动态规划(一)
2016-03-12 15:58
489 查看
最优化问题
一般优化问题描述
随机动态规划的结构
离散时间系统
离散时间系统代价函数
反馈
第一个栗子随机动态优化问题
第二个栗子确定动态优化问题
第三个栗子来点复杂的无线网络问题
小结
比较权威的参考资料:Dimiri P. Bertsekas, Dynamic Programming and Optimal Control, 3rd ed., Athena Scientific, Belmont, Massachusetts,2005
u 是最优化问题的决策
g(u) 是决策的代价函数
U 是所有决策 ui 的集合
动态规划的优化问题可以分为:
随机优化问题:
由于代价函数存在一个随机变量w,因此最优解的优化目标是代价函数的统计平均。
g(u)=EwG(u,w)
确定优化问题:
这个问题代价函数是一个确定函数。
如何区分这两个问题呢?我们可以观察系统是否存在随机性,这个随机性是体现在系统之中的,而不是这个系统。举个栗子,优化一个随机网络是个确定性问题,即给定任意网络结构,找到最短路径,因为网络虽然是随机的,但是优化的目标在确定以后是不变的。然而优化一个随时变化的网络是一个随机问题,即一边进行优化,网络结构一边在变的问题。
动态规划正是可以解决每一个步骤都有随机变量 w 影响的目标函数,如何在全局取得统计平均上最优解的问题。后面我们可以看到每一个决策都会利用 w 的信息。
其中:
k :表示离散时间(也可以看作是步骤)。
xk :表示在时间 k 的状态,该状态具有马尔科夫性,即当前状态已经包含决策所需要的各种信息,与之前的状态无关。当前状态将会参与决策。
uk :表示在时间 k 所输出的控制,即再时间 k 在集合 U 中选择的控制信息。
wk :是一个随机变量,这个随机变量将会影响代价函数。
N :表示控制的窗口时间。
我们的优化目标就是优化这个系统的平均代价。可以看到这个代价是每一个决策的代价和最终状态代价的统计平均。
动态规划除了可以分为随机动态规划和确定动态规划,还可以分为带反馈和不带反馈(feed back)。也有人叫做开环(open-loop)和闭环(closed-loop)。这个命名可能会导致我们理解错误。因为,反馈并不是指的前一级对后一级的反馈,而是当前状态xk根据wk得出的uk导致的状态跳转。如图:
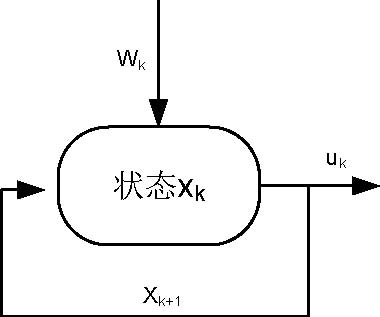
可见反馈真正的意义是,根据现在的状态以及信息wk做决策做决策,并记录这个过程的状态跳转。
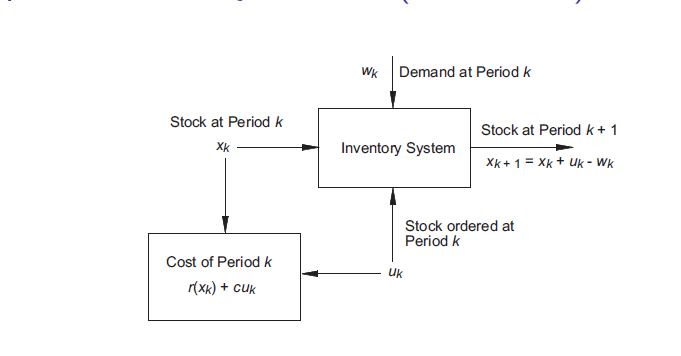
这个离散时间系统就可以描述为:
xk+1 = fk(xk,uk,wk) = xk+uk−wk
其代价函数会随着时间叠加,所以这个系统的代价函数为:
E{∑k=0N−1(cuk+r(xk))+R(xN)}
我们可以看到每一个周期其代价都会叠加,到最后会有一个最终状态的代价(为什么有这个代价呢?不妨假设没有这个代价,在第N−2个周期我们进货量为正无穷,定能满足需求。但是这明显是不合理的。)
1. A必须在B之前执行,C必须在D之前执行
2. 必须从A和C开始,即起始状态必须为:SA或者SC
3. 状态 m 到 n 的跳转代价是 Cmn
则可以画出一个类似二叉树的图:
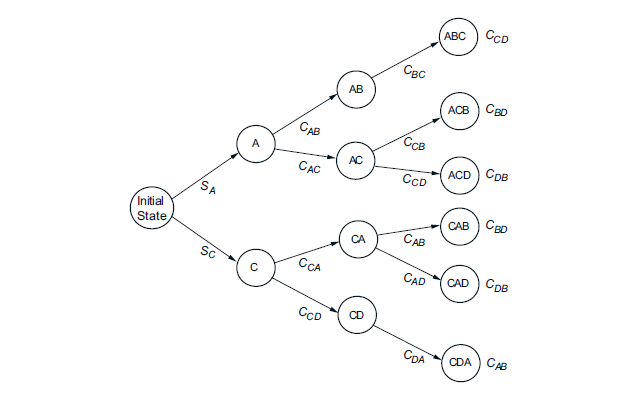
显然只需要遍历整个图我们即可找到一个最优解。
1. 信道条件有两种:好的(概率为:p),坏的(概率为: 1−p )
2. 在好的和坏的信道下面都可以传包,不同信道条件下传包的代价不同。好信道的代价为 PG 。坏的信道的代价为 PB
3. N 个发送时隙完毕后,最后剩余 m 个数据包的代价为 C(m)
下面我们根据已知的知识对系统建模:
系统状态: (mk,Hk) : mk 表示剩余数据包的数量, Hk 表示信道条件。
控制信息: uk 有两个取值,0(表示不发送),1(表示发送)。
随机变量 w :表示信道变化
系统描述:mk+1=mk−uk,Hk+1=wk
开销函数:
E{∑k=0N−1g((mk,Hk),uk)+C(mN)}
问题解答见:http://blog.csdn.net/sylar_d/article/details/50900521
1. 控制是局部的,仅仅取决于当前的状态xk
2. 状态具有马尔科夫性。
3. 动态规划系统具有以下特性:
系统描述: xk+1=fk(xk,uk,wk),k=0,1,…,N−1
控制约束: uk∈U(xk)
随机概率分布: Pk(wk)=Pk(⋅|xk,uk)
策略:有一系列的策略 π={μ0,…,μN−1} 其中每一个 μk 都将状态 xk 按照映射 uk=μk(xk) 映射成为一个决策。
代价函数:从x0开始的策略 π 的代价函数为:
Jπ(x0)=E{∑k=0N−1gk(xk,μk(xk),wk)+gN(xN)}
最优策略:
J∗(x0)=minπJπ(x0)
最优策略 π∗ 必须满足:
Jπ∗(x0)=J∗(x0)
一般优化问题描述
随机动态规划的结构
离散时间系统
离散时间系统代价函数
反馈
第一个栗子随机动态优化问题
第二个栗子确定动态优化问题
第三个栗子来点复杂的无线网络问题
小结
最优化问题
动态规划(Dynamic programming)是用来优化一个随机问题的最优解,随机问题是只我们优化的目标是随机的,最优解指的是在统计平均上的最优。比较权威的参考资料:Dimiri P. Bertsekas, Dynamic Programming and Optimal Control, 3rd ed., Athena Scientific, Belmont, Massachusetts,2005
一般优化问题描述
minu∈Ug(u)u 是最优化问题的决策
g(u) 是决策的代价函数
U 是所有决策 ui 的集合
动态规划的优化问题可以分为:
随机优化问题:
由于代价函数存在一个随机变量w,因此最优解的优化目标是代价函数的统计平均。
g(u)=EwG(u,w)
确定优化问题:
这个问题代价函数是一个确定函数。
如何区分这两个问题呢?我们可以观察系统是否存在随机性,这个随机性是体现在系统之中的,而不是这个系统。举个栗子,优化一个随机网络是个确定性问题,即给定任意网络结构,找到最短路径,因为网络虽然是随机的,但是优化的目标在确定以后是不变的。然而优化一个随时变化的网络是一个随机问题,即一边进行优化,网络结构一边在变的问题。
动态规划正是可以解决每一个步骤都有随机变量 w 影响的目标函数,如何在全局取得统计平均上最优解的问题。后面我们可以看到每一个决策都会利用 w 的信息。
随机动态规划的结构
离散时间系统
xk+1=fk(xk,uk,wk),k=0,1,…,N−1其中:
k :表示离散时间(也可以看作是步骤)。
xk :表示在时间 k 的状态,该状态具有马尔科夫性,即当前状态已经包含决策所需要的各种信息,与之前的状态无关。当前状态将会参与决策。
uk :表示在时间 k 所输出的控制,即再时间 k 在集合 U 中选择的控制信息。
wk :是一个随机变量,这个随机变量将会影响代价函数。
N :表示控制的窗口时间。
离散时间系统代价函数
E{∑k=0N−1gk(xk,uk,wk) + gN(xN)}我们的优化目标就是优化这个系统的平均代价。可以看到这个代价是每一个决策的代价和最终状态代价的统计平均。
反馈
前面描述了动态规划的目的,动态规划为了优化一个随机函数。它的解是平均意义上的最优,并非每次都是最优。动态规划问题可以分为随机优化问题以及确定优化问题。其中确定优化问题可以每次都取得最优解(算法导论上面介绍的就是确定优化问题,这只是动态优化的冰山一角!)。动态规划除了可以分为随机动态规划和确定动态规划,还可以分为带反馈和不带反馈(feed back)。也有人叫做开环(open-loop)和闭环(closed-loop)。这个命名可能会导致我们理解错误。因为,反馈并不是指的前一级对后一级的反馈,而是当前状态xk根据wk得出的uk导致的状态跳转。如图:
可见反馈真正的意义是,根据现在的状态以及信息wk做决策做决策,并记录这个过程的状态跳转。
第一个栗子:随机动态优化问题
假设系统是一个零售商的进货系统,进货是周期性的。假设一个周期需求是 wk 显然需求是一个随机变量,库存是 xk ,同时也表示这个系统的状态。我们的进货量 uk 也就是我们的决策。所以每一次周期完毕后的库存可以表示为xk+1 = xk+uk−wk。因此我们可以建立如下模型:这个离散时间系统就可以描述为:
xk+1 = fk(xk,uk,wk) = xk+uk−wk
其代价函数会随着时间叠加,所以这个系统的代价函数为:
E{∑k=0N−1(cuk+r(xk))+R(xN)}
我们可以看到每一个周期其代价都会叠加,到最后会有一个最终状态的代价(为什么有这个代价呢?不妨假设没有这个代价,在第N−2个周期我们进货量为正无穷,定能满足需求。但是这明显是不合理的。)
第二个栗子:确定动态优化问题
确定一个确定系统操作顺序问题:我们要找到A,B,C,D的最佳操作顺序。其中有几个限制:1. A必须在B之前执行,C必须在D之前执行
2. 必须从A和C开始,即起始状态必须为:SA或者SC
3. 状态 m 到 n 的跳转代价是 Cmn
则可以画出一个类似二叉树的图:
显然只需要遍历整个图我们即可找到一个最优解。
第三个栗子:来点复杂的无线网络问题
系统描述:我们需要在 N 个时隙中发送 M 个数据包,其中有几个限制:1. 信道条件有两种:好的(概率为:p),坏的(概率为: 1−p )
2. 在好的和坏的信道下面都可以传包,不同信道条件下传包的代价不同。好信道的代价为 PG 。坏的信道的代价为 PB
3. N 个发送时隙完毕后,最后剩余 m 个数据包的代价为 C(m)
下面我们根据已知的知识对系统建模:
系统状态: (mk,Hk) : mk 表示剩余数据包的数量, Hk 表示信道条件。
控制信息: uk 有两个取值,0(表示不发送),1(表示发送)。
随机变量 w :表示信道变化
系统描述:mk+1=mk−uk,Hk+1=wk
开销函数:
E{∑k=0N−1g((mk,Hk),uk)+C(mN)}
问题解答见:http://blog.csdn.net/sylar_d/article/details/50900521
小结
经过以上栗子我们看出,动态规划问题具有以下几点特性:1. 控制是局部的,仅仅取决于当前的状态xk
2. 状态具有马尔科夫性。
3. 动态规划系统具有以下特性:
系统描述: xk+1=fk(xk,uk,wk),k=0,1,…,N−1
控制约束: uk∈U(xk)
随机概率分布: Pk(wk)=Pk(⋅|xk,uk)
策略:有一系列的策略 π={μ0,…,μN−1} 其中每一个 μk 都将状态 xk 按照映射 uk=μk(xk) 映射成为一个决策。
代价函数:从x0开始的策略 π 的代价函数为:
Jπ(x0)=E{∑k=0N−1gk(xk,μk(xk),wk)+gN(xN)}
最优策略:
J∗(x0)=minπJπ(x0)
最优策略 π∗ 必须满足:
Jπ∗(x0)=J∗(x0)
