Tomcat源码解析(五):Connector连接器的初始化和启动流程
2016-03-15 19:38
633 查看
Connector是Tomcat最核心的组件之一,每个Service服务下存在多个Connector连接器,Connector的处理性能决定了Tomcat服务的性能,此处记录为Tomcat4的连接器工作机制。
Tomcat4中Connector模块的类可以划分以下部分:
1、连接器及其处理器类(HttpConnector和HttpProcessor);
2、表示Http请求类(HttpRequest)及其支持类;
3、表示Http响应类(HttpResponse)及其支持类;
4、外观装饰类(HttpRequestFacade和HttpResponseFacade);
Tomcat中连接器必须实现Connector接口,接口中声明很多方法,其中最重要的如下:
Tomcat4中HttpConnector通过ServerSocket循环接受Http请求连接,实际进一步处理则委托给HttpProcessor对象池处理,而HttpProcessors对象池多线程并行执行多个任务,所以实际性能取决于HttpProcessor对象池的工作机制。
HttpConnector每次接受新的Http请求连接后,将处理工作委托给HttpProcessor对象池,而HttpConnector本身则继续接受下一个请求,使得HttpConnector一直处于循环接受工作状态,无需等待一个请求处理完毕再去接受下一个请求。工作处理流程如图:
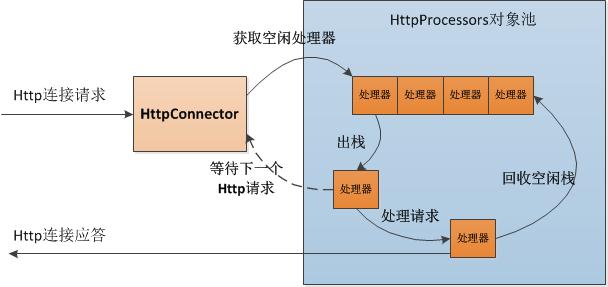
HttpConnector的初始化流程
1、触发HttpConnector启动事件,通知相关监听器;
2、开启后端线程,循环监听Http请求连接;
3、创建初始处理器对象池;
2、如果出现maxProcessors大于minProcessors情形,则创建个数依据maxProcessors,如minProcessors=5,maxProcessors=3,则创建3个HttpProcessor;
注意此处的recycle()方法,即回收处理器,只存在两种情形下执行:
1、启动之初,新创建处理器实例,加入空闲处理器队列;
2、处理器执行完请求,变成空闲,则处理器会主动加入空闲队列;
查看下处理器创建方法,newProcessor(),实际则创建实例并启动
接下来查看后端线程创建实现具体:
1、阻塞等待Http请求;
2、为每个请求分配一个HttpProcessor对象;
3、调用HttpProcessor的process()方法处理;
实际HttpConnector工作创建的HttpProcessor的个数在creatProcessor中具体实现,查看如下:
1、如果processors(未使用)集合中存在空闲处理器,则出栈获取;
2、当前处理器个数小于最大处理器参数,即curProcessors<maxProcessors,则创建新实例;
3、如果maxProcessors参数小于0,则无限制创建新实例;
4、如果处理器个数等于最大处理器参数,即curProcessors=maxProcessors,则忽略处理,返回null;
实际HttpConnector和HttpProcessor工作机制在后续详细分析。
Tomcat4中Connector模块的类可以划分以下部分:
1、连接器及其处理器类(HttpConnector和HttpProcessor);
2、表示Http请求类(HttpRequest)及其支持类;
3、表示Http响应类(HttpResponse)及其支持类;
4、外观装饰类(HttpRequestFacade和HttpResponseFacade);
Tomcat中连接器必须实现Connector接口,接口中声明很多方法,其中最重要的如下:
public interface Connector {
// 关联容器
public Container getContainer();
public void setContainer(Container container);
// 所属Service服务
public Service getService();
public void setService(Service service);
// 根据http请求信息构建请求和响应对象
public Request createRequest();
public Response createResponse();
// 初始化
public void initialize() throws LifecycleException;
}Connector默认Http协议的实现类是HttpConnector,该类同时实现了Runnable接口和LifeCycle接口。Tomcat4中HttpConnector通过ServerSocket循环接受Http请求连接,实际进一步处理则委托给HttpProcessor对象池处理,而HttpProcessors对象池多线程并行执行多个任务,所以实际性能取决于HttpProcessor对象池的工作机制。
HttpConnector每次接受新的Http请求连接后,将处理工作委托给HttpProcessor对象池,而HttpConnector本身则继续接受下一个请求,使得HttpConnector一直处于循环接受工作状态,无需等待一个请求处理完毕再去接受下一个请求。工作处理流程如图:
HttpConnector的初始化流程
public void initialize()
throws LifecycleException {
// 防止重复初始化
if (initialized)
......
// 记录初始化
this.initialized=true;
Exception eRethrow = null;
// Establish a server socket on the specified port
try {
// 创建ServerSocket实例
serverSocket = open();
} ...
}HttpConnector的启动流程1、触发HttpConnector启动事件,通知相关监听器;
2、开启后端线程,循环监听Http请求连接;
3、创建初始处理器对象池;
public void start() throws LifecycleException {
// Validate and update our current state
if (started)
throw new LifecycleException
(sm.getString("httpConnector.alreadyStarted"));
// 监听线程名称
threadName = "HttpConnector[" + port + "]";
// 触发启动事件
lifecycle.fireLifecycleEvent(START_EVENT, null);
started = true;
// 开启后端线程,ServerSocket循环监听Http请求连接
threadStart();
4000
// 创建初始处理器个数
while (curProcessors < minProcessors) {
if ((maxProcessors > 0) && (curProcessors >= maxProcessors))
break;
HttpProcessor processor = newProcessor();
recycle(processor);// 入栈未使用processors
}
}可以看出初始默认HttpProcessor处理器个数取决于minProcessor,部分相关属性如下:// 当前被创建的处理器个数 private int curProcessors = 0; // 最小处理器个数 protected int minProcessors = 5; // 最大处理器个数,小于0则无限制 private int maxProcessors = 20; // 已经被创建处理器集合 private Vector created = new Vector(); // 已经空闲处理器集合 private Stack processors = new Stack();启动初,HttpProcessor的默认创建规则如下:
// 创建初始处理器个数
while (curProcessors < minProcessors) {
if ((maxProcessors > 0) && (curProcessors >= maxProcessors))
break;
HttpProcessor processor = newProcessor();
recycle(processor);
}1、默认HttpProcessor个数依据minProcessors创建,如果minProcessors=5,则创建5个HttpProcessor;2、如果出现maxProcessors大于minProcessors情形,则创建个数依据maxProcessors,如minProcessors=5,maxProcessors=3,则创建3个HttpProcessor;
注意此处的recycle()方法,即回收处理器,只存在两种情形下执行:
1、启动之初,新创建处理器实例,加入空闲处理器队列;
2、处理器执行完请求,变成空闲,则处理器会主动加入空闲队列;
查看下处理器创建方法,newProcessor(),实际则创建实例并启动
private HttpProcessor newProcessor() {
// 创建HttpProcessor实例,传入当前HttpConnector引用
// curProcessors个数+1,并用此curProcessors数字作为HttpProcessorid号
HttpProcessor processor = new HttpProcessor(this, curProcessors++);
if (processor instanceof Lifecycle) {
try {
// 启动当前HttpProcessor,实例开启线程接口处理请求
((Lifecycle) processor).start();
} catch (LifecycleException e) {
log("newProcessor", e);
return (null);
}
}
// 加入已经创建HttpProcessor集合
created.addElement(processor);
return (processor);
}HttpProcessor的构造方法如下:public HttpProcessor(HttpConnector connector, int id) {
super();
this.connector = connector;
this.debug = connector.getDebug();
this.id = id;
this.proxyName = connector.getProxyName();
this.proxyPort = connector.getProxyPort();
// 请求和应答对象,可以看出是由connector创建
this.request = (HttpRequestImpl) connector.createRequest();
this.response = (HttpResponseImpl) connector.createResponse();
this.serverPort = connector.getPort(); // 端口
this.threadName =
"HttpProcessor[" + connector.getPort() + "][" + id + "]"; // 线程名称
}接下来查看后端线程创建实现具体:
private void threadStart() {
log(sm.getString("httpConnector.starting"));
thread = new Thread(this, threadName);
thread.setDaemon(true);
thread.start();
}由于当前this已经实现runable接口,所以线程执行工作在当前connector的run方法,主要工作如下:1、阻塞等待Http请求;
2、为每个请求分配一个HttpProcessor对象;
3、调用HttpProcessor的process()方法处理;
public void run() {
// 循环,直到shutdown
while (!stopped) {
// 监听socket
Socket socket = serverSocket.accept();
// 为socket分配处理器
HttpProcessor processor = createProcessor();
// 如果当前没有空闲处理器
if(processor == null) {
// 忽略请求,不做处理
}
// 执行处理
processor.assign(socket);
}
}实际HttpConnector工作创建的HttpProcessor的个数在creatProcessor中具体实现,查看如下:
private HttpProcessor createProcessor() {
synchronized (processors) {
// 当前processors集合中存在空闲处理器
if (processors.size() > 0) {
// 则获取返回
return ((HttpProcessor) processors.pop());
}
// 当前处理器个数小于最大处理器个数,则创建新处理器实例
if ((maxProcessors > 0) && (curProcessors < maxProcessors)) {
return (newProcessor());
} else {
// maxProcessors小于0,则无限制创建新实例
if (maxProcessors < 0) {
return (newProcessor());
// curProcessors = maxProcessors,已经不能创建新实例,忽略
} else {
return (null);
}
}
}
}总结运行中创建规则如下:1、如果processors(未使用)集合中存在空闲处理器,则出栈获取;
2、当前处理器个数小于最大处理器参数,即curProcessors<maxProcessors,则创建新实例;
3、如果maxProcessors参数小于0,则无限制创建新实例;
4、如果处理器个数等于最大处理器参数,即curProcessors=maxProcessors,则忽略处理,返回null;
实际HttpConnector和HttpProcessor工作机制在后续详细分析。

相关文章推荐
- mac下安装tomcat
- Linux下启动启动tomcat 服务器报错 The file is absent or does not have execute permission
- MyEclipse下Tomcat启动变慢 解决方法
- Tomcat虚拟目录配置
- Tomcat实现Session对象的持久化原理及配置方法介绍
- maven tomcat7:deploy
- java与tomcat类加载机制
- tomcat log 配置解决catalina.out文件过大问题
- tomcat catalina.out 日志分割
- tomcat虚拟目录配置方法
- Tomcat启动报Error listenerStart错误
- 动静分离—Nginx+Tomcat
- MyEclipse2014 怎么将项目部署在tomcat的ROOT目录下
- 为tomcat指定JDK
- MyEclipse 启动 Tomcat 配置容器内存分配
- Windows下的修改Tomcat的可用内存
- Tomcat 输出日志文件 catalina.out 大小控制
- Tomcat Connector三种运行模式(BIO, NIO, APR)的比较和优化
- tomcat如何与serverlet交互
- tomcat配置及优化