java解析html之HTMLparser初次尝试
2016-03-23 17:37
513 查看
为了爬取一个网页的数据,尝试了一下Htmlparser来做小爬虫。
下面是一个小案例,用来爬取论坛的帖子内容。
项目主页: http://htmlparser.sourceforge.net/
API文档: http://htmlparser.sourceforge.net/javadoc/index.html
pom.xml
parser并不会处理网页中的异步请求,在抓取页面后会把真个页面解析成DOM树,并以各种形式的节点/TAG存储,然后我们就可以用各种过滤器来帅选自己想要的节点。
htmlparser的已包含节点如下
org.htmlparser
All Superinterfaces: CloneableAll Known Subinterfaces: Remark,Tag,TextAll Known Implementing Classes: AbstractNode,AppletTag,BaseHrefTag,
BodyTag,
Bullet,
BulletList,
CompositeTag,
DefinitionList,
DefinitionListBullet,
Div,
DoctypeTag,
FormTag,
FrameSetTag,
FrameTag,
HeadingTag,
HeadTag,
Html,
ImageTag,
InputTag,
JspTag,
LabelTag,
LinkTag,
MetaTag,
ObjectTag,
OptionTag,
ParagraphTag,
ProcessingInstructionTag,
RemarkNode,
ScriptTag,
SelectTag,
Span,
StyleTag,
TableColumn,
TableHeader,
TableRow,
TableTag,
TagNode,
TextareaTag,
TextNode,
TitleTag
网页被解析后获得的都是这些节点以及他们之间的父子包含关系。
每一个节点都包含如下方法(很多节点还会自己实现更多的方法,例如linktag有些方法用于获取link标签的url,检查这个url的协议类型...)
节点过滤器,这些过滤器可以按照即诶但类型。节点之间父子关系,也可以自定义过滤器。多个过滤器之间可以组合成符合过滤器用于多条件过滤,
比如AndFilter,NotFilter,OrFilter,XorFilter
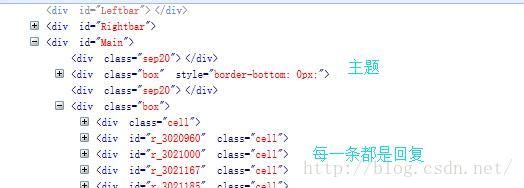
可以看到回复div的id都是r_加六位数字,推荐使用正则表达式匹配,主题的样式是corder-bottom:0px(一定要缺人过滤器的结果,免得引入多余节点)。
创建一个方法,获得主题和回复节点集合
好了有了这些节点接下来就是解析了。
这个例子代码只写了一部分元素的获取,剩下的活也是体力活慢慢分析节点关系,用过滤器或者dom树找目标节点。
下面的代码是将解析到的节点数据封装到bean
好了。解析都做完了,在写个主方法分析一个帖子试试;
看看运行结果:
这个内容过长,截图只能看到帖子名称,和帖子内容了,有兴趣的自己去测试把。请一定要注意地址,貌似这个网站帖子连接会有失效时间,假如测试获取失败请换个帖子地址试试。
附上项目代码:测试使用的是jdk1.6+eclipse kepler
http://pan.baidu.com/s/1mh9OuDi
下面是一个小案例,用来爬取论坛的帖子内容。
1. HtmlParser 简介
htmlparser是一个纯的java写的html解析的库,主要用于改造或提取html。用来分析抓取到的网页信息是个不错的选择,遗憾的是参考文档太少。项目主页: http://htmlparser.sourceforge.net/
API文档: http://htmlparser.sourceforge.net/javadoc/index.html
2. 建立Maven工程
添加相关依赖pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.fancy</groupId> <artifactId>htmlParser</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.htmlparser</groupId> <artifactId>htmlparser</artifactId> <version>2.1</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> </dependencies> </project>
2.1 创建一个解析器
用parser来抓取并分析一个网页。parser并不会处理网页中的异步请求,在抓取页面后会把真个页面解析成DOM树,并以各种形式的节点/TAG存储,然后我们就可以用各种过滤器来帅选自己想要的节点。
htmlparser的已包含节点如下
org.htmlparser
Interface Node
All Superinterfaces: CloneableAll Known Subinterfaces: Remark,Tag,TextAll Known Implementing Classes: AbstractNode,AppletTag,BaseHrefTag,BodyTag,
Bullet,
BulletList,
CompositeTag,
DefinitionList,
DefinitionListBullet,
Div,
DoctypeTag,
FormTag,
FrameSetTag,
FrameTag,
HeadingTag,
HeadTag,
Html,
ImageTag,
InputTag,
JspTag,
LabelTag,
LinkTag,
MetaTag,
ObjectTag,
OptionTag,
ParagraphTag,
ProcessingInstructionTag,
RemarkNode,
ScriptTag,
SelectTag,
Span,
StyleTag,
TableColumn,
TableHeader,
TableRow,
TableTag,
TagNode,
TextareaTag,
TextNode,
TitleTag
网页被解析后获得的都是这些节点以及他们之间的父子包含关系。
每一个节点都包含如下方法(很多节点还会自己实现更多的方法,例如linktag有些方法用于获取link标签的url,检查这个url的协议类型...)
| Method Summary | |
|---|---|
void | accept(NodeVisitor visitor) dc68 Apply the visitor to this node. |
Object | clone() Allow cloning of nodes. |
void | collectInto(NodeList list,NodeFilter filter) Collect this node and its child nodes into a list, provided the node satisfies the filtering criteria. |
void | doSemanticAction() Perform the meaning of this tag. |
NodeList | getChildren() Get the children of this node. |
int | getEndPosition() Gets the ending position of the node. |
Node | getFirstChild() Get the first child of this node. |
Node | getLastChild() Get the last child of this node. |
Node | getNextSibling() Get the next sibling to this node. |
Page | getPage() Get the page this node came from. |
Node | getParent() Get the parent of this node. |
Node | getPreviousSibling() Get the previous sibling to this node. |
int | getStartPosition() Gets the starting position of the node. |
String | getText() Returns the text of the node. |
void | setChildren(NodeList children) Set the children of this node. |
void | setEndPosition(int position) Sets the ending position of the node. |
void | setPage(Page page) Set the page this node came from. |
void | setParent(Node node) Sets the parent of this node. |
void | setStartPosition(int position) Sets the starting position of the node. |
void | setText(String text) Sets the string contents of the node. |
String | toHtml() Return the HTML for this node. |
String | toHtml(boolean verbatim) Return the HTML for this node. |
String | toPlainTextString() A string representation of the node. |
String | toString() Return the string representation of the node. |
节点过滤器,这些过滤器可以按照即诶但类型。节点之间父子关系,也可以自定义过滤器。多个过滤器之间可以组合成符合过滤器用于多条件过滤,
比如AndFilter,NotFilter,OrFilter,XorFilter
| Class Summary | |
|---|---|
| AndFilter | Accepts nodes matching all of its predicate filters (AND operation). |
| CssSelectorNodeFilter | A NodeFilter that accepts nodes based on whether they match a CSS2 selector. |
| HasAttributeFilter | This class accepts all tags that have a certain attribute, and optionally, with a certain value. |
| HasChildFilter | This class accepts all tags that have a child acceptable to the filter. |
| HasParentFilter | This class accepts all tags that have a parent acceptable to another filter. |
| HasSiblingFilter | This class accepts all tags that have a sibling acceptable to another filter. |
| IsEqualFilter | This class accepts only one specific node. |
| LinkRegexFilter | This class accepts tags of class LinkTag that contain a link matching a given regex pattern. |
| LinkStringFilter | This class accepts tags of class LinkTag that contain a link matching a given pattern string. |
| NodeClassFilter | This class accepts all tags of a given class. |
| NotFilter | Accepts all nodes not acceptable to it's predicate filter. |
| OrFilter | Accepts nodes matching any of its predicates filters (OR operation). |
| RegexFilter | This filter accepts all string nodes matching a regular expression. |
| StringFilter | This class accepts all string nodes containing the given string. |
| TagNameFilter | This class accepts all tags matching the tag name. |
抓取http://www.v2ex.com网站中的一篇帖子
首先要创建获取网页内容,分析网页元素结构制作过滤器;可以看到回复div的id都是r_加六位数字,推荐使用正则表达式匹配,主题的样式是corder-bottom:0px(一定要缺人过滤器的结果,免得引入多余节点)。
创建一个方法,获得主题和回复节点集合
/**
*
* 获取html中的主题和所有回复节点
*
* @param url
* @param ENCODE
* @return
*/
protected NodeList getNodelist(String url, String ENCODE) {
try {
NodeList nodeList = null;
Parser parser = new Parser(url);
parser.setEncoding(ENCODE);
//定义一个Filter,过滤主题div
NodeFilter filter = new NodeFilter() {
@Override
public boolean accept(Node node) {
if(node.getText().contains("style=\"border-bottom: 0px;\"")) {
return true;
} else {
return false;
}
}
};
//定义一个Filter,过滤所有回复div
NodeFilter replyfilter = new NodeFilter() {
@Override
public boolean accept(Node node) {
String containsString = "id=\"r_";
if(node.getText().contains(containsString)) {
return true;
} else {
return false;
}
}
};
//组合filter
OrFilter allFilter = new OrFilter(filter, replyfilter);
nodeList = parser.extractAllNodesThatMatch(allFilter);
return nodeList;
} catch (ParserException e) {
e.printStackTrace();
return null;
}
}好了有了这些节点接下来就是解析了。
这个例子代码只写了一部分元素的获取,剩下的活也是体力活慢慢分析节点关系,用过滤器或者dom树找目标节点。
下面的代码是将解析到的节点数据封装到bean
public Forum parse2Thread(String url,String ENCODE) {
List<Reply> replylist = new ArrayList<Reply>(); //回复列表
Topic topic = new Topic(); //主题
NodeFilter divFilter = new NodeClassFilter(Div.class);//div过滤器
NodeFilter headingFilter = new NodeClassFilter(HeadingTag.class);//heading过滤器
NodeFilter tagFilter = new NodeClassFilter(TagNode.class);//heading过滤器
NodeList nodeList = this.getNodelist(url, ENCODE);
//解析node到帖子实体
for (int i = 0; i < nodeList.size(); i++) {
Node node = nodeList.elementAt(i);
if(node.getText().contains("style=\"border-bottom: 0px;\"")) {
//如果node是主题
NodeList list = node.getChildren();//node的子节点
//header div
Node headerNode = list.extractAllNodesThatMatch(new NodeClassFilter(Div.class)).elementAt(0);
//帖子主题
Node h1Node = headerNode.getChildren().extractAllNodesThatMatch(headingFilter).elementAt(0);
topic.setTopicName(h1Node.toPlainTextString());
//发帖人信息
NodeList headerChrildrens = headerNode.getChildren();
topic.setAnn_name(headerChrildrens.elementAt(15).toPlainTextString());
topic.setTopicDescribe(headerChrildrens.elementAt(16).toPlainTextString());
//发帖人头像链接
Node frNode = headerChrildrens.extractAllNodesThatMatch(divFilter).elementAt(0);
ImageTag imgNode = (ImageTag) frNode.getFirstChild().getFirstChild();
topic.setAnn_img(imgNode.getImageURL());
//cell div
Node cellNode = list.extractAllNodesThatMatch(divFilter).elementAt(1);
Node topic_content = cellNode.getChildren().extractAllNodesThatMatch(divFilter).elementAt(0);
Node markdown_body = topic_content.getChildren().extractAllNodesThatMatch(divFilter).elementAt(0);
topic.setTopicBody(markdown_body.toPlainTextString());//暂时不包含连接和图片纯文本
} else if(node.getText().contains("id=\"r_")){
//节点是回复
Reply reply = new Reply();
Node tableNode = node.getChildren().extractAllNodesThatMatch(tagFilter).elementAt(0);
Node trNode = tableNode.getChildren().extractAllNodesThatMatch(tagFilter).elementAt(0);
//回复的tagNodeList
NodeList tagList = trNode.getChildren().extractAllNodesThatMatch(tagFilter);
ImageTag reply_img = (ImageTag) tagList.elementAt(0).getChildren().extractAllNodesThatMatch(tagFilter).elementAt(0);
reply.setReply_img(reply_img.getImageURL());
//nodeList bodyNode = tagList;
replylist.add(reply);
}
}
System.out.println("-----------实体----------------");
Forum forum = new Forum(topic, replylist);
System.out.println(forum.toString());
return null;
}好了。解析都做完了,在写个主方法分析一个帖子试试;
@Test
public void test() throws Exception {
Html2Domain parse = new Html2DomainImpl();
parse.parse2Thread("http://www.v2ex.com/t/262409#reply6","UTF-8");
}看看运行结果:
这个内容过长,截图只能看到帖子名称,和帖子内容了,有兴趣的自己去测试把。请一定要注意地址,貌似这个网站帖子连接会有失效时间,假如测试获取失败请换个帖子地址试试。
附上项目代码:测试使用的是jdk1.6+eclipse kepler
http://pan.baidu.com/s/1mh9OuDi

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- Python3写爬虫(四)多线程实现数据爬取
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- Scrapy的架构介绍
- PropertyChangeListener简单理解
- 爬虫笔记
- maven学习
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器