数据结构与算法学习(四)
2016-03-19 00:00
423 查看
摘要: 通过《数据结构与算法分析-C++描述》(第三版),学习数据结构与算法
看到实现散列表的几种方法。
分析比较这些方法。
介绍散列的多种应用。
将散列表和二叉树查找进行比较。
将每个键映射到从0到TableSize-1这个范围中的某个数,并且将其放到适当的单元中。这个映射叫做散列函数(hash function),理想情况下它应该运算简单并且应该保证任何两个不同的键映射到不同单元。
这是散列的基本思想。接下来的问题则是要选择一个函数,决定当两个键散列到同一个值的时候(称为冲突(collsion))应该做什么以及如何确定散列表的大小。
通常键是字符串:在这种情况下,散列函数需要仔细选择。一种方法是把字符串中字符的ASCII码值加起来。代码实现如下:
上面给出的散列函数简单而且能很快地算出结果。一般情况下然而当表很大,则函数就不会很好地分配键。
下面是另一个散列函数。这个函数假设Key值至少有3个字符。值27表示英文字母表的字母个数外加一个空格。但还是不太好:
下面列出了散列函数的第三种尝试。这个散列函数涉及键中的所有字符,并且一般可以分布得很好。程序根据Horner法则计算一个(37的)多项式函数。用计算散列函数省下来的时间来补偿由此产生的对均匀分布的函数的轻微干扰。
剩下的主要编程细节就是解决冲突。解决方法有几种,下面讨论最简单的两种:分离链接法和开放定址法。
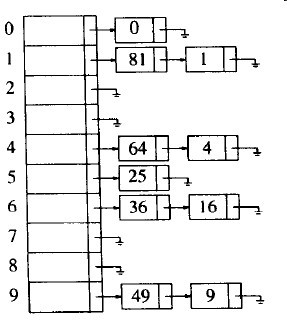
图4-1 分离链接散列表
为了执行search,我们使用散列函数来确定究竟遍历哪个链表,然后查找相应的表。为执行insert,我们检查相应的表来确定是否该元素已经在表中了(如果要插入重复元,那么通常要流出一个额外的数据成员,当出现匹配事件时这个数据成员增1)。如果这个元素是个新的元素,那么它将被插入到表的前端,这不仅因为方便,而且还因为最后插入的元素有可能不久再次被访问。
实现分离链接法所需的类架构在下面给出。散列表结构存储一个链表数组,这个数组在构造函数中指定。
本章中的散列表只适合提供散列函数和相等性操作(operator==或operator!=或两者都提供)。这将自动包括int和string。因为在HashTable类中这些散列函数是作为全局的非类函数出现的。下面是散列表类有一个私有的成员函数myhash,这个函数将结果分配到一个合适的数组索引中。
下面列出了一个可以存储Employee类,该类使用name成员作为键。Employee类通过提供相等性操作符和一个散列函数来实现HashObj的需求。
下面是分离链接散列表的makeEmpty、contains和remove的程序实现。
下面是插入方法。如果要插入的项已经存在,那么什么都不做;否则将其放至表的前端。该元素可以放在表的任何地方:此处使用push_back是最方便的。whichList是一个引用变量。
除链表外,任何的方案也都有可能用来解决冲突现象:一棵查找树,甚至另外一个散列表均可胜任,但我们期望的是如果散列表大而且散列函数好,那么所有的链表都应该短,因此,不值得去进行任何复杂的尝试。
我们定义散列表的填装因子(load factor)λ为散列表中的元素个数与散列表大小的比值。表的平均长度为λ,执行一次查找所需的工作是计算散列函数值所需要的常数时间加上遍历表所需时间。在一次不成功的查找中,要考察的节点数平均为λ。成功的查找则需要遍历大约1+(λ/2)个链。散列表的大小并不重要,填装因子才是重要的。分离链接散列法的一般法则是使得表的大小尽量与预料的元素个数差不多(即,λ≈1)。

图4-2 每次插入后使用线性探测得到的散列表
只要表足够大,总能够找到一个自由单元,但是如此花费的时间是相当多的。更糟的是,即使表相对较空,这样占据的单元也会开始形成一些区域,其结果称为一次聚集(primary clustering),于是,散列到区域块中的任何键都需要多次试选单元才能解决冲突,然后该键才能添加到相应的区域中。
图4-3把线性探测的性能(虚曲线)与其他更随机的冲突解决方案的期望性能做了比较。成功的查找用S标出,不成功查找和插入分别用U和I标记。
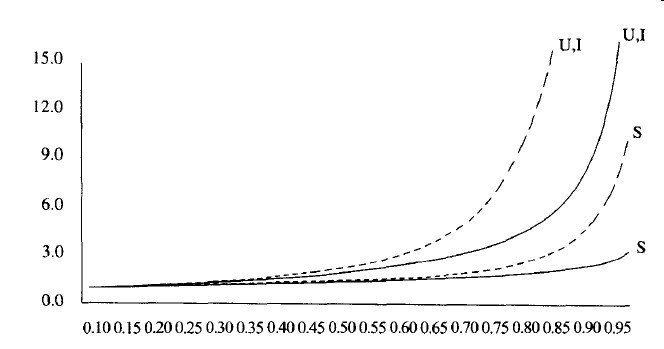
图4-3 对线性探测(虚线)和随机方法的填装因子画出的探测次数(S为成功查找,U为不成功查找,而I为插入时间)

图4-4 在每次插入后,利用平方探测得到的散列表
平方探测情况更糟:一旦表被填满超过一半,若表的大小不是素数,那么甚至在表被填满一半之前,就不能保证找到空的单元了。因为最多只有表的一半可以用做解决冲突的备选位置。
下面证明如果表一半为空,并且表的大小为素数,那么可以保证总能够插入一个新的元素。
定理4-1 如果使用平方探测,且表的大小是素数,那么当表至少有一半是空的时候,总能够插入一个新的元素。
我们用散列表项单元数组。嵌套的类HashEntry存储在info成员中的一个项的状态,这个状态可以是ACTIVE、ENPTY或DELETED。我们可以用static const数据或者枚举类型,下面是枚举类型:
下面是使用探测策略的散列表的类接口,包括嵌套的HashEntry类
下面是初始化平方探测散列表的方法
下面是平方探测的contains方法(和它的private助手)
下面是平方探测散列表的insert和remove方法
虽然平方探测排除了一次聚集,但是散列到同一位置上的那些元素将探测相同的备选单元。这称为二次聚集(secondary clustering)。下面的技术可以消除这个问题,但是以计算额外的散列函数为代价。

图4-5 使用双散列方法在每次插入后的散列表
例如,将元素13、15、24和6插入到大小为7的线性探测散列表中。散列函数是h(x)=x mod 7。插入后如图4-5所示。

图4-5 使用线性探测插入13,15,6,24的散列表
将23插入表中,那么图4-6中的表将有70%的单元是满的。因为表太满,所以需要建立一个新表。表大小为原表大小两倍后的第一个素数,新的散列函数为h(x)=x mod 17。得到结果如图4-7。

图4-6 使用线性探测插入23后的散列表

图4-7 再散列后的散列表
整个操作叫做再散列(rehashing)。这显然是一种非常昂贵的操作,其运行时间为Ο(N)。再散列可以用平方探测以多种方法实现。一种做法是只要表满到一半就再散列。另一种极端的方法是只有当插入失败时才再散列。第三种方法即途中策略(middle-of-the-road),当表达到某一个填装因子时进行再散列。第三种可能是最好的实现。
下面是最探测散列表和分离链接散列表的再散列实现。

图4-8 可扩散列:原始数据
设将插入100100。它将进入第三片树叶,但第三片树叶已经满了没有空间,此时将这片树叶分成两片树叶,这由前三个位置决定。

图4-9 可扩散列:在100100插入及目录分裂后
如果现在键入000000,那么第一片树叶就要被分裂。
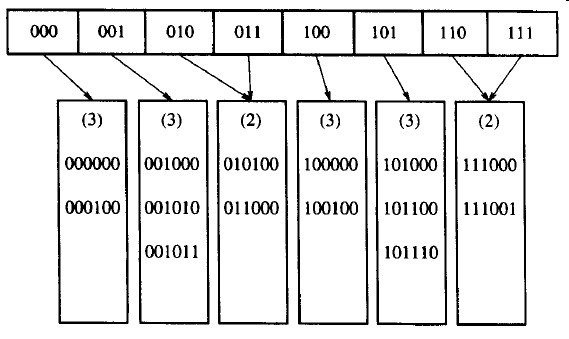
图4-10 可扩散列:在000000插入及树叶分裂后
这个非常简单的方法提供了对大型数据库insert操作和查找操作的快速存取时间。
四 散列
散列表的实现常称为散列(hashing)。散列是一种用于以常数平均时间执行插入,删除和查找的技术。但是,那些需要元素间任何排序信息的树操作将不会得到有效的支持。因此,诸如findMin、findMax以及在线性时间内按顺序打印整个表的操作都是散列表不支持的。本章的中心数据结构是散列表,我们将:看到实现散列表的几种方法。
分析比较这些方法。
介绍散列的多种应用。
将散列表和二叉树查找进行比较。
4.1 基本思想
理想的散列表数据结构只不过是一个包含一些项的具有固定大小的数组。查找一般是对项的某个部分(即数据成员)进行,这部分称为键(key)。我们把表的大小记作TableSize ,并将其理解为散列数据结构的一部分而不仅仅是浮动于全局的某个变量,通常的习惯是让让表从0到TableSize-1变化。将每个键映射到从0到TableSize-1这个范围中的某个数,并且将其放到适当的单元中。这个映射叫做散列函数(hash function),理想情况下它应该运算简单并且应该保证任何两个不同的键映射到不同单元。
这是散列的基本思想。接下来的问题则是要选择一个函数,决定当两个键散列到同一个值的时候(称为冲突(collsion))应该做什么以及如何确定散列表的大小。
4.2 散列函数
如果输入的键是整数,则一般合理的方法就是直接返回“Key mod TableSize”,除非Key碰巧具有某些不理想的性质。好的办法通常是保证表的大小是素数,当输入的键是随机整数时,散列函数不仅运算简单而且键的分配也很均匀。通常键是字符串:在这种情况下,散列函数需要仔细选择。一种方法是把字符串中字符的ASCII码值加起来。代码实现如下:
[code=plain]int hash( const string & key, int tableSize )
{
int hashVal = 0;
for( int i = 0; i < key.length(); i++ )
hashVal += key[ i ];
return hashVal&nb
7ff0
sp;% tableSize;
}上面给出的散列函数简单而且能很快地算出结果。一般情况下然而当表很大,则函数就不会很好地分配键。
下面是另一个散列函数。这个函数假设Key值至少有3个字符。值27表示英文字母表的字母个数外加一个空格。但还是不太好:
[code=plain]int hash( const string & key, int tableSize )
{
return ( key[ 0 ] + 27 * key[ 1 ] + 729 * key[ 2 ] ) % tableSize;
}下面列出了散列函数的第三种尝试。这个散列函数涉及键中的所有字符,并且一般可以分布得很好。程序根据Horner法则计算一个(37的)多项式函数。用计算散列函数省下来的时间来补偿由此产生的对均匀分布的函数的轻微干扰。
[code=plain]/**
* A hash routine for string objects.
*/
int hash( const string & key, int tableSize )
{
int hashVal = 0;
for( int i = 0; i < key.length(); i++ )
hashVal =37 * hashVal + key[ i ];
hashVal %= tableSize;
if( hashVal < 0 )
hashVal += tableSize;
return hashVal;
}剩下的主要编程细节就是解决冲突。解决方法有几种,下面讨论最简单的两种:分离链接法和开放定址法。
4.3 分离链接法
解决冲突的第一种方法通常叫做分离链接法(separate chaining),其做法是将散列同一个值的所有元素保留到一个链表中。图4-1对此进行了更清晰的解释。图4-1 分离链接散列表
为了执行search,我们使用散列函数来确定究竟遍历哪个链表,然后查找相应的表。为执行insert,我们检查相应的表来确定是否该元素已经在表中了(如果要插入重复元,那么通常要流出一个额外的数据成员,当出现匹配事件时这个数据成员增1)。如果这个元素是个新的元素,那么它将被插入到表的前端,这不仅因为方便,而且还因为最后插入的元素有可能不久再次被访问。
实现分离链接法所需的类架构在下面给出。散列表结构存储一个链表数组,这个数组在构造函数中指定。
[code=plain]template<typename HashedObj>
class HashTable
{
public:
explicit HashTable( int size = 101 );
bool contains( const HashedObj & x ) const;
void makeEmpty();
void insert( const HashedObj & x );
void remove( const HashedObj & x );
private:
vector<list<HashedObj> > theList; //The array of Lists
int currentSize;
void rehash();
int myhash( const HashedObj & x ) const;
};
int hash( const string & key );
int hash( int key );本章中的散列表只适合提供散列函数和相等性操作(operator==或operator!=或两者都提供)。这将自动包括int和string。因为在HashTable类中这些散列函数是作为全局的非类函数出现的。下面是散列表类有一个私有的成员函数myhash,这个函数将结果分配到一个合适的数组索引中。
[code=plain]int myhash( const HashedObj & x ) const
{
int hashVal = hash( x );
hashVal %= theLists.size();
if( hashVal < 0 )
hashVal += theList.size();
return hashVal;
}下面列出了一个可以存储Employee类,该类使用name成员作为键。Employee类通过提供相等性操作符和一个散列函数来实现HashObj的需求。
[code=plain]//Exmaple if an Employee class
class Employee
{
public:
const string & getName() const
{ return name; }
bool operator== ( const Employee & rhs ) const
{ return getName() == ths.getName(); }
bool operator!= ( const Employee & rhs ) const
{ return !(*this == rhs); }
//Additional public members not shown
private:
string name;
double salary;
int seniority;
//Additional private members not shown
}
int hash( const Employee & item )
{
return hash( item.getName() );
}下面是分离链接散列表的makeEmpty、contains和remove的程序实现。
[code=plain]void makeEmpty()
{
for( int i = 0; i < theLists.size(); i++ )
theLists[ i ].clear();
}
bool contains( const HashedObj & x ) const
{
const list<HashedObj> & whichList = theLists[ myhash( x ) ];
return find( whichList.begin(), whichList.end(), x ) != whichList.end();
}
bool remove( const HashedObj & x )
{
List<HashedObj> & whichList = theList[ myhash( x ) ];
list<HashedObj>::iterator itr = find( whichList.begin(), whichList.end(), x );
if( itr == whichList.end() )
return false;
whichList.erase( itr );
--currentSize;
return true;
}下面是插入方法。如果要插入的项已经存在,那么什么都不做;否则将其放至表的前端。该元素可以放在表的任何地方:此处使用push_back是最方便的。whichList是一个引用变量。
[code=plain]bool insert( const HashedObj & x )
{
list<HashedObj> & whichList = theLists[ myhash( x ) ];
if( find( whichList.begin(), whichList.end(), x ) ) != whichList.end()
return false;
whichList.push_back( x );
//Rehash;
if( ++currentSize > theLists.size() )
rehash();
return true;
}除链表外,任何的方案也都有可能用来解决冲突现象:一棵查找树,甚至另外一个散列表均可胜任,但我们期望的是如果散列表大而且散列函数好,那么所有的链表都应该短,因此,不值得去进行任何复杂的尝试。
我们定义散列表的填装因子(load factor)λ为散列表中的元素个数与散列表大小的比值。表的平均长度为λ,执行一次查找所需的工作是计算散列函数值所需要的常数时间加上遍历表所需时间。在一次不成功的查找中,要考察的节点数平均为λ。成功的查找则需要遍历大约1+(λ/2)个链。散列表的大小并不重要,填装因子才是重要的。分离链接散列法的一般法则是使得表的大小尽量与预料的元素个数差不多(即,λ≈1)。
4.4 不使用链表的散列表
分离链接散列算法的缺点是使用一些链表。由于给新单元分配地址需要时间,因此这就导致算法的速度有些减慢,同时算法实际上还要求第二种数据结构的实现。使用链表的另一个解决冲突的方法是当冲突发生时就尝试选择另一个单元,直到找到空的单元。更正式地,单元h0(x),h1(x),h2(x),…依次进行式选,其中hi(x)=(hash(x)-f(x)) mod TableSize,且f(0)=0。函数f是冲突解决函数。因为所有的数据都需要置入表内,所以使用这个方案所需要的比分离链接散列需要的表大。一般来说,对于不使用分离链接法的散列表来说,其填装因子应低于0.5。我们称这样的表为探测散列表(probing hash tables)。4.4.1 线性探测
在线性探测中,函数f是i的线性函数,一般情况下f(i)=i。这相当于逐个探测每个单元(使用回绕)来查找出空单元。图4-2显示了解决办法是f(i)=i的散列表。图4-2 每次插入后使用线性探测得到的散列表
只要表足够大,总能够找到一个自由单元,但是如此花费的时间是相当多的。更糟的是,即使表相对较空,这样占据的单元也会开始形成一些区域,其结果称为一次聚集(primary clustering),于是,散列到区域块中的任何键都需要多次试选单元才能解决冲突,然后该键才能添加到相应的区域中。
图4-3把线性探测的性能(虚曲线)与其他更随机的冲突解决方案的期望性能做了比较。成功的查找用S标出,不成功查找和插入分别用U和I标记。
图4-3 对线性探测(虚线)和随机方法的填装因子画出的探测次数(S为成功查找,U为不成功查找,而I为插入时间)
4.4.2 平方探测
平方探测是消除线性探测中一次聚集问题的冲突解决办法。就是冲突函数为二次函数的探测方法。流行的选择是f(i)=i^2。图4-4显示了和前面线性探测例子的输入相同时的平方探测的情况。图4-4 在每次插入后,利用平方探测得到的散列表
平方探测情况更糟:一旦表被填满超过一半,若表的大小不是素数,那么甚至在表被填满一半之前,就不能保证找到空的单元了。因为最多只有表的一半可以用做解决冲突的备选位置。
下面证明如果表一半为空,并且表的大小为素数,那么可以保证总能够插入一个新的元素。
定理4-1 如果使用平方探测,且表的大小是素数,那么当表至少有一半是空的时候,总能够插入一个新的元素。
我们用散列表项单元数组。嵌套的类HashEntry存储在info成员中的一个项的状态,这个状态可以是ACTIVE、ENPTY或DELETED。我们可以用static const数据或者枚举类型,下面是枚举类型:
[code=plain]enum EntryType (ACTIVE, EMPTY, DELETED);
下面是使用探测策略的散列表的类接口,包括嵌套的HashEntry类
[code=plain]template<typename HashedObj>
class HashTable
{
public:
explict HashTable( int size = 101 );
bool contains( const HashedObj & x ) const;
bool insert( const HashedObj & x );
bool remove( const HashedObj & x );
enum EntryType( ACTIVE, EMPTY, DELETED );
private:
struct HashEntry
{
HashedObj element;
EntryType info;
HashEntry( const HashedObj & e = HashedObj(), EntryType i = EMPTY )
: element( e ), info( i ) { }
};
vector<HashEntry> array;
int currentSize;
bool isActive( int currentSize ) const;
int findPos( const HashedObj & x ) const;
void rehash();
int myhash( const HashedObj & x ) const;
}下面是初始化平方探测散列表的方法
[code=plain]explicit HashTable( int size = 101 ) : array( nextPrime( size ) )
{ makeEmpty(); }
void makeEmpty()
{
currentSize = 0;
for( int i = 0; i < array.size(); i++ )
array[ i ].info = EMPTY;
}下面是平方探测的contains方法(和它的private助手)
[code=plain]bool contains( const HashedObj & x ) const
{ return isActive( findPos( x ) ); }
int findPos( const HashedObj & x ) const
{
int offset = 1;
int currentPos = myhash( x );
while( array[ currentPos ].info != EMPTY && array[ currentPos ].element != x )
{
currentPos += offset; //Compute ith probe
offset += 2;
if( currentPos >= array.size() )
currentPos += array.size();
}
return currentSize;
}
bool isActive( int currentPos ) const
{ return array( currentPos ) info == ACTIVE; }下面是平方探测散列表的insert和remove方法
[code=plain]bool insert( const HashedObj & x )
{
// Insert x as active
int currentPos = findPos( x );
if( isActive( currentPos ) )
return false;
array[ currentPos ] = HashEntry( x, ACTIVE );
// Rehash
if( !currentSize > array.size() / 2 )
rehash();
return true;
}
bool remove( const HashedObj & x )
{
int currentPos = findPos( x );
if( !isActive( currentPos ) )
return false;
array[ currentPos ].info = DELETED;
return true;
}虽然平方探测排除了一次聚集,但是散列到同一位置上的那些元素将探测相同的备选单元。这称为二次聚集(secondary clustering)。下面的技术可以消除这个问题,但是以计算额外的散列函数为代价。
4.4.3 双散列
最后一个冲突解决办法是双散列(double hashing)。一种流行的方法是f(i)=i*hash2(x)。这个公式是说,将第二个散列函数应用到x并在距离hash2(x),2hash2(x),…等处探测。诸如,hash2(x)=R-(x mod R),下面是同样的输入,双散列的结果。图4-5 使用双散列方法在每次插入后的散列表
4.5 再散列
对于使用平方探测的开放定址散列法,如果表的元素填得太满,那么操作的运行时间将开始消耗过长,且插入操作可能失败。这可能发生在有太多的删除和插入混合的场合。此时,一个解决办法是建立另外一个大约两倍大的表(而且使用一个相关的新的散列函数),扫描整个原始散列表,计算每个(不删除的)元素的新散列值并将其插入到新表中。例如,将元素13、15、24和6插入到大小为7的线性探测散列表中。散列函数是h(x)=x mod 7。插入后如图4-5所示。
图4-5 使用线性探测插入13,15,6,24的散列表
将23插入表中,那么图4-6中的表将有70%的单元是满的。因为表太满,所以需要建立一个新表。表大小为原表大小两倍后的第一个素数,新的散列函数为h(x)=x mod 17。得到结果如图4-7。
图4-6 使用线性探测插入23后的散列表
图4-7 再散列后的散列表
整个操作叫做再散列(rehashing)。这显然是一种非常昂贵的操作,其运行时间为Ο(N)。再散列可以用平方探测以多种方法实现。一种做法是只要表满到一半就再散列。另一种极端的方法是只有当插入失败时才再散列。第三种方法即途中策略(middle-of-the-road),当表达到某一个填装因子时进行再散列。第三种可能是最好的实现。
下面是最探测散列表和分离链接散列表的再散列实现。
[code=plain]/**
* Rehashing for quadratic probing hash table
*/
void rehash()
{
vector<HashEntry> oldArray = array;
// Create new double-sized, empty table
array.resize( nextPrime( 2 * oldArray.size() ) );
for( int j = 0; j < array.size(); j++ )
array[ j ].info = EMPTY;
// Copy table over
currentSize = 0;
for( int i = 0; i < oldArray.size(); i++ )
if( oldArray[ i ].info == ACTIVE )
insert( oldArray[ i ].element );
}
/**
* Rehashing for separate chaining hash table
*/
void rehash()
{
vector<list<HashedObj> > oldLists = theLists;
// Create new double-sized,empty table
theLists.resize( nextPrime( 2 * theLists.size() ) );
for( int j = 0; j < theList.size(); j++ )
theLists[ j ].clear();
// Copy table over
currentSize = 0;
for( int i = 0; i < oldLists.size(); i++ )
{
list<HashedObj>::iterator itr = oldLists[ i ].begin();
while( itr != oldLists[ i ].end() )
insert( *itr++ );
}
}4.6 标准库中的散列表
标准库中不包括map和set的散列实现。但许多编译器提供hash_set和hash_map。4.7 可扩散列
最后讨论数据量太大以至于装不进主存的情况。主要考虑的是所需磁盘存取的次数。一种聪明的做法叫做可扩散列(extendible hashing),它允许用两次磁盘访问执行一次查找。插入操作也需要很少的磁盘访问。图4-8 可扩散列:原始数据
设将插入100100。它将进入第三片树叶,但第三片树叶已经满了没有空间,此时将这片树叶分成两片树叶,这由前三个位置决定。
图4-9 可扩散列:在100100插入及目录分裂后
如果现在键入000000,那么第一片树叶就要被分裂。
图4-10 可扩散列:在000000插入及树叶分裂后
这个非常简单的方法提供了对大型数据库insert操作和查找操作的快速存取时间。
