Generative learning algorithm
2016-03-28 10:08
344 查看
本讲大纲:
1.生成学习算法(Generative learning algorithm)2.高斯判别分析(GDA,Gaussian Discriminant Analysis)
3.朴素贝叶斯(Naive Bayes)
4.拉普拉斯平滑(Laplace smoothing)
1.生成学习算法
判别学习算法(discriminative learning algorithm):直接学习p(y|x)(比如说logistic回归)或者说是从输入直接映射到{0,1}.生成学习算法(generative learning algorithm):对p(x|y)(和p(y))进行建模.
简单的来说,判别学习算法的模型是通过一条分隔线把两种类别区分开,而生成学习算法是对两种可能的结果分别进行建模,然后分别和输入进行比对,计算出相应的概率。
比如说良性肿瘤和恶性肿瘤的问题,对良性肿瘤建立model1(y=0),对恶性肿瘤建立model2(y=1),p(x|y=0)表示是良性肿瘤的概率,p(x|y=1)表示是恶性肿瘤的概率.
根据贝叶斯公式(Bayes rule)推导出y在给定x的概率为:
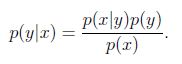
2.高斯判别分析
GDA是我们要学习的第一个生成学习算法.GDA的两个假设:
假设输入特征x∈Rn,并且是连续值;
p(x|y)是多维正态分布(multivariate normal distribution);
2.1 多维正态分布
若x服从多维正态分布(也叫多维高斯分布),均值向量(mean vector)
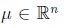
,协方差矩阵(convariance matrix)
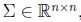
,写成x~
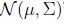
,
其密度函数为:
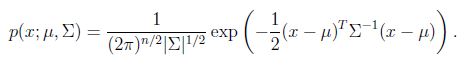
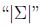
表示行列式(determinant).
均值:
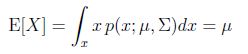
协方差Cov(Z)=
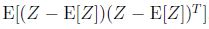
=
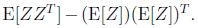
= ∑
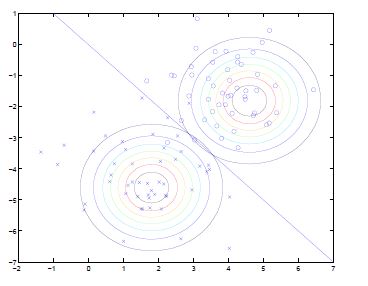
高斯分布的一些例子:
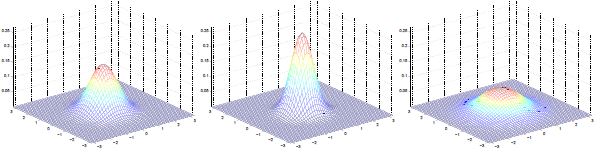
左图均值为零(2*1的零向量),协方差矩阵为单位矩阵I(2*2)(成为标准正态分布).
中图协方差矩阵为0.6I,
右图协方差矩阵为2I
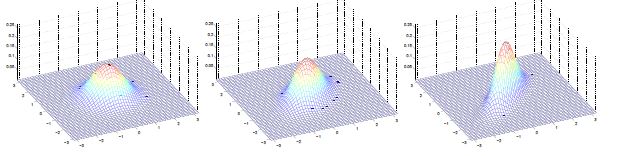
均值为0,方差分别为:
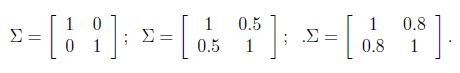
2.2 高斯判别分析模型
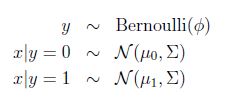
写出概率分布:
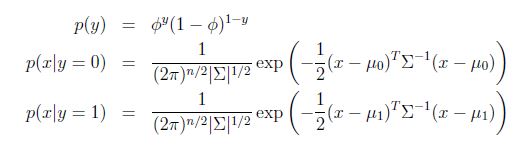
模型的参数为φ,μ0,μ1,∑,对数似然性为:
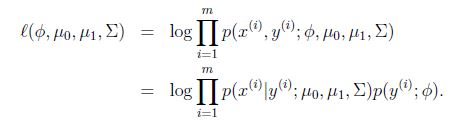
求出最大似然估计为:
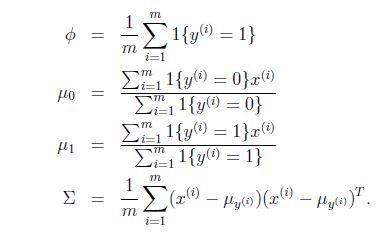
结果如图所示:
1.3 讨论GDA和logistic回归
GDA模型和logistic回归有一个很有意思的关系.
如果把
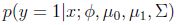
看做是x的函数,则有:
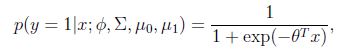
其中
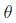
是
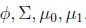
的函数,这正是logistic回归的形式.
关于模型的选择:
刚才说到如果p(x|y)是一个多维的高斯分布,那么p(y|x)必然能推出一个logistic函数;反之则不正确,p(y|x)是一个logistic函数并不能推出p(x|y)服从高斯分布.这说明GDA比logistic回归做了更强的模型假设.
如果p(x|y)真的服从或者趋近于服从高斯分布,则GDA比logistic回归效率高.
当训练样本很大时,严格意义上来说并没有比GDA更好的算法(不管预测的多么精确).
事实证明即使样本数量很小,GDA相对logisic都是一个更好的算法.
但是,logistic回归做了更弱的假设,相对于不正确的模型假设,具有更好的鲁棒性(robust).许多不同的假设能够推出logistic函数的形式. 比如说,如果
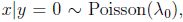
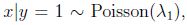
那么p(y|x)是logistic.
logstic回归在这种类型的Poisson数据中性能很好. 但是如果我们使用GDA模型,把高斯分布应用于并不是高斯数据中,结果是不好预测的,GDA就不是很好了.
3.朴素贝叶斯
在GDA模型中,特征向量x是连续的实数向量.如果x是离散值,我们需要另一种学习算法了.例子:垃圾邮件分类问题
首先是把一封邮件作为输入特征,与已有的词典进行比对,如果出现了该词,则把向量的xi=1,否则xi=0,例如:

我们要对p(x|y)建模,但是假设我们的词典有50000个词,那么
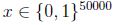
,如果采用多项式建模的方式,会有
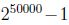
,明显参数太多了,这个方法是行不通的.
为了对p(x|y)建模,我们做一个很强的假设,假设给定y,xi是条件独立(conditionally independent)的.这个假设成为朴素贝叶斯假设(Naive Bayes assumption).
因此有:
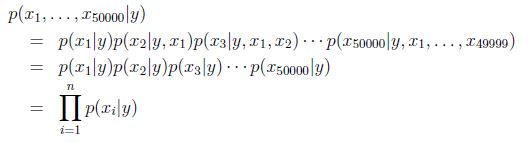
虽然说朴素贝叶斯假设是很强的,但是其实这儿算法在很多问题都工作的很好.
模型参数包括:
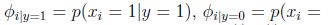
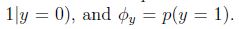
联合似然性(joint likelihood)为:
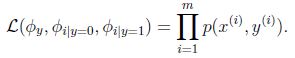
得到最大似然估计值:
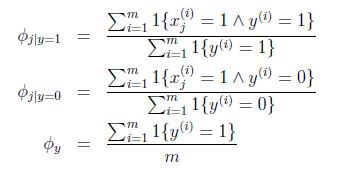
很容易计算:
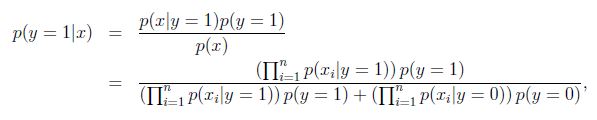
朴素贝叶斯的问题:
假设在一封邮件中出现了一个以前邮件从来没有出现的词,在词典的位置是35000,那么得出的最大似然估计为:
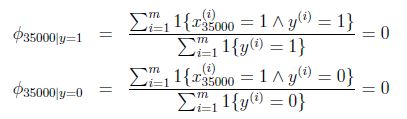
也即使说,在训练样本的垃圾邮件和非垃圾邮件中都没有见过的词,模型认为这个词在任何一封邮件出现的概率为0.
假设说这封邮件是垃圾邮件的概率比较高,那么
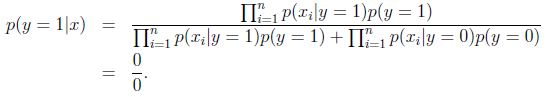
模型失灵.
[b]在统计上来说,在你有限的训练集中没有见过就认为概率是0是不科学的.
4.laplace平滑
为了避免朴素贝叶斯的上述问题,我们用laplace平滑来优化这个问题.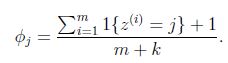
回到朴素贝叶斯问题,通过laplace平滑:
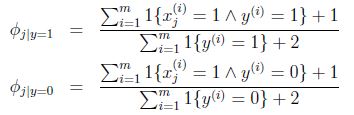
分子加1,分母加1就把分母为零的问题解决了.

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- 反向传播(Backpropagation)算法的数学原理
- 也谈 机器学习到底有没有用 ?
- 如何用70行代码实现深度神经网络算法
- 量子计算机编程原理简介 和 机器学习
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 已经证实提高机器学习模型准确率的八大方法
- 初识机器学习算法有哪些?
- 机器学习相关的库和工具
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 自动编程体系设想(一)
- 自动编程体系设想(一)
- 支持向量机(SVM)算法概述
- [Ng机器学习公开课1]机器学习概述