Java内存区域与内存溢出异常(二)
2016-03-21 13:01
459 查看
了解Java虚拟机的运行时数据区之后,大致知道了虚拟机内存的概况,内存中都放了些什么,接下来将了解内存中数据的其他细节,如何创建、如何布局、如何访问。这里虚拟机以HotSpot为例,内存区域以Java堆为例,深入探讨HotSpot虚拟机在Java堆中对象分配、布局和访问的全过程。
(一)对象的创建
语言层面上,创建对象(例如克隆、反序列化)通常只是一个new关键字而已,而在虚拟机中,对象(文中讨论的对象限于普通Java对象,不包括数组和Class对象等)的创建是怎样的过程呢。
虚拟机遇到一条new指令时,首先检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
在类加载检查通过后,虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定,为对象分配空间的任务等同于把一块确定大小的内存从Java堆中划分出来。假设Java堆中内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就是指针向空闲空间那边挪动一段与对象大小相等的距离,这种分配方式称为“指针碰撞”。
如果堆中的内存并不是规整的,已使用的内存和空闲的内存相互交错,就必须维护一个列表,记录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录,这种分配方式称为“空闲列表”。
选择哪种方式由Java堆是否规整决定,而堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。因此,在使用Serial、ParNew等带有Compact过程的收集器时,系统采用的分配算法是指针碰撞,而使用CMS这种基于Mark-Sweep算法的收集器时,通常采用空闲列表。
除如何划分可用空间外,还要考虑线程安全。对象创建在虚拟机中是非常频繁的行为,即使是修改一个指针所指向的位置,在并发情况下也不是线程安全的,可能出现正在给对象A分配内存,指针还没来得及修改,对象B又同时使用了原来的指针来分配内存的情况。
解决这个问题有两种方案,一种是对分配内存空间的动作进行同步处理——实际上虚拟机采用CAS配上失败重试的方式保证更新操作的原子性;另一种是把内存分配的动作按照线程划分在不同空间之中进行,即每个线程在Java堆中预先分配一小块内存,称为本地线程分配缓冲(Thread Local Allocation Buffer,TLAB)。哪个线程要分配内存,就在哪个线程的TLAB上分配,只有TLAB用完并分配新的TLAB时,才需要同步锁定。虚拟机是否使用TLAB,通过-XX:+/-UserTLAB参数来设定。
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),如果使用TLAB,这一工作过程也可以提前至TLAB分配时进行。该操作保证对象的实例字段在Java代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型对应的零值。
接下来,虚拟机要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的GC分带年龄等信息。这些信息放在对象的对象头(Object Header)之中。根据虚拟机当前的运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
上面工作完成后,从虚拟机的角度来看,一个新的对象已经产生了,但从Java程序的角度来看,对象创建才刚刚开始—<init>方法还没有执行,所有字段都还为0。一般来说(由字节码中是否跟随invokespecial指令决定),执行new指令之后接着执行<init>方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
(补充:JVM本身是硬件的一层软件抽象,在这之上才能够运行Java程序,也才有了我们吹嘘的平台独立性和WORA。JVM是个标准,具体上的VM有几十种实现,这节就以HotSpot的实现来介绍的,而主流VM包括Hotspot、Jikes RVM等的实现,都是基于C/C++和汇编,每个runtime编译的时候针对每个平台编译,因此下载JRE的时候是分平台的,VM的作用是把平台无关的.class里面的bytecode翻译成平台相关的machine code,来实现跨平台)
(二)对象的内存布局
在HotSpot虚拟机中,对象在内存中存储的布局分为3个区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
对象头包括两部分信息:
对象头第一部分用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位虚拟机(未开启压缩指针)中分别为32bit和64bit,官方称为“Mark Word”。对象需要存储的运行时数据很多,其实已经超出32位、64位所能记录的限度,考虑到虚拟机的空间效率,Mark Word设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。例如,在32位的HotSpot虚拟机中,如果对象处于未被锁定状态,那么Mark Word的32bit空间中的25bit用于存储对象哈希码,4bit用于存储对象分代年龄,2bit用于存储锁标志位,1bit固定为0,而在其他状态(轻量级锁定、重量级锁定、GC标记、可偏向)下对象的存储内容如下
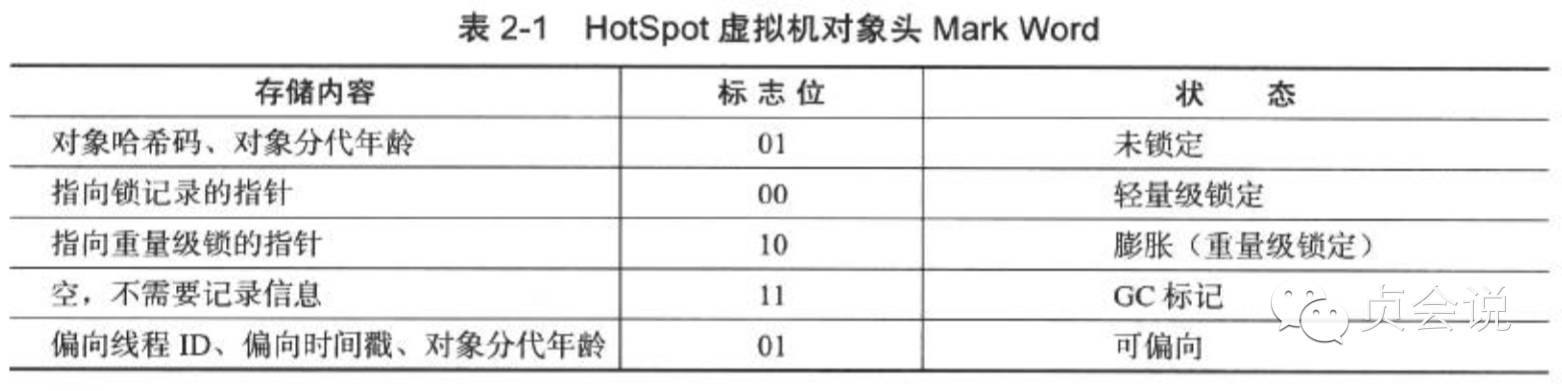
对象头另一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。如果对象是一个JAVA数组,对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中是无法确定数组大小的。
接下来的实例数据部分是对象真正存储的有效信息,也是程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。存储顺序会受到虚拟机分配策略参数和字段在Java源码中定义顺序的影响。HotSpot虚拟机默认的分配策略为longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Points),可见相同宽度的字段总是被分配到一起。在满足这个前提条件的情况下,在父类中定义的变量会出现在子类之前。如果CompactFields参数为true,子类中较窄的变量也可能会插入到父类变量的空隙之中。
第三部分对齐填充并不是必然存在的,仅仅起着占位符的作用。由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,即对象的大小必须是8字节的整数倍。而对象头部分正好是8字节的倍数(1倍或者2倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
(三)对象的访问定位
Java程序需要通过栈上的reference数据来操作堆上的具体对象。而reference类型在Java虚拟机规范中只规定了一个指向对象的引用,并没有定义这个应用通过何种方式去定位、访问堆中的对象的具体位置,所以取决于虚拟机实现而定,目前主流访问方式有使用句柄和直接指针两种。
使用句柄访问的话,Java堆中会划分出一块内存来作为句柄池,reference中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息。
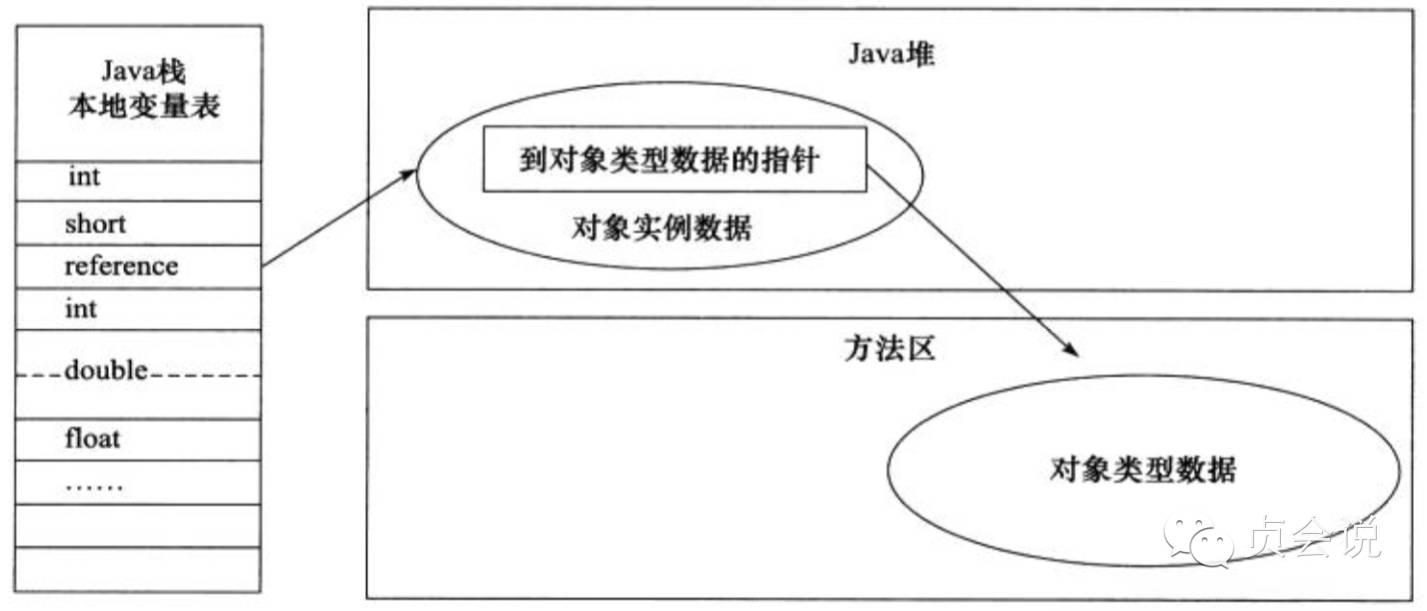
如果使用直接指针访问,那么reference中存储的直接就是对象地址,Java堆对象的布局中就得考虑如何放置访问类型数据的相关信息。
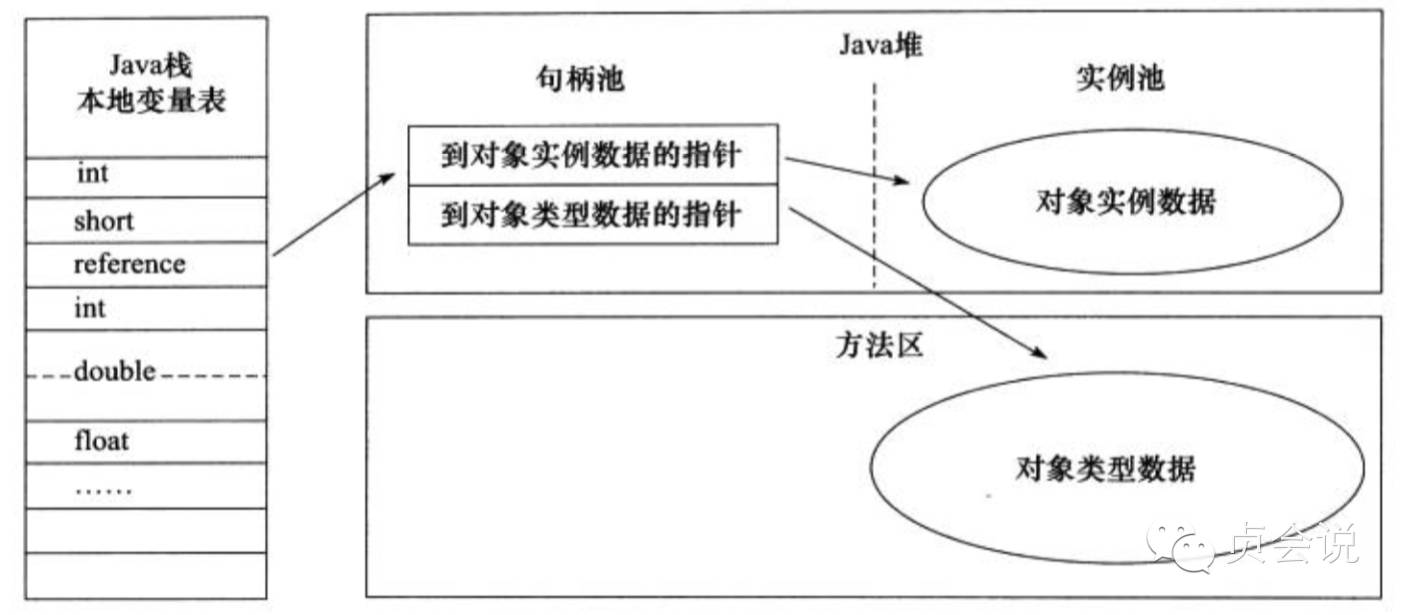
两种方式各有优势,使用句柄最大好处是reference中存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而reference本身不需要修改。
使用直接指针访问方式好处是快,节省了一次指针定位的时间开销,由于对象的访问在Java中是非常频繁的,因此这类开销积少成多也是很可观的执行成本。就本书讨论的HotSpot虚拟机而言,它是使用直接指针访问的。
(一)对象的创建
语言层面上,创建对象(例如克隆、反序列化)通常只是一个new关键字而已,而在虚拟机中,对象(文中讨论的对象限于普通Java对象,不包括数组和Class对象等)的创建是怎样的过程呢。
虚拟机遇到一条new指令时,首先检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
在类加载检查通过后,虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定,为对象分配空间的任务等同于把一块确定大小的内存从Java堆中划分出来。假设Java堆中内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就是指针向空闲空间那边挪动一段与对象大小相等的距离,这种分配方式称为“指针碰撞”。
如果堆中的内存并不是规整的,已使用的内存和空闲的内存相互交错,就必须维护一个列表,记录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录,这种分配方式称为“空闲列表”。
选择哪种方式由Java堆是否规整决定,而堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。因此,在使用Serial、ParNew等带有Compact过程的收集器时,系统采用的分配算法是指针碰撞,而使用CMS这种基于Mark-Sweep算法的收集器时,通常采用空闲列表。
除如何划分可用空间外,还要考虑线程安全。对象创建在虚拟机中是非常频繁的行为,即使是修改一个指针所指向的位置,在并发情况下也不是线程安全的,可能出现正在给对象A分配内存,指针还没来得及修改,对象B又同时使用了原来的指针来分配内存的情况。
解决这个问题有两种方案,一种是对分配内存空间的动作进行同步处理——实际上虚拟机采用CAS配上失败重试的方式保证更新操作的原子性;另一种是把内存分配的动作按照线程划分在不同空间之中进行,即每个线程在Java堆中预先分配一小块内存,称为本地线程分配缓冲(Thread Local Allocation Buffer,TLAB)。哪个线程要分配内存,就在哪个线程的TLAB上分配,只有TLAB用完并分配新的TLAB时,才需要同步锁定。虚拟机是否使用TLAB,通过-XX:+/-UserTLAB参数来设定。
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),如果使用TLAB,这一工作过程也可以提前至TLAB分配时进行。该操作保证对象的实例字段在Java代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型对应的零值。
接下来,虚拟机要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的GC分带年龄等信息。这些信息放在对象的对象头(Object Header)之中。根据虚拟机当前的运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
上面工作完成后,从虚拟机的角度来看,一个新的对象已经产生了,但从Java程序的角度来看,对象创建才刚刚开始—<init>方法还没有执行,所有字段都还为0。一般来说(由字节码中是否跟随invokespecial指令决定),执行new指令之后接着执行<init>方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
(补充:JVM本身是硬件的一层软件抽象,在这之上才能够运行Java程序,也才有了我们吹嘘的平台独立性和WORA。JVM是个标准,具体上的VM有几十种实现,这节就以HotSpot的实现来介绍的,而主流VM包括Hotspot、Jikes RVM等的实现,都是基于C/C++和汇编,每个runtime编译的时候针对每个平台编译,因此下载JRE的时候是分平台的,VM的作用是把平台无关的.class里面的bytecode翻译成平台相关的machine code,来实现跨平台)
(二)对象的内存布局
在HotSpot虚拟机中,对象在内存中存储的布局分为3个区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
对象头包括两部分信息:
对象头第一部分用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位虚拟机(未开启压缩指针)中分别为32bit和64bit,官方称为“Mark Word”。对象需要存储的运行时数据很多,其实已经超出32位、64位所能记录的限度,考虑到虚拟机的空间效率,Mark Word设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。例如,在32位的HotSpot虚拟机中,如果对象处于未被锁定状态,那么Mark Word的32bit空间中的25bit用于存储对象哈希码,4bit用于存储对象分代年龄,2bit用于存储锁标志位,1bit固定为0,而在其他状态(轻量级锁定、重量级锁定、GC标记、可偏向)下对象的存储内容如下
对象头另一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。如果对象是一个JAVA数组,对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中是无法确定数组大小的。
接下来的实例数据部分是对象真正存储的有效信息,也是程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。存储顺序会受到虚拟机分配策略参数和字段在Java源码中定义顺序的影响。HotSpot虚拟机默认的分配策略为longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Points),可见相同宽度的字段总是被分配到一起。在满足这个前提条件的情况下,在父类中定义的变量会出现在子类之前。如果CompactFields参数为true,子类中较窄的变量也可能会插入到父类变量的空隙之中。
第三部分对齐填充并不是必然存在的,仅仅起着占位符的作用。由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,即对象的大小必须是8字节的整数倍。而对象头部分正好是8字节的倍数(1倍或者2倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
(三)对象的访问定位
Java程序需要通过栈上的reference数据来操作堆上的具体对象。而reference类型在Java虚拟机规范中只规定了一个指向对象的引用,并没有定义这个应用通过何种方式去定位、访问堆中的对象的具体位置,所以取决于虚拟机实现而定,目前主流访问方式有使用句柄和直接指针两种。
使用句柄访问的话,Java堆中会划分出一块内存来作为句柄池,reference中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息。
如果使用直接指针访问,那么reference中存储的直接就是对象地址,Java堆对象的布局中就得考虑如何放置访问类型数据的相关信息。
两种方式各有优势,使用句柄最大好处是reference中存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而reference本身不需要修改。
使用直接指针访问方式好处是快,节省了一次指针定位的时间开销,由于对象的访问在Java中是非常频繁的,因此这类开销积少成多也是很可观的执行成本。就本书讨论的HotSpot虚拟机而言,它是使用直接指针访问的。

相关文章推荐
- 深入理解java垃圾回收机制
- 找到假币
- java比较器Comparable接口和Comaprator接口
- IT忍者神龟之Eclipse常用开发插件
- 关于Java中的继承和组合的一个错误使用的例子
- java写入文件
- java文件
- Spring通过@Value注解注入属性的几种方式
- Java的n++问题
- Java技术_Java千百问(0009)_java开发应该使用什么工具
- Spring Boot 定时任务的使用
- Maven 发布项目到Jetty服务器
- Maven 发布项目到Jetty服务器
- Java try . catch 的使用
- jvm:停止复制、标记清除、标记整理算法(垃圾回收)
- Java学习第一步——JDK安装及Java环境变量配置
- java static关键字用法详解
- myeclipse 2015 stable 2.0连接mysql URL错误
- 栈在java中的实现
- Java并发编程(三)——synchronized