java安全(七)终极装备——HTTPS协议之HTTP协议
2016-03-22 09:33
686 查看
什么是HTTP协议
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1。HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。
HTTP应用
当我们打开浏览器,在地址栏中输入URL,然后我们就看到了网页。 原理是怎样的呢?
实际上我们输入URL后,我们的浏览器给Web服务器发送了一个Request, Web服务器接到Request后进行处理,生成相应的Response,然后发送给浏览器, 浏览器解析Response中的HTML,这样我们就看到了网页,过程如下图所示

URL详解
URL(Uniform Resource Locator) 地址用于描述一个网络上的资源, 基本格式如下
schema://host[:port#]/path/…/[?query-string][#anchor]
scheme 指定低层使用的协议(例如:http, https, ftp)
host HTTP服务器的IP地址或者域名
port# HTTP服务器的默认端口是80,这种情况下端口号可以省略.如果使用了别的端口,必须指明,
例如 http://blog.csdn.net/not_lost_yesterday
path 访问资源的路径
query-string 发送给http服务器的数据
anchor- 锚
Schema: http
host: www.mywebsite.com
path: /sj/test/test.aspx
Anchor: stuff
HTTP消息的结构
1.Request 消息的结构, Request 消息分为3部分,第一部分叫Request line, 第二部分叫Request header, 第三部分是body. header和body之间有个空行, 结构如下图

Request line(请求行): 请求方式 资源路径 HTTP版本号
举例:GET /test.html HTTP/1.1
请求方式有如下几种:POST 、GET、 HEAD 、OPTIONS、 DELETE、 PUT、 TRACE
请求头:是是由多个key-value键值对组成
请求体:是客户端发给服务器的内容
下面使用telnet做的一个向服务器发送Post请求来说明request:

firefox截图:

2.Response消息结构,HTTP响应也是由三个部分组成,分别是:状态行、消息报头、响应正文。
状态行:HTTP版本号 状态码 原因叙述 举例: HTTP/1.1 200 OK
状态码一般记住200 成功 301/302 重定向 304 未修改 404 未找到 500系统内部错误 就差不多了。
响应头也是是由多个key-value键值对组成。
响应体:服务器响应给客户端的内容,一般都是HTML页面,image图片等等.
下面还是以telnet发送的request请求为例说明response响应。
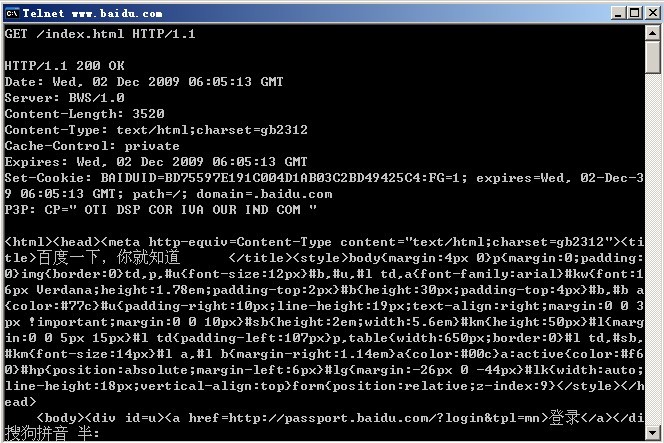
这是浏览器的一个简单的get请求和服务器的response应答。

到这里其实HTTP协议已经讲完了,你知道了HTTP请求包括 请求行 请求头 请求体,HTTP响应包括响应行 响应头 响应体。下面主要简单讲解下部分HTTP的请求头和响应头。
HTTP响应头
接下来从HTTP响应头入手讲解下HTTP一些高大上的功能(具体细节这里不再讲解)。
1. cookie与登录: 大家都有这样的经历 在某论坛发帖子 他就是一个普通的post请求。但是发帖之前他要求你必须要登陆。登录后随便发帖子就没人在让你登陆了。然而众所周知,HTTP是无状态的,登录后就断开连接了,在来操作服务器应该不认识你了才对呀,应该重新登陆的呀。这是因为浏览器帮你把登陆的表示存起到cookie里面了,下次操作http请求会把cookie一起发过去的,服务器会验证cookie的值来判断你是否已经登陆。
未登录浏览器随便生成的cookie

已登录的cookie

2. referer 头与防盗链(可以在服务器端配置的 比如apache服务器就有一个配置模块,在写个.htaccess文件 里面写点正则什么的就可以达到图片防盗问题):
防盗链就是你的网站里面直接引用别人网站的图片,人家不让你使用你引用的图片。比如:

原理 请求头里面有一个referer 它是告诉服务器你访问的上一个是什么,服务器会根据这个参数判断是否满足要求,满足就返回你要请求的页面 不满足就返回错误页面了。这样做有人会说太抠了, 其实主要是用来优化服务器的,减少外界的请求的。
3. HTTP缓存 cache(也是在服务器端配置的 不多说了 apache还是.htaccess文件)
4. HTTP压缩 content-encoding(也是服务器端配置的):服务器传输的文件正常都是未经压缩的文件.一般新闻网站 浏览量很大 网页也很大 经过压缩传输可以节省40%左右的流量。常见的压缩算法有gzip, deflate ,sdch等
客户端 请求头 Accept-Encoding 告诉浏览器所支持的压缩算法,
服务器根据配置和Accept-Encoding 选择浏览器支持的压缩算法压缩文件传输content-encoding:返回使用的压缩算法。
5. 其他的一些请求头:Expires 过期时间
Etag文件的签名 Last-Modified 最后修改时间 If-None-Match 如果未匹配到If-Modified-Since 自从多少时间未修改过。你经常会看到304 not modified 读取浏览器缓存 就是他们的功劳。

还有很多有意思的请求头就不一一说明了。
对了 还有一个Content-type:chuncked ; 这块技术我也没太搞懂它涉及到 comet反向ajax一个很厉害的东西,我也没有太深研究。可以实现类似即时聊天功能。有大牛可以给我推荐下好的学习资料。
最后推荐一个好的HTTP学习视频地址(他的HTTP协议讲的真的很不错 入门必备):http://www.zixue.it/portal.php?mod=list&catid=9
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1。HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。
HTTP应用
当我们打开浏览器,在地址栏中输入URL,然后我们就看到了网页。 原理是怎样的呢?
实际上我们输入URL后,我们的浏览器给Web服务器发送了一个Request, Web服务器接到Request后进行处理,生成相应的Response,然后发送给浏览器, 浏览器解析Response中的HTML,这样我们就看到了网页,过程如下图所示
URL详解
URL(Uniform Resource Locator) 地址用于描述一个网络上的资源, 基本格式如下
schema://host[:port#]/path/…/[?query-string][#anchor]
scheme 指定低层使用的协议(例如:http, https, ftp)
host HTTP服务器的IP地址或者域名
port# HTTP服务器的默认端口是80,这种情况下端口号可以省略.如果使用了别的端口,必须指明,
例如 http://blog.csdn.net/not_lost_yesterday
path 访问资源的路径
query-string 发送给http服务器的数据
anchor- 锚
Schema: http
host: www.mywebsite.com
path: /sj/test/test.aspx
Anchor: stuff
HTTP消息的结构
1.Request 消息的结构, Request 消息分为3部分,第一部分叫Request line, 第二部分叫Request header, 第三部分是body. header和body之间有个空行, 结构如下图
Request line(请求行): 请求方式 资源路径 HTTP版本号
举例:GET /test.html HTTP/1.1
请求方式有如下几种:POST 、GET、 HEAD 、OPTIONS、 DELETE、 PUT、 TRACE
请求头:是是由多个key-value键值对组成
请求体:是客户端发给服务器的内容
下面使用telnet做的一个向服务器发送Post请求来说明request:
firefox截图:
2.Response消息结构,HTTP响应也是由三个部分组成,分别是:状态行、消息报头、响应正文。
状态行:HTTP版本号 状态码 原因叙述 举例: HTTP/1.1 200 OK
状态码一般记住200 成功 301/302 重定向 304 未修改 404 未找到 500系统内部错误 就差不多了。
响应头也是是由多个key-value键值对组成。
响应体:服务器响应给客户端的内容,一般都是HTML页面,image图片等等.
下面还是以telnet发送的request请求为例说明response响应。
这是浏览器的一个简单的get请求和服务器的response应答。
到这里其实HTTP协议已经讲完了,你知道了HTTP请求包括 请求行 请求头 请求体,HTTP响应包括响应行 响应头 响应体。下面主要简单讲解下部分HTTP的请求头和响应头。
HTTP响应头
接下来从HTTP响应头入手讲解下HTTP一些高大上的功能(具体细节这里不再讲解)。
1. cookie与登录: 大家都有这样的经历 在某论坛发帖子 他就是一个普通的post请求。但是发帖之前他要求你必须要登陆。登录后随便发帖子就没人在让你登陆了。然而众所周知,HTTP是无状态的,登录后就断开连接了,在来操作服务器应该不认识你了才对呀,应该重新登陆的呀。这是因为浏览器帮你把登陆的表示存起到cookie里面了,下次操作http请求会把cookie一起发过去的,服务器会验证cookie的值来判断你是否已经登陆。
未登录浏览器随便生成的cookie
已登录的cookie
2. referer 头与防盗链(可以在服务器端配置的 比如apache服务器就有一个配置模块,在写个.htaccess文件 里面写点正则什么的就可以达到图片防盗问题):
防盗链就是你的网站里面直接引用别人网站的图片,人家不让你使用你引用的图片。比如:
原理 请求头里面有一个referer 它是告诉服务器你访问的上一个是什么,服务器会根据这个参数判断是否满足要求,满足就返回你要请求的页面 不满足就返回错误页面了。这样做有人会说太抠了, 其实主要是用来优化服务器的,减少外界的请求的。
3. HTTP缓存 cache(也是在服务器端配置的 不多说了 apache还是.htaccess文件)
4. HTTP压缩 content-encoding(也是服务器端配置的):服务器传输的文件正常都是未经压缩的文件.一般新闻网站 浏览量很大 网页也很大 经过压缩传输可以节省40%左右的流量。常见的压缩算法有gzip, deflate ,sdch等
客户端 请求头 Accept-Encoding 告诉浏览器所支持的压缩算法,
服务器根据配置和Accept-Encoding 选择浏览器支持的压缩算法压缩文件传输content-encoding:返回使用的压缩算法。
5. 其他的一些请求头:Expires 过期时间
Etag文件的签名 Last-Modified 最后修改时间 If-None-Match 如果未匹配到If-Modified-Since 自从多少时间未修改过。你经常会看到304 not modified 读取浏览器缓存 就是他们的功劳。
还有很多有意思的请求头就不一一说明了。
对了 还有一个Content-type:chuncked ; 这块技术我也没太搞懂它涉及到 comet反向ajax一个很厉害的东西,我也没有太深研究。可以实现类似即时聊天功能。有大牛可以给我推荐下好的学习资料。
最后推荐一个好的HTTP学习视频地址(他的HTTP协议讲的真的很不错 入门必备):http://www.zixue.it/portal.php?mod=list&catid=9

相关文章推荐
- HTTP_USER_AGENT
- Android23版本应用使用HttpClient
- Volley加载网络图片
- tcp/ip ---数据链路层
- 获取用户Ip地址通用方法常见安全隐患(HTTP_X_FORWARDED_FOR)
- 多达 95% 的 HTTPS 链接能被黑客劫持
- Android OkHttp完全解析 是时候来了解OkHttp了
- Android Https相关完全解析 当OkHttp遇到Https
- iOS_GET_网络请求
- 网络流建模总结
- Nginx TCP监控和自动限流
- XMLHTTPRequest状态status完整列表
- TCP传输控制协议总结
- Web页面的请求历程
- Swift 网络请求, 图片加载, tableView, collectionView, webView(八)
- 高效利用Angular中内置服务$http、$location等
- JAVA TCP 长连接通信
- TCP/IP HTTP Socket的关系
- vmware下虚拟机实现外部网络访问方式
- http协议Connection:Keep-alive 是怎么用,一次连接可以处理多个请求?