TinyHttp-最简单的Web Server浅析
2016-03-13 22:52
381 查看
-This file is unterstanding the work method of Web Server -The example is TinyHttp and I give some notes
Overview
main()–>
startup()–>
accept_request()–>
execute_cgi()
Main senario:

Establish a web server step
建立连接– accept connection from client
Accept request – 读取一条HTTP报文
Handle request – 解释报文,采取行动
访问资源 – 访问报文中指定的资源
构建报文 – 创建带有正确HTTP首部的报文
发送响应 – give the response to client
记录事务处理过程 – record the step into log <– No such info in TinyHttp
Create connection
如果client已经打开了持久链接,那么可以复用,否则客户端可以打开一条新连接。Web服务器会将新连接添加到现存的Web服务器列表中,做好监视链接上传数据的准备。
Web server可以随意拒绝or立即关闭任意一条链接<==?? How, Need to check Nginx/APV/..??
客户端主机名识别–会降低性能。So many server close this function or permit it in some special cases.
Accept request message
解析请求行,查找请求方法、指定的资源标识符以及版本号,各项之间以一个空格分隔,并且以一个CRLF \r作为行的结束读取以 CRLF 结尾的报文首部
检测到以CRLF结尾的、标识首部结束的空行(如果有的话)
长度由content-length决定
eg:
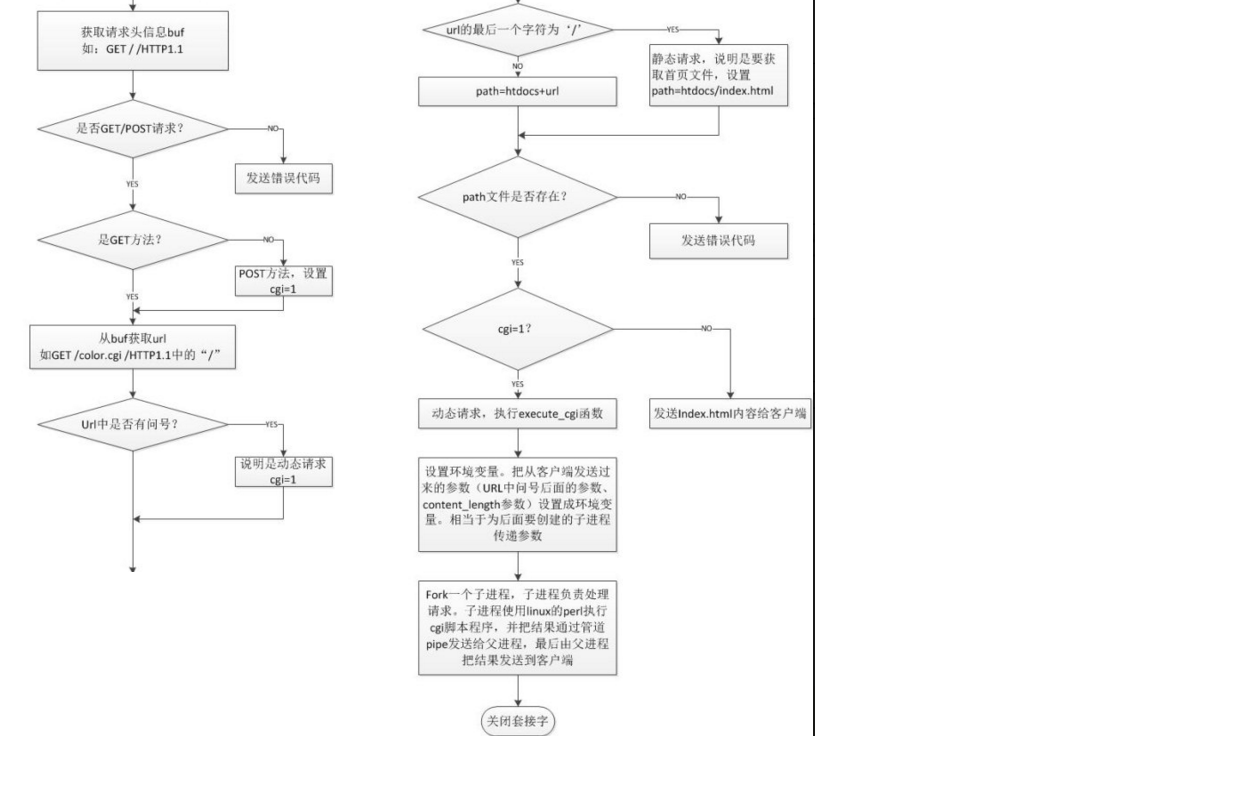
TinyHttp采用多线程模型,没有使用复用IO模型,收到一个请求时,即listenning port get accept request,generate a thread to run accept_request function
int main(void):
/*建立socket,监听端口*/
++server_sock = startup(&port);
++while (1):
|__client_sock = accept(server_sock,
(struct sockaddr *)&client_name,
&client_name_len);/*recieve request message*/
|__if (pthread_create(&newthread , NULL, accept_request, (void*)client_sock) != 0):
perror("pthread_create");/* accept_request(client_sock),child thread to handle request*/
//close
++close(server_sock);
++return(0);注意:pthread_create 第二个参数回调函数也要求是void* func(void*)三个参数是(void*) ,后面 void* accept_request(void* thread_arg) client_sock 作为参数传进来,用的时候要: int client = (int)client_sock /*对参数的读取放在get_line()里很关键一点要理解get_line的意思。 * 我们要知道当在浏览器中输入url后enter之后,它发给服务器是文本型的字符串, * 遵循http请求格式,类似下面的: * GET / HTTP/1.1 * HOST:www.abc.com * Content-type:text/html *... * get_line干的事就是读取一行,并且不管原来是以\n还是\r\n结束,均转化为以\n再加\0字符结束。其实现如下:*/
int get_line(int sock, char* buf, int size)
{
int i = 0;
int rcv_num = 0;
char c = '\0'; /*recieve one character each time*/
/*consider \r\n*/
while((i<size-1) && (c != '\n')) {
rcv_num = recv(sock, &c, 1, 0);
if (rcv_num > 0) {
if (c=='\r') {/*收到 \r 则继续接收下个字节,因为换行符可能是 \r\n*/
/*use MSG_PEEK to keep window unmoved, next recv read the same character*/
rcv_num = recv(sock, &c, 1, MSG_PEEK);
if ((rcv_num > 0) && (c == '\n'))
rcv_num = recv(sock, &c, 1, 0);/*this time,use '\n' to replace '\r\n' to put in 'c'*/
else
c = '\n'
}
buf[i] = c; /*assign recved value to buf */
i++;
} else {
c = '\n'
}
buf[i] = '\0';
}
return i;
}Handle request
一旦收到请求,就可以根据方法、资源、首部和可选的主体部分来对请求进行处理,比如POST,要求请求报文中必须带有实体主体部分主要处理逻辑在accept_request()
对资源的映射以及访问
通常,web server文件系统会有一个专门的文件夹来存放Web内容,这个文件夹通常被称为 root根目录。web 服务器从请求中获取uri,并将其附加到文档根目录后面。动态内容资源映射–映射到按需动态生成内容的程序上去,Web server要可以分辨出资源什么时候是动态的,动态内容生成程序位于何处
参见accept_request 程序:
eg:
浏览器里输入127.0.0.1:37776–
numchars = get_line(client, buf,sizeof(buf));/*get each line*/
gdb 中看 $2 = “GET / HTTP/1.1\n”, ‘\000’
–> url is /
–> path is
htdocs/
–> path is
htdocs/index.html,如果不输入路径的话,那么就从htdocs找,这是默认的根目录
–>
if ((st.st_mode & S_IFMT) == S_IFDIR) /*dir in request*/
–>
strcat(path, "/index.html");目录的话,再找index.html
–> 找 是否需要走cgi 处理 CGI:通用网关接口(Common Gateway Interface)
代码
void* accept_request(void* thread_arg)
{
char buf[1024];
int numchars;
char method[255];/*GET or POST*/
char url[255]; /*path, eg:GET /color.cgi?color=red ==>/color.cgi*/
char path[512];
size_t i,j;
struct stat st;
int cgi = 0; /* becomes true if server decides this is a CGI */
char *query_string = NULL; /*para info of GET method eg: GET /color.cgi?color=red ==> color=red */
int client = (int)thread_arg;
numchars = get_line(client, buf,sizeof(buf));/*get each line*/
if (numchars == 0) {
printf("No header exsited\n");
/* error_die("get_line");*/
}
i = j = 0;
/*Get method string*/
while(!IS_SPACE(buf[j]) && (i < sizeof(method)-1)) {
method[i++] = buf[j++];
}
method[i] = '\0';
/*The method can not work*/
if (strcasecmp(method, "GET") && strcasecmp(method, "POST")) {
unimplemented(client);
return NULL;
}
if (strcasecmp(method, "POST") == 0)
cgi = 1;
i = 0;
/*Get url*/
while(IS_SPACE(buf[j]) && (j<sizeof(buf))) {
j++;
}
while(!IS_SPACE(buf[j]) && (j<sizeof(buf)) && (i<sizeof(url)-1)) {
url[i++] = buf[j++];
}
url[i] = '\0';
if (strcasecmp(method, "GET") == 0) {
query_string = url;
/*if there is '?', it's indicate that para after '?' ,it's dynamic request*/
while((*query_string != '?') && (*query_string != '\0'))
query_string++;
if (*query_string == '?') { GET /color.cgi?color=red
*query_string = '\0'; /* discard the content after '?' */
query_string++; /*query string is pointing to the para of dynamic request*/
cgi = 1; <==query_string 指向 color=red
}
}
/*get the path of request file*/
sprintf(path, "htdocs%s", url);
int last = strlen(path)-1;
if (path[last] == '/')
strcat(path, "index.html");
/*no such file, return not frond*/
if (stat(path, &st) == -1) {
// 读header
while (numchars>0 && strcmp(buf,"\n"))
numchars = get_line(client, buf, sizeof(buf));
not_found(client);
} else {
/*find it*/
if ((st.st_mode & S_IFMT) == S_IFDIR) /*dir in request*/
strcat(path, "/index.html");
/*check the file permissions, if can be executed, then go to cgi*/
if ((st.st_mode & S_IXOTH) || (st.st_mode & S_IXGRP) || (st.st_mode & S_IXUSR))
cgi = 1;
if (!cgi) /*static page request*/
serve_file(client, path); -- 执行 htdocs/index.html
else /*dynamic*/
execute_cgi(client, path, method, query_string);
}
close(client);}
构建响应:
一旦识别出了资源,就执行请求方法中描述的动作,并返回响应报文。响应报文中包括响应码,响应首部,还可能有响应主体以tinyhttp为例,如果文件路径合法,对于无参数的 GET 请求,直接输出服务器文件到浏览器,即用 HTTP 格式写到套接字上,跳到(10)。其他情况(带参数 GET,POST 方式,url 为可执行文件),则调用 excute_cgi 函数执行 cgi 脚本。
cgi 介绍, 服务器和客户端之间的通信,是客户端的浏览器和服务器端的http服务器之间的HTTP通信,我们只需要知道浏览器请求执行服务器上哪个CGI程序就可以了,其他不必深究细节,因为这些过程不需要程序员去操作。一般情况下,服务器和CGI程序之间是通过标准输入输出来进行数据传递的,而这个过程需要环境变量的协作方可实现。
服务器将URL指向一个应用程序
服务器为应用程序执行做准备
应用程序执行,读取标准输入和有关环境变量
应用程序进行标准输出
参考: http://www.cnblogs.com/lele/articles/3564327.html
static 响应:
返回index.html页面 – 读取header并丢弃
1: buf = "Host: 127.0.0.1:37776\n", '\000' <repeats 402 times>... (gdb) n 253 1: buf = "User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:41.0) Gecko/20100101 Firefox/41.0\n", '\000' <repeats 337 times>... 1: buf = "User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:41.0) Gecko/20100101 Firefox/41.0\n", '\000' <repeats 337 times>... 1: buf = "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\n\000 Firefox/41.0\n", '\000' <repeats 337 times>... 1: buf = "Accept-Language: en-US,en;q=0.5\n\000ml+xml,application/xml;q=0.9,*/*;q=0.8\n\000 Firefox/41.0\n", '\000' <repeats 337 times>... buf = "Connection: keep-alive\n\000eflate\n\000\000ml+xml,application/xml;q=0.9,*/*;q=0.8\n\000 Firefox/41.0\n", '\000' <repeats 337 times>...
2. 发送headers:
strcpy(buf, "HTTP/1.0 200 OK\r\n"); send(client, buf, strlen(buf), 0); strcpy(buf, SERVER_STRING); send(client, buf, strlen(buf), 0); strcpy(buf, "Content-Type:text/html\r\n"); send(client, buf, strlen(buf), 0); strcpy(buf, "\r\n"); send(client, buf, strlen(buf), 0);
3. 发送index.html
void cat (int client, FILE* resource)
{
char buf[1024];
fgets(buf, sizeof(buf), resource); /*fgets read one line once time*/
while(!feof(resource)) {
send(client, buf, strlen(buf), 0);
fgets(buf, sizeof(buf), resource);
}
}4. 走到主页,html格式 <FORM ACTION="color.cgi" METHOD="POST"> Enter a color: <INPUT TYPE="text" NAME="color"> <INPUT TYPE="submit"> 5. 再输入color会走到动态调用,通过index.html 调用color.cgi, 然后把execute cgi
dynamic 响应:
(gdb) p method
$10 = “POST”, ‘\000’ url is /color.cgi
回一个200:OK
buf = "HTTP/1.0 200 OK \r\n\000cation/x-www-form-urlencoded\n\000on/xml;q=0.9,*/*;q=0.8\n\000 Firefox/41.0\n", '\000' <repeats 665 times>...
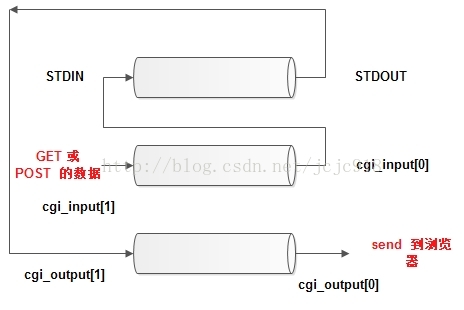
create pipe, dup.父进程读取请求(点击submit后,实际上时
color=red),写出到
cgi_input[0](
cgi_input[0]和STDIN共用一个描述符),作为cgi程序的输入.
子进程设置好环境变量REQUEST_METHOD=POST. CONTENT_LENGTH = 11 – STDIO中的有效信息长度, then
execl(path, path, NULL);
如下图:
cgi_input[1]负责POST时的写入,如果浏览器直接127.0.0.1:37776/color.cgi,那么不会有这一步,只是cgi的程序输出到STDOUT,和
cgi_output[1]共享 – >
cgi_output[0]–> recv() –> 浏览器
code:
void execute_cgi(int client, const char *path, const char *method, const char *query_string)
{
char buf[1024];
int cgi_output[2];
int cgi_input[2];
pid_t pid;
int status;/*for waitpid*/
int i;
char c;/*for recieve single character*/
int numchars = 1;
int content_length = -1;
buf[0] = 'A';
buf[1] = '\0'; /*why*/
/*read and discard headers for "GET"*/
if (strcasecmp(method, "GET") == 0) {
while((numchars > 0) && strcmp("\n", buf))
numchars = get_line(client, buf, sizeof(buf));
} else {
/*POST, find content_length*/
numchars = get_line(client, buf, sizeof(buf));
while ((numchars > 0) && strcmp("\n", buf)) {
/*use '\0' to split, the buf like this : Content-Length*/
buf[15] = '\0';
/*each line*/
if (strcasecmp(buf, "Content-Length:") == 0)
content_length = atoi(&buf[16]);/*eg: Content-Length:25, 25 is pointting to*/
numchars = get_line(client, buf, sizeof(buf));
}
if (content_length == -1) {/*no change*/
bad_request(client);
return;
}
}
sprintf(buf, "HTTP/1.0 200 OK \r\n");
send(client, buf, strlen(buf),0);
// create pipe
if (pipe(cgi_output)<0) {
// 500 internal server error
cannot_execute(client);
return;
}
if (pipe(cgi_input)<0) {
// 500 internal server error
cannot_execute(client);
return;
}
if ((pid = fork())<0) {
cannot_execute(client);
return;
}
if (pid == 0) {
/*child process, child: CGI script*/
char meth_env[255];
char query_env[255];
char length_env[255];
/*pipe read and write*/
dup2(cgi_output[1], STDOUT_FILENO);
dup2(cgi_input[0], STDIN_FILENO);
close(cgi_output[0]);
close(cgi_input[1]);
sprintf(meth_env,"REQUEST_METHOD=%s",method);
putenv(meth_env);
if (strcasecmp(method, "GET") == 0) {
sprintf(query_env, "QUERY_STRING=%s",query_string);
putenv(query_env);
} else {
/*POST*/
sprintf(query_env, "CONTENT_LENGTH=%d",content_length);
putenv(query_env);
}
/*run cgi*/
execl(path, path, NULL)
exit(0);
} else {
/*parent process*/
close(cgi_output[1]);
close(cgi_input[0]);
if (strcasecmp(method, "POST") == 0) {
for (i=0; i<content_length; i++) {
recv(client, &c, 1, 0);
/*data of POST write to cgi_input[1] --> STDIN*/
if (1 != write(cgi_input[1], &c, 1)) {
printf("%c",c);
error_die("write");
}
}
}
/*send data to browser*/
while(read(cgi_output[0], &c, 1)) {
send(client, &c, 1, 0);
}
close(cgi_output[0]);
close(cgi_input[1]);
waitpid(pid, &status, 0);
}
}遗留问题:
tinyhttpd 一样使用线程模型的吗?有考虑或者测试过某个线程异常退出然后会发生什么吗?
—因为在linux环境下一个线程异常退出,整个进程都会退出,所以 nginx 和 Apache 才都使用进程模型(windows 下不存在这个问题,所以windows下 Apache 使用多进程+多线程)
如果 client 端大量连接server,只连接不通信,你的 server 会不停地创建新的线程响应新的连接吗?
—第二个问题是同步多进程/线程模型服务器的一个问题,消耗资源大, 所以最好考虑设定最大并发数
http/0.9、http/1.0、http/1.1 请求是否都能得到正确的返回?http/1.1 中的 expect 请求呢?chunck?gzip?是否都可以得到正确的返回?是否支持 https?
如果 CGI 执行时间过长是否会导致线程阻塞?
没有更改当前工作目录,如果不是在当前目录启动,则服务器将找不到对应的资源目录,当然,代码中使用相对路径是相同弊病 – How
没有将运行、通信情况记入 log,这样对于以往的服务器工作状况、通信状况,我们将无从得知
没有对拒绝服务攻击做出处理,即便不是拒绝服务攻击,仅仅是连接数目过多都会使服务器线程开辟过多而占用过多资源,这一点如果换成 IO 复用模型可以得到一定的改善
参考资料:
http://blog.csdn.net/baiwfg2/article/details/45582723
http://blog.csdn.net/earbao/article/details/16342825
http://my.oschina.net/u/2313065/blog/483912
http://www.myext.cn/other/a_32407.html

相关文章推荐
- java-WEB中的监听器Lisener
- GUI - Web前端开发框架
- Extjs4.0 最新最全视频教程
- MyEclipse Web Project转Eclipse Dynamic Web Project
- axis备忘
- Erlang实现的一个Web服务器代码实例
- 防止网页脚本病毒执行的方法-from web
- 自学成才的秘密:115个 web Develop 资源
- 使用批处理修改web打印设置笔记 适用于IE
- Apache Web让JSP“动”起来
- web下载的ActiveX控件自动更新
- 推荐六款WEB上传组件性能测试与比较第1/10页
- 关于三种主流WEB架构的思考
- 使用 Iisext.vbs 列出 Web 服务扩展文件的方法
- 使用 Iisext.vbs 删除 Web 服务扩展文件的方法
- 使用 iisext.vbs 禁用 Web 服务扩展的方法
- 用vbs 实现从剪贴板中抓取一个 URL 然后在浏览器中打开该 Web 站点
- web标准知识——从p开始,循序渐进
- web标准知识――用途相似的标签
- ajax与传统web开发的异同点