oracle-函数
2016-03-15 15:12
711 查看
1. 聚合函数
聚合函数是我们最经常使用的函数如avg()、sum()、count()、max()、min()、
等。需要注意的是聚合函数和分组函数的配合使用!如果查询语句使用Group by ,那么select 的字段必须为group by 指定的字段或者使用聚合函数。如
Select sum(a),avg(b),max(c),d from A group by d;
2. 递归函数
Start with connect by poir
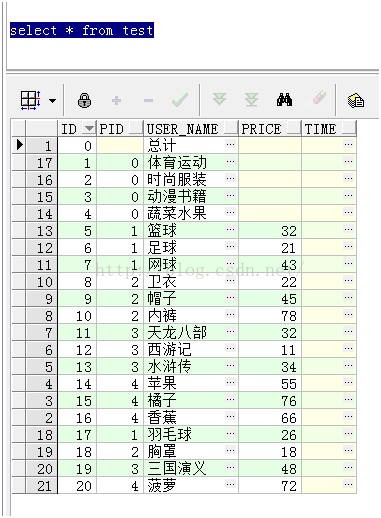
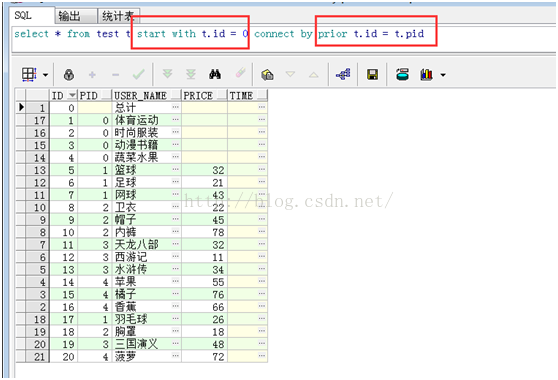
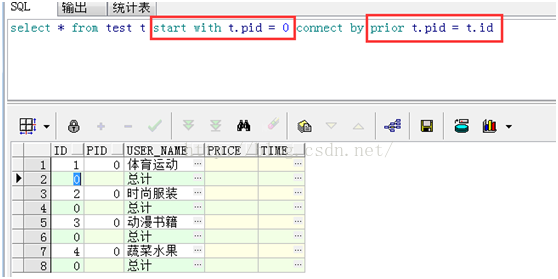
仔细观察这两条语句,可以发现start with 为开始 查询的范围connect by prior 则为
查询的条件,比如第二条语句,start with t.pid = 0 首先查询出pid = 0的4条数据,之后查询出id = 0 (即id in 这4条数据的pid)的其余数据
3. 行专列函数
Vm_concat()逗号拼接
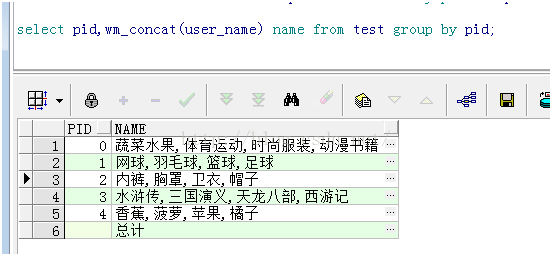
Pivot unpivot
http://blog.csdn.net/fw0124/article/details/7943965
4. 开窗函数
(1) 统计分析
ratio_to_report(a) over() 查询a字段 所占的比列 a/sum(a)
(2) 排序
Rank() over() , dense_rank() over , row_number() over
如有表Test,数据如下
Java代码
CREATEDATE ACCNO MONEY
2014/6/5 111 200
2014/6/4 111 600
2014/6/5 111 400
2014/6/6 111 300
2014/6/6 222 200
2014/6/5 222 800
2014/6/6 222 500
2014/6/7 222 100
2014/6/6 333 800
2014/6/7 333 500
2014/6/8 333 200
2014/6/9 333 0
比如要根据ACCNO分组,并且每组按照CREATEDATE排序,是组内排序,并不是所有的数据统一排序,
用下列语句实现:
Sql代码
select t.*,row_number() over(partition by accno order by createDate) row_number from Test t
查询结果如下:
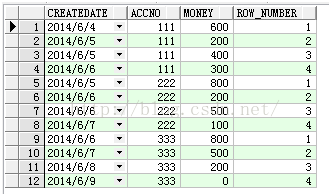
大家可以注意到ACCNO为111的记录有两个相同的CREATEDATE,用row_number函数,他们的组内计数是连续唯一的,但是如果用rank或者dense_rank函数,效果就不一样,如下:
rank的sql:
Sql代码
select t.*,rank() over(partition by accno order by createDate) rank from Test t
查询结果:
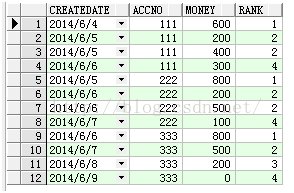
可以发现相同CREATEDATE的两条记录是两个第2时接下来就是第4.
dense_rank的sql:
Sql代码
select t.*,dense_rank() over(partition by accno order by createDate) dense_rank from Test t
查询结果:
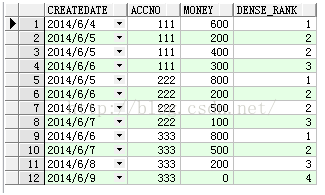
可以发现相同CREATEDATE的两个字段是两个第2时接下来就是第3.
项目中特殊的业务需求可能会要求用以上三个不同的函数,具体情况具体对待。
再比如有时会要求分组排序后分别取出各组内前多少的数据记录,sql如下:
Sql代码
select createDate,accno,money,row_number from (select t.*,row_number() over(partition by accno order by createDate) row_number from Test t) t1 where row_number<4
查询结果如下:
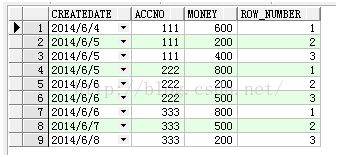
聚合函数是我们最经常使用的函数如avg()、sum()、count()、max()、min()、
等。需要注意的是聚合函数和分组函数的配合使用!如果查询语句使用Group by ,那么select 的字段必须为group by 指定的字段或者使用聚合函数。如
Select sum(a),avg(b),max(c),d from A group by d;
2. 递归函数
Start with connect by poir
仔细观察这两条语句,可以发现start with 为开始 查询的范围connect by prior 则为
查询的条件,比如第二条语句,start with t.pid = 0 首先查询出pid = 0的4条数据,之后查询出id = 0 (即id in 这4条数据的pid)的其余数据
3. 行专列函数
Vm_concat()逗号拼接
Pivot unpivot
http://blog.csdn.net/fw0124/article/details/7943965
4. 开窗函数
(1) 统计分析
ratio_to_report(a) over() 查询a字段 所占的比列 a/sum(a)
(2) 排序
Rank() over() , dense_rank() over , row_number() over
如有表Test,数据如下
Java代码
CREATEDATE ACCNO MONEY
2014/6/5 111 200
2014/6/4 111 600
2014/6/5 111 400
2014/6/6 111 300
2014/6/6 222 200
2014/6/5 222 800
2014/6/6 222 500
2014/6/7 222 100
2014/6/6 333 800
2014/6/7 333 500
2014/6/8 333 200
2014/6/9 333 0
比如要根据ACCNO分组,并且每组按照CREATEDATE排序,是组内排序,并不是所有的数据统一排序,
用下列语句实现:
Sql代码
select t.*,row_number() over(partition by accno order by createDate) row_number from Test t
查询结果如下:
大家可以注意到ACCNO为111的记录有两个相同的CREATEDATE,用row_number函数,他们的组内计数是连续唯一的,但是如果用rank或者dense_rank函数,效果就不一样,如下:
rank的sql:
Sql代码
select t.*,rank() over(partition by accno order by createDate) rank from Test t
查询结果:
可以发现相同CREATEDATE的两条记录是两个第2时接下来就是第4.
dense_rank的sql:
Sql代码
select t.*,dense_rank() over(partition by accno order by createDate) dense_rank from Test t
查询结果:
可以发现相同CREATEDATE的两个字段是两个第2时接下来就是第3.
项目中特殊的业务需求可能会要求用以上三个不同的函数,具体情况具体对待。
再比如有时会要求分组排序后分别取出各组内前多少的数据记录,sql如下:
Sql代码
select createDate,accno,money,row_number from (select t.*,row_number() over(partition by accno order by createDate) row_number from Test t) t1 where row_number<4
查询结果如下:

相关文章推荐
- mysql数据行转列
- 字符串聚合函数(去除重复值)
- SQL学习笔记四 聚合函数、排序方法
- table 行转列的sql详解
- Sql Server 2000 行转列的实现(横排)
- SQLServer行转列实现思路记录
- Web服务器日志统计分析完全解决方案
- MySQL存储过程中使用动态行转列
- 开窗函数有浅入深详解(一)
- Oracle逗号分隔列转行实现方法
- 关于SELECT子句中使用聚合函数
- ORACLE SQL 组函数 (聚合函数)
- 利用Oracle的wm_concat函数把行转为列,合并分组后的列值
- Testin云测试平台开发者有奖活动
- Transformation language 方法 IN, MAX
- 行列转换
- sql行转列,列转行
- 移动APP数据分析能做什么
- Oracle行转列实现方法(附实例)