数据结构总结(6)
2016-03-02 17:18
435 查看
树(一对多)
{
树的定义(递归):
树(Tree)是n(n≥0)个结点的有限集,它或为空树(n = 0);或为非空树,对于非空树T:
(1)有且仅有一个称之为根的结点;
(2)除根结点以外的其余结点可分为m(m>0)个互不相交的有限集T1, T2, …, Tm, 其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
树的一般表示:
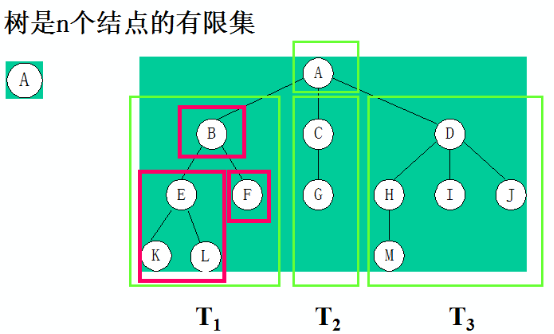
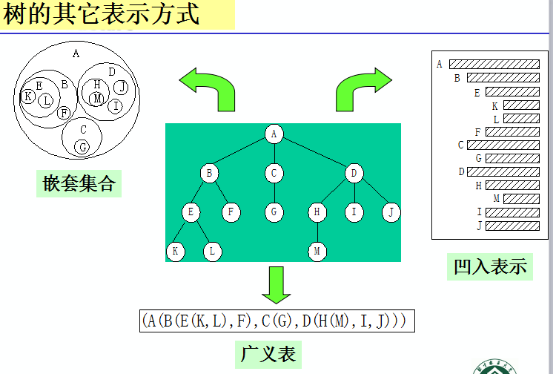
树的其它表示(三种)
基本术语1
根--------------根结点(无前驱)
叶子-----------终端结点(没有后继)
森林-----------指m课不相交的数的集合
有序树--------结点各子树从左到右有序,不能互换(二叉树)
无序树--------结点的各子树可互换位置。
双亲-----------即上层的那个结点(直接前驱)
孩子-----------即下层结点的子树的根(直接后继)
兄弟-----------同一双亲下的同层结点(孩子之间互称兄弟)
堂兄弟--------即双亲位于同一层的结点(并非同一双亲)
祖先-----------即从根到该结点所经分支的所有结点
子孙-----------即该结点下层子树中的任一结点
基本术语1
结点-----------即树的数据元素
结点的度-----结点挂接的子树数
结点的层次--从根的该结点的层数(根结点算第一层)
终端结点-----即度为0的结点,即叶子
分支结点-----即度不为0的结点(也称为内部结点)
树的度--------所有结点度中的最大值
树的深度----指所有结点中的最大的层次(高度)
逻辑结构:
二叉树、树和森林
存储结构:
顺序存储树和链式存储树
}
二叉树(树的特殊化,有序树的一种)
{
二叉树的定义:
二叉树(Binary Tree)是n(n≥0)个结点所构成的集合,它或为空树(n = 0);或为 非空树,对于非空树T:
(1)有且仅有一个称之为根的结点;
(2)除根结点以外的其余结点分为两个互不相交的子集T1和T2,分别称为T的左子树
和右子树,且T1和T2本身又都是二叉树。
二叉树的基本特点:
(1)结点的度小于等于2.
(2)有序树(分左右子树)
二叉树与树的关系:
(1)二叉树是树的特殊化,是有序树的一种。
(2)所有的树都可以转化为唯一二叉树,不失一般性。
二叉树的性质
性质1:在二叉树的第i层至多有2^(i-1)个结点。
提问:第i层上至少有 个结点?
性质2:深度为k的二叉树至多有2^k-1个结点
提问:深度为k时至少有 个结点?
性质3: 对于任何一棵二叉树,若2度的结点数有n2个,则叶子数n0必定为n2+1 (即n0=n2+1)
*性质3由边和结点关系推出:n=n0+n1+n2;e=n-1=n1+2*n2;n0=n2+1;
特殊形态的二叉树
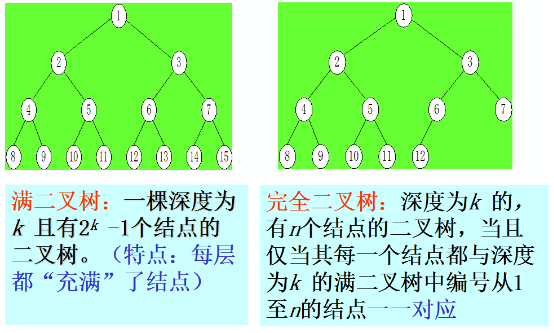
性质4: 具有n个结点的完全二叉树的深度必为[log2n]+1
性质5: 对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必为i/2。
二叉树的存储结构
}
二叉树的存储结构
{
顺序存储结构
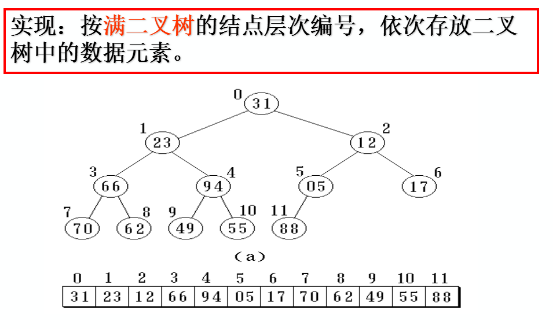
特点:
结点间关系蕴含在其存储位置中
浪费空间,适于存满二叉树和完全二叉树
二叉树的链式存储(左孩子右孩子)
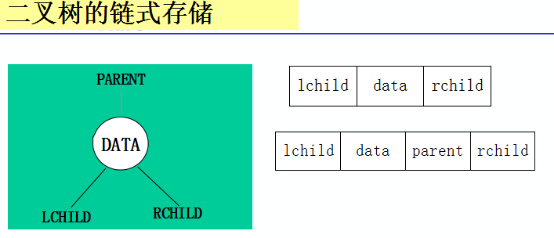
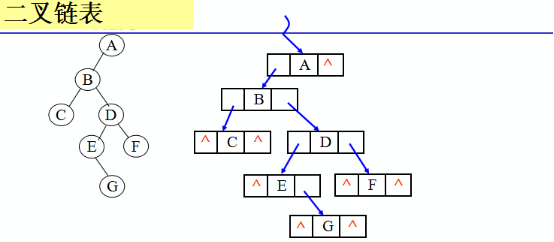
空指针数目=2n-(n-1)=n+1
二叉链表类型定义:
typedef struct BiNode{
TElemType data;
struct BiNode *lchild,*rchild; //左右孩子指针
}BiNode,*BiTree;
遍历二叉树和线索二叉树
{
遍历二叉树:
(1)先序遍历(前缀表示) 例:+ * * / A B C D E
(2)中序遍历(中缀表示) 例:A / B * C * D + E (数学一般的表达形式)
(3)后序遍历(后缀表示) 例:A B / C * D * E +
(4)层序遍历 例:+ * E * D / C A B
遍历算法(先序为例):
回忆
long Factorial ( long n ) {
if ( n == 0 ) return 1;//基本项
else return n * Factorial (n-1); //归纳项}
先序遍历(先序遍历建立二叉树)
Status PreOrderTraverse(BiTree T){
if(T==NULL) return OK; //空二叉树
else{
cout<<T->data; //访问根结点
PreOrderTraverse(T->lchild); //递归遍历左子树
PreOrderTraverse(T->rchild); //递归遍历右子树
}
}
void CreateBiTree(BiTree &T){
cin>>ch;
if (ch==’#’) T=NULL;
//递归结束,建空树
else{
T=new BiTNode; T->data=ch; //生成根结点
CreateBiTree(T->lchild); //递归创建左子树
CreateBiTree(T->rchild); //递归创建右子树
}
}
遍历算法分析
时间效率:O(n) //每个结点只访问一次
空间效率:O(n) //栈占用的最大辅助空间
线索二叉树 (利用二叉链树的n+1个空链域)

LTag :若 LTag=0, lchild域指向左孩子;
若 LTag=1, lchild域指向其前驱。
RTag :若 RTag=0, rchild域指向右孩子;
若 RTag=1, rchild域指向其后继。
哈夫曼树及其应用----最优二叉树
{
哈夫曼树的应用实例
{
哈夫曼编码(前缀编码)
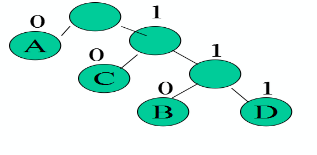
*左分支用“0”,右分支用“1”
待编码字符:ABACCDA
编码表:
A—0
B—110
C—10
D—111
原则:出现次数较多的字符采用尽可能短的编码,要设计长度不等的编码,则必须使任一字符的编码都不是另一个字符的编码的前缀-前缀编码
}
哈夫曼树
{
术语:
(1)路径:由一结点到另一个结点间的分支所构成
(2)路径长度:路径上的分支数目
(3)带权路径的长度:结点到根的路径长度与结点上权的乘积
(4)树的带权路径长度:树中所有叶子结点的带权路径长度之和
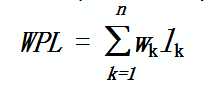
(5)哈夫曼树:带权路径长度最小的树
}
}
}
}
{
树的定义(递归):
树(Tree)是n(n≥0)个结点的有限集,它或为空树(n = 0);或为非空树,对于非空树T:
(1)有且仅有一个称之为根的结点;
(2)除根结点以外的其余结点可分为m(m>0)个互不相交的有限集T1, T2, …, Tm, 其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
树的一般表示:
树的其它表示(三种)
基本术语1
根--------------根结点(无前驱)
叶子-----------终端结点(没有后继)
森林-----------指m课不相交的数的集合
有序树--------结点各子树从左到右有序,不能互换(二叉树)
无序树--------结点的各子树可互换位置。
双亲-----------即上层的那个结点(直接前驱)
孩子-----------即下层结点的子树的根(直接后继)
兄弟-----------同一双亲下的同层结点(孩子之间互称兄弟)
堂兄弟--------即双亲位于同一层的结点(并非同一双亲)
祖先-----------即从根到该结点所经分支的所有结点
子孙-----------即该结点下层子树中的任一结点
基本术语1
结点-----------即树的数据元素
结点的度-----结点挂接的子树数
结点的层次--从根的该结点的层数(根结点算第一层)
终端结点-----即度为0的结点,即叶子
分支结点-----即度不为0的结点(也称为内部结点)
树的度--------所有结点度中的最大值
树的深度----指所有结点中的最大的层次(高度)
逻辑结构:
二叉树、树和森林
存储结构:
顺序存储树和链式存储树
}
二叉树(树的特殊化,有序树的一种)
{
二叉树的定义:
二叉树(Binary Tree)是n(n≥0)个结点所构成的集合,它或为空树(n = 0);或为 非空树,对于非空树T:
(1)有且仅有一个称之为根的结点;
(2)除根结点以外的其余结点分为两个互不相交的子集T1和T2,分别称为T的左子树
和右子树,且T1和T2本身又都是二叉树。
二叉树的基本特点:
(1)结点的度小于等于2.
(2)有序树(分左右子树)
二叉树与树的关系:
(1)二叉树是树的特殊化,是有序树的一种。
(2)所有的树都可以转化为唯一二叉树,不失一般性。
二叉树的性质
性质1:在二叉树的第i层至多有2^(i-1)个结点。
提问:第i层上至少有 个结点?
性质2:深度为k的二叉树至多有2^k-1个结点
提问:深度为k时至少有 个结点?
性质3: 对于任何一棵二叉树,若2度的结点数有n2个,则叶子数n0必定为n2+1 (即n0=n2+1)
*性质3由边和结点关系推出:n=n0+n1+n2;e=n-1=n1+2*n2;n0=n2+1;
特殊形态的二叉树
性质4: 具有n个结点的完全二叉树的深度必为[log2n]+1
性质5: 对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必为i/2。
二叉树的存储结构
}
二叉树的存储结构
{
顺序存储结构
特点:
结点间关系蕴含在其存储位置中
浪费空间,适于存满二叉树和完全二叉树
二叉树的链式存储(左孩子右孩子)
空指针数目=2n-(n-1)=n+1
二叉链表类型定义:
typedef struct BiNode{
TElemType data;
struct BiNode *lchild,*rchild; //左右孩子指针
}BiNode,*BiTree;
遍历二叉树和线索二叉树
{
遍历二叉树:
(1)先序遍历(前缀表示) 例:+ * * / A B C D E
(2)中序遍历(中缀表示) 例:A / B * C * D + E (数学一般的表达形式)
(3)后序遍历(后缀表示) 例:A B / C * D * E +
(4)层序遍历 例:+ * E * D / C A B
遍历算法(先序为例):
回忆
long Factorial ( long n ) {
if ( n == 0 ) return 1;//基本项
else return n * Factorial (n-1); //归纳项}
先序遍历(先序遍历建立二叉树)
Status PreOrderTraverse(BiTree T){
if(T==NULL) return OK; //空二叉树
else{
cout<<T->data; //访问根结点
PreOrderTraverse(T->lchild); //递归遍历左子树
PreOrderTraverse(T->rchild); //递归遍历右子树
}
}
void CreateBiTree(BiTree &T){
cin>>ch;
if (ch==’#’) T=NULL;
//递归结束,建空树
else{
T=new BiTNode; T->data=ch; //生成根结点
CreateBiTree(T->lchild); //递归创建左子树
CreateBiTree(T->rchild); //递归创建右子树
}
}
遍历算法分析
时间效率:O(n) //每个结点只访问一次
空间效率:O(n) //栈占用的最大辅助空间
线索二叉树 (利用二叉链树的n+1个空链域)
LTag :若 LTag=0, lchild域指向左孩子;
若 LTag=1, lchild域指向其前驱。
RTag :若 RTag=0, rchild域指向右孩子;
若 RTag=1, rchild域指向其后继。
哈夫曼树及其应用----最优二叉树
{
哈夫曼树的应用实例
{
哈夫曼编码(前缀编码)
*左分支用“0”,右分支用“1”
待编码字符:ABACCDA
编码表:
A—0
B—110
C—10
D—111
原则:出现次数较多的字符采用尽可能短的编码,要设计长度不等的编码,则必须使任一字符的编码都不是另一个字符的编码的前缀-前缀编码
}
哈夫曼树
{
术语:
(1)路径:由一结点到另一个结点间的分支所构成
(2)路径长度:路径上的分支数目
(3)带权路径的长度:结点到根的路径长度与结点上权的乘积
(4)树的带权路径长度:树中所有叶子结点的带权路径长度之和
(5)哈夫曼树:带权路径长度最小的树
}
}
}
}

相关文章推荐
- C#数据结构之顺序表(SeqList)实例详解
- Lua教程(七):数据结构详解
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- C#数据结构之队列(Quene)实例详解
- C#数据结构揭秘一
- C#数据结构之单链表(LinkList)实例详解
- 数据结构之Treap详解
- 用C语言举例讲解数据结构中的算法复杂度结与顺序表
- C#数据结构之堆栈(Stack)实例详解
- C#数据结构之双向链表(DbLinkList)实例详解
- JavaScript数据结构和算法之图和图算法
- Java数据结构及算法实例:冒泡排序 Bubble Sort
- Java数据结构及算法实例:插入排序 Insertion Sort
- Java数据结构及算法实例:考拉兹猜想 Collatz Conjecture
- java数据结构之java实现栈
- java数据结构之实现双向链表的示例
- Java数据结构及算法实例:选择排序 Selection Sort
- Java数据结构及算法实例:朴素字符匹配 Brute Force
- Java数据结构及算法实例:汉诺塔问题 Hanoi
- Java数据结构及算法实例:快速计算二进制数中1的个数(Fast Bit Counting)