8位带数字和字母的随机密码
- Oracle 11g 学习3——表空间操作
- Oracle 迁移到 Mycat 简单测试
- Oracle安装错误ora-00922(缺少或无效选项)
- mycat 平台上实现将数据从oracle迁移到mysql
- Linux下安装cx-Oracle小记
- 如何解决w8.1系统安装oracle 11g出现未找到文件的问题
- Oracle视图
- Oracle的一些简单语句
- Oracle存储过程基本语法介绍
- oracle_触发器监控修改字段的客户端IP、用户名、新旧值
- 个人常用Oracle SQL优化工具(脚本)介绍(未完成)
- Oracle VM + centos7.1+openstack kilo 多结点安装教程---基础环境配置(1)
- Oracle 索引维护
- Oracle Data Integrator 12c 安装(ODI安装)