数据结构与算法之链表
2016-03-14 23:44
316 查看
@ CloudGuan
@ Copyright 2016 Cloud Guan, Inc. All Rights Reserved.
由于本文作者最近一直在写c++,所以程序中难免带有大量的c++的风格,希望各位读者见谅。
在学习数据结构与算法之前,希望各位有比较扎实的c语言基础,至少对文中提到的数组,指针较为熟悉,不然的话,你怎么不去重修c语言!!!
本文版权归作者CloudGuan所有,转载请注明,对于一切未经注明出处,转载转授本文的,你妈炸了!!!
在计算机中,理解存储数据也可以联想超市中的储物柜,我们依靠柜子的标签来找到属于我们的那个唯一的柜子,依靠钥匙来打开柜子,这就是我们常说的对于指针的操作,我们依靠&运算符来获得地址,也就是上述的例子编号,我们依靠*运算符来拿到地址。请不要小看这个操作,就像我们两个一起去逛超市的时候,每次要先拿到地址,然后找到柜子(一般我们都是一行一行的找的)然后打开柜子拿出东西,从内存中拿出东西也是一样,有这些步骤。
那么接下来问题就来了,数据结构到底是什么?是玄学吗?是魔法吗? 都不是 就像生活中要收拾自己的东西一样,我们知道数据是对于我们有用的值,单元是存储数据的容器,并且这些容器还是有限的,那么怎么有效的利用这些容器,存储数据就是我们接下考虑的问题。故而我认为 数据结构是组织管理数据的有效方式
这里扩展一下,计算机的内存是十分宝贵的,我们要尽可能的减少一个程序对于内存的占用,所以对于一个经常使用长度为20的数组,但是最大长度为i1000的数组,我们有两种解决方案:
1. 声明的时候声明长度为1000,这样的好处的数组是够用的,但是坏处是,绝大多数时候有980个空间是不被使用的,且别的程序也不能够使用,这无疑是很让人心疼的一件事。
2. 第二个解决方案,就是先声明20长度,够的时候在重新分配。这听上去很棒,但是事实并不是如此。这个需要我们了解内存的分配方式。
在内存中空间开辟是离散的!这句话的意思就是我们给你盒子的时候,是那个有空就给你那个,所以我给你数组的时候,不是说你像想在这个数组皮龟后面加东西就能加东西的,我只有重新分配一个数组空间,这个空间和上个空间差距很远,所以我需要把上个数组的东西拷贝过来,听起来就很麻烦是吧?事实也是这是一个非常麻烦的操作
接下来我们来看个
这个语句可以程序运行时动态的申请内存,并且返回这个内存的指针type不是申请的容器的类型比如int bool啥的,num表示要申请的内存有多少块。
然后我们想像一个场景,我是一个学校的老师,需要统计我们学生的信息,用来存储,我们需要的信息有学生的学号,姓名,年龄,以及学院编号。我们如何设计? 没有一个现成的数据类型来包含这些,所以需要自定义一个结构体!使用struct Name{};来定义我们的结构体,然后typedef 可以重命名这个结构体
这个结构体是使用StudentsMessage和Students都是可以得
好的我们看到上面我们自己定义了一个数据结构来管理我们的学生,并且取名为student。但是我们信软学院嘛,学生数目不稳定,不知道傻逼的学院打算招多少人那?这个时候作为一个苦逼的程序员如何满足学院这个需求那?就用到了刚才说到的链表(其实有更加专业的工具——数据库)。我们用优化下这个结构,我们给加上指向下一个这个结构的指针
next指向下一个这个结构的地址,所以我们的数据就用了如下的方式串联了起来。是不是很形象?只要我知道上一个节点的信息,我只要读取他的next我就可以知道他的下一个节点是啥? 就像这样
只要next不为空就说明有下一个数值,next说明就到底了。但是这样也会有随之而来的问题,那就这个结构很方便的可以知道下一个,但是不知道上一个节点?这个又咋办?于是有了双向链表

一个结构指向了下一个结构,这就是单向,然后我们在加入一个指针
这个就是图中的双向表,每个节点我们都指向了他的上一个节点。另外,为了能够链表到底之后能够很快的回到链表的头,有的链表将尾巴这个节点的next不是置为空,而是指向头,这那就是我们说的循环链表
首先第一个问题如何生成一个节点,我们知道编译器在编译程序的时候会为了我们初始化简单的数据,但是复杂的数据编译器是怎么初始化的那?这个无疑是很让人疑惑的,并且还会便随着什么时候去初始化这个变量的问题,所以我们选择了自己去初始化。
这里就得到了一个指向学生这个结构的指针,我们初始化它一下:
因为没有下一个节点,我们把说下一个指向null;
要是再有一个节点那? 这个就是我们把链表串联起来的操作
既然创建了链表的节点,并且能够将链表连接起来了,接下类就是要思考如何遍历链表的问题,回忆下链表的结构是一个数据位和一个指针位。每个指针指向了下一个节点的地址,然后下一个节点里面包含了一个指针位,又存着下一个节点的指针地址,所以只要拿着一个节点的指针,就能找到下一个节点。所以结果出来了,可以用一个循环,只要节点的指针不为空(我们规定没有下一个节点的链表节点指针设置为空),就一直查找下去代码如下:
能够遍历整个链表了自然需要学习查找,毕竟遍历是查找的基础,如下代码找到特定位置的链表。当然传入的也可以不是第那个位置的表,也可以是数据位的数值,比较是否相等
上面的程序就是只要没有到底(if(temp->next)) 的判断就为真(因为我们链表的底为空指针)那么就继续往下查找,temp=temp->next; 这里做的就是把下一个位置的地址赋值给当前链表,然后是关于插入数值的操作,我们要在x位置插入一个节点node
来看这段程序,node为要能插入的节点,head为表头,要插入到index个位置,要怎么做?想想这个逻辑,首先找到index的前一个,也就是index-1;这个即使for循环做的事情,然后我们用node的next指向index这个位置,然后用temp(index-1位置)这个节点的next指向node是不是就串了起来?形象的表示,如图所示:
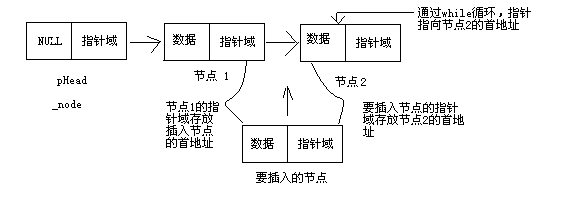

这两张图都是形象的表示链表插入的图片,叉表示对就是代码中的操作,改变记录的链接操作
再插入和遍历查找都练习了一遍之后,自然而然便会想到,应该如何删除链表的某个节点?回忆一下链表的形样子,联想上面的图,删除特定节点这个事情简单的分解一下,就是首先要找到这个节点,然后将节点移除。如何移除那?看看下图的一个节点,19号节点要移除出这个链表是不是要先找到19号节点,然后拿到19号的前一个以及下一个节点的信息,把上一号节点的next指针指向19号的下一个节点,把19号的next指针置为空。这样19号与链表的联系就断开了。


正如上图形象的描述那样,B节点就离开了整个链表。来结合前面的代码,思考下这段代码如何实现,tips:
首先找到这个节点和这个节点的前一个节点(因为这个节点只包含其下一个节点的指针。)
讲这个节点前一个节点(用A表示)的next指向其下一个节点,然后当前节点next指针置为空。
代码如下:
好了关于链表的基础操作就基本完了,任何的复杂功能都逃不出这几个简单功能。在复杂的链表也是要有一个函数负责创建,一个函数负责讲节点加入当前链表,一个函数查找,一个函数负责找到之后的操作,接着就是删除。希望对你有所帮助
Copyright 2016 CloudGuan ,Inc.All Rights Reserved.
@ Copyright 2016 Cloud Guan, Inc. All Rights Reserved.
数据结构与算法
最近朋友抱怨数据结构与算法老师讲的很难,所以我抽了我的空余时间将数据结构与算法的东西看了一遍,希望能为她做做复习提纲。不过回想起我的数据结构与算法学的也并不好,于是干脆一博客的形式记录我在看书时候的感悟与知识重点。由于本文作者最近一直在写c++,所以程序中难免带有大量的c++的风格,希望各位读者见谅。
在学习数据结构与算法之前,希望各位有比较扎实的c语言基础,至少对文中提到的数组,指针较为熟悉,不然的话,你怎么不去重修c语言!!!
本文版权归作者CloudGuan所有,转载请注明,对于一切未经注明出处,转载转授本文的,你妈炸了!!!
链表
开始前的复习
让我们先来复习一下,计算机按照存储单元来存储数据,一个单元存储一个数据。单元的有大小,不同的大小我们使用不同的数据来进行保存。我们用位数来描述或者说记录存储单元的大小,比如8位,16位的等。常见的存储单元我们在语言中用特定的变量来表示,比如我们说int型变量占32位,指针占4个字节等等。在计算机中,理解存储数据也可以联想超市中的储物柜,我们依靠柜子的标签来找到属于我们的那个唯一的柜子,依靠钥匙来打开柜子,这就是我们常说的对于指针的操作,我们依靠&运算符来获得地址,也就是上述的例子编号,我们依靠*运算符来拿到地址。请不要小看这个操作,就像我们两个一起去逛超市的时候,每次要先拿到地址,然后找到柜子(一般我们都是一行一行的找的)然后打开柜子拿出东西,从内存中拿出东西也是一样,有这些步骤。
那么接下来问题就来了,数据结构到底是什么?是玄学吗?是魔法吗? 都不是 就像生活中要收拾自己的东西一样,我们知道数据是对于我们有用的值,单元是存储数据的容器,并且这些容器还是有限的,那么怎么有效的利用这些容器,存储数据就是我们接下考虑的问题。故而我认为 数据结构是组织管理数据的有效方式
数组
就像我们在超市中看到的那样,数组就是连续的容器,连续的很多的容器,只要知道第一个的地址然后知道有多少个容器就可以很快找到每个容器。但是这种方式有一个弊端,就是必须要实现固定容器的大小,并且要事先知道我们要存多少个。但是事先知道也不行,比如我最大要存一千个数,但是绝大多数情况下我们只用到20个。试问到底怎么办呐?是分配多少呀?这里扩展一下,计算机的内存是十分宝贵的,我们要尽可能的减少一个程序对于内存的占用,所以对于一个经常使用长度为20的数组,但是最大长度为i1000的数组,我们有两种解决方案:
1. 声明的时候声明长度为1000,这样的好处的数组是够用的,但是坏处是,绝大多数时候有980个空间是不被使用的,且别的程序也不能够使用,这无疑是很让人心疼的一件事。
2. 第二个解决方案,就是先声明20长度,够的时候在重新分配。这听上去很棒,但是事实并不是如此。这个需要我们了解内存的分配方式。
在内存中空间开辟是离散的!这句话的意思就是我们给你盒子的时候,是那个有空就给你那个,所以我给你数组的时候,不是说你像想在这个数组皮龟后面加东西就能加东西的,我只有重新分配一个数组空间,这个空间和上个空间差距很远,所以我需要把上个数组的东西拷贝过来,听起来就很麻烦是吧?事实也是这是一个非常麻烦的操作
链表
为了解决上述问题,我们聪明的前辈想出了新的解决方案,我们希望的是能够一个一个申请存储空间,但是这个存储空间是离散的,就像撒在桌子上的豆子一样,只要想办法串联其实就好了?自然用到了传说的指针,保存下一个位置的地址。基础篇
那么上面那个 问题我们怎么解决那?肯定你会说,不够的时候在加盒子呗?不错是种思路,但是有个问题,空间的分配是在程序运行之前,我们怎么做到运行的时候分配空间那? 而且我们分配多少合适那?分配的的内存如何管理那?于是聪明的前人想出了 一种方式叫做链表。链表的组成分为两块,一块是数据空间,用于数据存储,一块是地址空间用于表示下一个的存储空间的位置。就像我们的风铃一样,铃铛就是数据空间,然后指针就是我们的铁链,我们加一个铃铛就挂一个想想是不是特别方便那?接下来我们来看个
(void*)malloc(sizeof(type)*num);
这个语句可以程序运行时动态的申请内存,并且返回这个内存的指针type不是申请的容器的类型比如int bool啥的,num表示要申请的内存有多少块。
然后我们想像一个场景,我是一个学校的老师,需要统计我们学生的信息,用来存储,我们需要的信息有学生的学号,姓名,年龄,以及学院编号。我们如何设计? 没有一个现成的数据类型来包含这些,所以需要自定义一个结构体!使用struct Name{};来定义我们的结构体,然后typedef 可以重命名这个结构体
typedef struct studentsMessage{
char num[15];
int age;
char name[35];
}Students;这个结构体是使用StudentsMessage和Students都是可以得
StudentsMessage aStudents;
好的我们看到上面我们自己定义了一个数据结构来管理我们的学生,并且取名为student。但是我们信软学院嘛,学生数目不稳定,不知道傻逼的学院打算招多少人那?这个时候作为一个苦逼的程序员如何满足学院这个需求那?就用到了刚才说到的链表(其实有更加专业的工具——数据库)。我们用优化下这个结构,我们给加上指向下一个这个结构的指针
typedef struct studentsMessage{
char num[15];
int age;
char name[35];
struct studentsMessage* next;
}Students;next指向下一个这个结构的地址,所以我们的数据就用了如下的方式串联了起来。是不是很形象?只要我知道上一个节点的信息,我只要读取他的next我就可以知道他的下一个节点是啥? 就像这样
aStudent->next;
只要next不为空就说明有下一个数值,next说明就到底了。但是这样也会有随之而来的问题,那就这个结构很方便的可以知道下一个,但是不知道上一个节点?这个又咋办?于是有了双向链表
一个结构指向了下一个结构,这就是单向,然后我们在加入一个指针
typedef struct studentsMessage{
char num[15];
int age;
char name[35];
struct studentsMessage* next;
struct studentsMessage* pre;
}Students;这个就是图中的双向表,每个节点我们都指向了他的上一个节点。另外,为了能够链表到底之后能够很快的回到链表的头,有的链表将尾巴这个节点的next不是置为空,而是指向头,这那就是我们说的循环链表
操作篇
看了上面的介绍我们基本能明白链表的意思了?那么我们如何声明链表那?首先第一个问题如何生成一个节点,我们知道编译器在编译程序的时候会为了我们初始化简单的数据,但是复杂的数据编译器是怎么初始化的那?这个无疑是很让人疑惑的,并且还会便随着什么时候去初始化这个变量的问题,所以我们选择了自己去初始化。
Students* aStudent =(Students*)(malloc(sizeof(Students)));
这里就得到了一个指向学生这个结构的指针,我们初始化它一下:
aStudent->age=18; aStudent->next=null;
因为没有下一个节点,我们把说下一个指向null;
要是再有一个节点那? 这个就是我们把链表串联起来的操作
`Students* aStudentT =(Students*)(malloc(sizeof(Students)));` `aStudentT->next=aStudent`
既然创建了链表的节点,并且能够将链表连接起来了,接下类就是要思考如何遍历链表的问题,回忆下链表的结构是一个数据位和一个指针位。每个指针指向了下一个节点的地址,然后下一个节点里面包含了一个指针位,又存着下一个节点的指针地址,所以只要拿着一个节点的指针,就能找到下一个节点。所以结果出来了,可以用一个循环,只要节点的指针不为空(我们规定没有下一个节点的链表节点指针设置为空),就一直查找下去代码如下:
Students* TargetNode=Head;//head 为传入的参数
while(TargetNode->next) //检测是否到末尾
{
TargetNode=TargetNode->next; //取出下一个节点 赋值给当前节点
}能够遍历整个链表了自然需要学习查找,毕竟遍历是查找的基础,如下代码找到特定位置的链表。当然传入的也可以不是第那个位置的表,也可以是数据位的数值,比较是否相等
Students* getLinkNode(int index,Students* head)
{
Students* temp=head;
int i=0;
while(i<index)
{
if(temp->next)
{
temp=temp->next;
}
else
{
return null;
}
}
return temp;}上面的程序就是只要没有到底(if(temp->next)) 的判断就为真(因为我们链表的底为空指针)那么就继续往下查找,temp=temp->next; 这里做的就是把下一个位置的地址赋值给当前链表,然后是关于插入数值的操作,我们要在x位置插入一个节点node
false InsterNode(int index,Students* node ,Students head)
{
Students* temp=head;
int tempNum;
for(tempNum=0;tempNum<index-1;tempNum++)
{
if(temp->next)
{
temp=temp->next;
}else{
return false;
}
}
node->next=temp->next;
temp->next=node;
return true;
}来看这段程序,node为要能插入的节点,head为表头,要插入到index个位置,要怎么做?想想这个逻辑,首先找到index的前一个,也就是index-1;这个即使for循环做的事情,然后我们用node的next指向index这个位置,然后用temp(index-1位置)这个节点的next指向node是不是就串了起来?形象的表示,如图所示:
这两张图都是形象的表示链表插入的图片,叉表示对就是代码中的操作,改变记录的链接操作
node->next=temp->next; temp->next=node;
再插入和遍历查找都练习了一遍之后,自然而然便会想到,应该如何删除链表的某个节点?回忆一下链表的形样子,联想上面的图,删除特定节点这个事情简单的分解一下,就是首先要找到这个节点,然后将节点移除。如何移除那?看看下图的一个节点,19号节点要移除出这个链表是不是要先找到19号节点,然后拿到19号的前一个以及下一个节点的信息,把上一号节点的next指针指向19号的下一个节点,把19号的next指针置为空。这样19号与链表的联系就断开了。
正如上图形象的描述那样,B节点就离开了整个链表。来结合前面的代码,思考下这段代码如何实现,tips:
首先找到这个节点和这个节点的前一个节点(因为这个节点只包含其下一个节点的指针。)
讲这个节点前一个节点(用A表示)的next指向其下一个节点,然后当前节点next指针置为空。
代码如下:
bool DeleteNode(Students* HeadNode,int Index)
{
Students* PreNodes,*Target; //用于存储前一个节点和当前节点
int i=0;
Target=HeadNode;
//查找
for(i=1;i<index;i++) //遍历到index位置,只要i还小于index就说明没到,这里注意是从一开始就是正常的计数
{
if(Target->next) // 这里是保证没有遍历到链表的尾巴,有可能用户输入错误,index比链表还长
{
PreNodes=Target; //
Target=Target->next;
}else
{
break;
}
}
if (i!=index) //如果不想等,说嘛提前到了链表结尾,查找失败
{
/* code */
return false;
}
//z执行的删除操作
PreNodes->next=Target->next;
Target->next=null;
free(Target);
return true;
}好了关于链表的基础操作就基本完了,任何的复杂功能都逃不出这几个简单功能。在复杂的链表也是要有一个函数负责创建,一个函数负责讲节点加入当前链表,一个函数查找,一个函数负责找到之后的操作,接着就是删除。希望对你有所帮助
Copyright 2016 CloudGuan ,Inc.All Rights Reserved.

相关文章推荐
- 第14章 数据结构扩张 区间树部分代码
- 数据结构/算法 - 桶排序
- 第十四章 数据结构扩张 动态顺序统计部分代码
- 《数据结构》2.3求两个递增链表的交集
- 数据结构(RMQ):POJ 3624 Balanced Lineup
- uva 11997——K Smallest Sums
- uva 1203—— Argus
- 数据结构和二叉树操作的封装
- 【数据结构与算法】(五) c 语言递归与汉诺塔实现
- 数据结构术语和概念的明确
- 数据结构入门
- Java数据结构笔记2——数组线性表类(ArrayList)
- JAVA数据结构---循环队列
- JAVA数据结构---循环队列
- JAVA数据结构---循环队列
- JAVA数据结构---循环队列
- JAVA数据结构---循环队列
- JAVA数据结构---循环队列
- JAVA数据结构---循环队列
- JAVA数据结构---循环队列