SQL语句执行顺序图文介绍
2016-03-15 00:00
369 查看
摘要: SQL语句执行顺序图文介绍
SQL语句执行顺序图文介绍
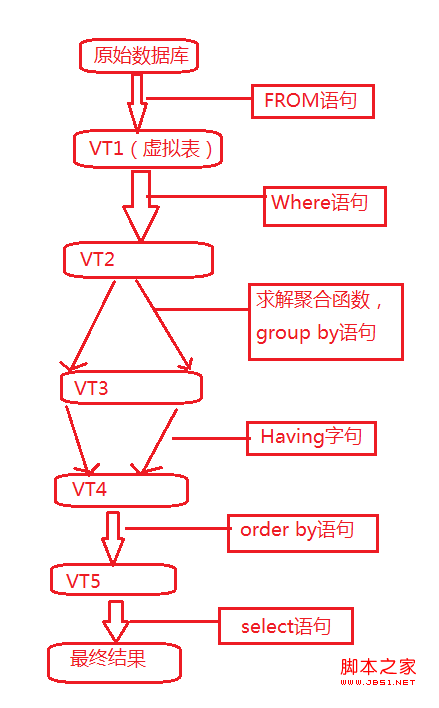
从这个图里我们就可以看出来,为什么where里不能包含聚合函数了吧,因为SQL是先执行where后执行聚合函数,如果where里含有聚合函数,那么这时聚合函数还没有执行,也就没有结果供where使用了。大家好好消化一下这个图。
where 条件执行顺序:
过滤掉最多数据最多的先执行,这些都是优化器做的事;
在这个查询中s.cid = c.cid是对应一个自然连接操作,t_student表上 age >20 and name like '%三%'对应两个选择操作,其中 age >20可以使用索引,而name like '%三%'不能够使用索引
因此,在age上有索引的情况下,数据库的查询优化器会按照如下顺序执行:
1 在表t_student上的age字段的索引上执行 age >20的索引扫描,得到相应记录;
2 在1中得到的记录上执行name like '%三%'选择操作;
3 将2中得到的记录与,t_class 表按照s.cid = c.cid执行连接操作。
那在没有索引情况下呢?执行顺序又是如何?为什么不是先连接查询然后再进行条件过滤?
对于这个语句没有索引的情况下应该也是按照这个顺序执行的,因为比较操作符执行的效率高,所以先处理age >20,再处理name like '%三%',然后再执行连接
之所以要先执行过滤再执行连接,是因为这样做需要的内存小,执行速度快。
举个例子t_student有1000个记录,t_class有50个记录,如果先执行连接,需要时间复杂度是1000*50,然后会产生1000个记录,这些记录都要存在内存中,然后进行选择操作,得到5个结果
如果先执行选择,假设对1000个记录选择得到50个记录,再用这50个与t_class有50个记录连接,时间复杂度是50*50,结果也是50个记录,中间需要的内存和执行时间都小。
建议你看看《数据库系统实现》,里面有详细的原理说明。
SQL Select语句完整的执行顺序: 1、from子句组装来自不同数据源的数据; 2、where子句基于指定的条件对记录行进行筛选; 3、group by子句将数据划分为多个分组; 4、使用聚集函数进行计算; 5、使用having子句筛选分组; 6、计算所有的表达式; 7、使用order by对结果集进行排序。 8、select 集合输出。
SQL语句执行顺序图文介绍
从这个图里我们就可以看出来,为什么where里不能包含聚合函数了吧,因为SQL是先执行where后执行聚合函数,如果where里含有聚合函数,那么这时聚合函数还没有执行,也就没有结果供where使用了。大家好好消化一下这个图。
where 条件执行顺序:
select s.name,c.cname from t_student s,t_class c where s.cid = c.cid and age >20 and name like '%三%'
过滤掉最多数据最多的先执行,这些都是优化器做的事;
在这个查询中s.cid = c.cid是对应一个自然连接操作,t_student表上 age >20 and name like '%三%'对应两个选择操作,其中 age >20可以使用索引,而name like '%三%'不能够使用索引
因此,在age上有索引的情况下,数据库的查询优化器会按照如下顺序执行:
1 在表t_student上的age字段的索引上执行 age >20的索引扫描,得到相应记录;
2 在1中得到的记录上执行name like '%三%'选择操作;
3 将2中得到的记录与,t_class 表按照s.cid = c.cid执行连接操作。
那在没有索引情况下呢?执行顺序又是如何?为什么不是先连接查询然后再进行条件过滤?
对于这个语句没有索引的情况下应该也是按照这个顺序执行的,因为比较操作符执行的效率高,所以先处理age >20,再处理name like '%三%',然后再执行连接
之所以要先执行过滤再执行连接,是因为这样做需要的内存小,执行速度快。
举个例子t_student有1000个记录,t_class有50个记录,如果先执行连接,需要时间复杂度是1000*50,然后会产生1000个记录,这些记录都要存在内存中,然后进行选择操作,得到5个结果
如果先执行选择,假设对1000个记录选择得到50个记录,再用这50个与t_class有50个记录连接,时间复杂度是50*50,结果也是50个记录,中间需要的内存和执行时间都小。
建议你看看《数据库系统实现》,里面有详细的原理说明。

相关文章推荐
- Linux MariaDb 中文乱码
- 数据库超时空闲失效-dbcp连接池参数优化
- 37.Oracle深度学习笔记——RAC的相关等待事件
- 第57课:Spark SQL on Hive配置及实战
- mysql基本用法
- SQLiteDatabase
- mysq数据框架bookshelf文档
- [021]Redis与Memcached的区别
- MySQL数据库引擎介绍
- excel表格导入到mysql
- Memcached(1)------windows平台下安装
- Oracle 10g实现存储过程异步调用
- Greendao 使用总结
- mysql字段类型
- 扒扒数据库长长知识(下载资源组合看)之 02(基本SQL SELECT语句)
- 扒扒数据库长长知识(下载资源组合看)之 00(oracle简介)
- java之redis篇(spring-data-redis整合)
- oracle基本总结
- mysql 中文乱码问题
- SQL Server 2016 RC0 安装(超多图)