OceanBase SQL解析源码分析(一)
2016-03-02 11:46
253 查看
原创文章,转载请注明: 转载自 镜中影的技术博客
本文链接地址: OceanBase SQL解析源码分析(一)
URL:http://blog.csdn.net/linkpark1904/article/details/50778265
一般编译器编译源程序要经过如下图1-1几个步骤:
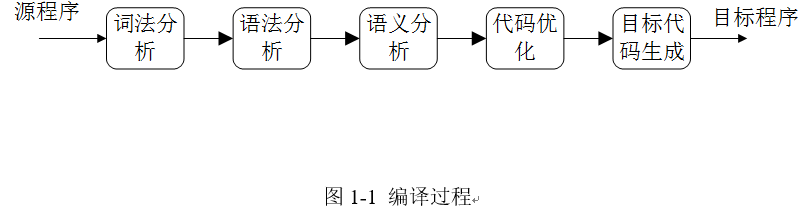
然而,在SQL语句解析中,OceanBase用到了Flex与Bison作为词法解析程序和语法解析程序的构建工具,在数据库系统中,对于SQL解析在语法分析阶段生成SQL语法树,然后对SQL语法树进行分析生成逻辑计划,然后进行查询优化,生成物理执行计划,所以,在数据库系统中代码优化部分以及目标代码生成部分和传统的编译器不同,其查询优化部分可以类比为代码优化,而生成物理执行计划部分可以类比为目标代码生成部分。
这里的重点在于词法分析以及语法分析,那么词法分析和语法分析的最主要作用如下:
词法分析:词法分析程序又称扫描器。进行词法分析时,依次读入源程序中的每个字符,依据语言的构词规则,识别出一个个具有独立意义的最小语法单位,即“单词”,并用某个单词符号来表示每个单词的词性是标识符、分界符还是数。
语法分析:对词法分析的结果,根据语言规则,将一个个单词符号组成语言的各种语法类。分析时如果发现有不合法规则的符号,要把这些出错的符号报给程序员。语法分析与语文中分析句子成分类似,分析过程常用语法树(怎样用数据结构来描述语法树,对于SQL解析程序来说极为重要)来表示句子。
另外,还有一个重要的概念——符号表。在编译过程中要记录源程序中出现的标识符,并收集每个标志符的各种属性信息。在词法分析中,对所有的标识符都用一个统一的符号表示,那么这个符号代表的标识符是变量名、函数名还是其他对象的名称呢?如果是变量名,那么变量的类型是什么?如果是函数名,那么编译程序怎么知道参数的个数、类型以及函数返回值的类型等信息呢?为此需要建立一个符号表来记录有关标识符的各种信息。符号表是由若干记录组成的数据结构,每一个标识符在表中有一个记录,每条记录有多个域,每个域记载标识符的一个属性。例如:
标识符的各种属性是在编译的不同阶段填入符号表的。词法分析阶段只能分析出标识符名;语法分析阶段只能判断标识符在语句中出现是否合法;只有到了语义分析阶段,才能将标识符的各种属性填入符号表并使用这些属性生成中间代码。
声明部分如图所示:

声明部分的头部%option 用来指定flex词法解析程序的编译选项,其中有几个比较重要的选项,一是%option noyyalloc noyyrealloc noyyfree。这个选项告诉flex不要用默认的内存分配函数,而是用自定义的内存分配函数,而这些函数的具体实现,在Flex的第三部分C语言代码部分来指定。这里有一个问题需要注意,
等函数的实现中均有用到alloc,也就是说,在flex中,和缓冲区相关的内存分配都是由yyalloc,yyrealloc等函数来确定的。由于oceanbase提供了自己默认的内存管理机制,所以为了统一控制内存管理,所以在这里没有采用Flex默认的内存分配方式,而是重写了。
另外一个比较重要的的声明是%option reentrant bison-bridge bison-locations,其中reentrant表示可重入词法分析器,在多线程程序中,允许多分词法分析器的拷贝同时激活,所以增加了reentrant选项后,需要为每一个词法分析器实例创建一个记录其状态信息的对象,也就是yyscan_t 类型的变量。具体体现在oceanbase中的初始化函数int parse_init(ParseResult* p)中的这样一段代码:
将yyscan_t进行初始化。
声明部分包含了外部定义的一些数据结构,以及词法分析中可能用到的函数的定义,由%{ …… %}包裹具体的引用文件。

规则定义部分即词法匹配规则,包含了词法匹配的正则表达式,匹配成功后相应触发的动作,关于动作代码需要写在{}中。另外,词法分析本质上是返回一系列的符号(token),所以基本在每个规则处理动作代码中都会return token,其中token是预先定义的一系列标志(这些token的定义放在语法分析程序中)。需要注意的是yylval这个变量,这个变量比较重要,表示当前节点的值,而这个yylval具体的定义可以由用户指定,具体在语法解析程序中进行指定。

其重写的函数就是yyalloc,yyrealloc,yyfree,这三个和内存相关的函数,在函数内部调用的parse_malloc,parse_realloc以及parse_free都是oceanbase提供的内存操作函数。

其中较为重要的是%union这个变量,这个变量是连接词法分析程序和语法分析程序的关键所在,在词法分析程序中变量yylval具体是什么就是由%union这个Bison变量来确定的,即%union是用来声明语法分析器中符号值得类型。在OceanBase 中yylval联合体由自定义的结构体_ParseNode, _NonReservedKeyword指针以及int类型的变量组成。
另外在头文件中的%parse-param也比较重要,这个声明是作为语法解析的入口函数的参数部分的声明,有了这个声明,在Bison生成语法解析程序的代码中,入口函数yyparse()就会被定义为void yyparse(sParseResult* result );

另外在第一部分中,还有各个token的声明以及语句节点类型的声明,在OceanBase中具体实例代码如下图2-4所示:

上图中%token定义语法树中的节点类型,也就是在语法分析过程中,每一个语法树节点的种类,而<…>中的值对应的是%union结构体中的某一种类型,即用来描述语法树的节点具体用什么样的数据结构或者数据类型来表示,这里NAME节点就是用%union联合体中的node来描述,即具体NAME节点在实际程序中的类型是struct _ParseNode * ,那么在实际解析过程中NAME的值具体就由node来表示。
对于所有声明的语法符号包括记号和非终结符,都可以有一个相应的值,默认情况下所有的符号值都是整数。像如下图2-5所示的节点的声明就是采用的默认符号值:

除此之外,还有运算符号优先级定义,具体实例如下图所示:

其中%left代表运算符是左结合,%right代表运算符是右结合,%nonassoc代表单目运算符,无结合性,而写在最顶层的运算符具有更低的优先级,写在最底层的运算符具有最高的优先级。例如,这里的UNION,EXCEPT是左结合运算符具有相同的优先级,而INTERSECT是左结合运算符,比UNION,EXCEPT优先级都高,OR运算符排在INTERSECT下面,所以其优先级要高于INTERSECT。

其中这里的BNF文法即是sql_stmt ::= stmt_list END_P。对应的C语言处理语句用{}引起来,其中变量$$表示:== 左边的值,在这里,表示sql_stmt的值,而变量$1表示:==右边的第一个语法符号的值,这里代表的是stmt_list的值,依次类推$2表示:==右边第二个语法符号的值,$3表示:==右边第三个符号的值。另外,在处理的C语言代码中,result变量也相对比较重要,这里的result变量正是%parse-param {ParseResult* result} 中的result变量,也就是sql解析入口函数传进来的变量。
这些函数也是对外的接口所在,在OceanBase源码中,正是通过调用parse_sql来进入SQL语法以及词法解析的。
其中parse_init用来进行初始化工作,主要用来初始化flex词法解析中的额外变量以及用于存放OceanBase语法解析结果的ParseResult指针。调用yylex_init_extra(p, &(p->yyscan_info_))函数对,scanner对象进行初始化操作。
本文链接地址: OceanBase SQL解析源码分析(一)
URL:http://blog.csdn.net/linkpark1904/article/details/50778265
一、 编译原理基础
涉及到SQL解析,当然离不开编译原理相关知识,毕竟SQL也是一门计算机语言,用于操作数据库,所以在数据库系统中,SQL解析模块为最上层模块,将SQL语句解析为后续模块能够读懂的语法树。一般编译器编译源程序要经过如下图1-1几个步骤:
然而,在SQL语句解析中,OceanBase用到了Flex与Bison作为词法解析程序和语法解析程序的构建工具,在数据库系统中,对于SQL解析在语法分析阶段生成SQL语法树,然后对SQL语法树进行分析生成逻辑计划,然后进行查询优化,生成物理执行计划,所以,在数据库系统中代码优化部分以及目标代码生成部分和传统的编译器不同,其查询优化部分可以类比为代码优化,而生成物理执行计划部分可以类比为目标代码生成部分。
这里的重点在于词法分析以及语法分析,那么词法分析和语法分析的最主要作用如下:
词法分析:词法分析程序又称扫描器。进行词法分析时,依次读入源程序中的每个字符,依据语言的构词规则,识别出一个个具有独立意义的最小语法单位,即“单词”,并用某个单词符号来表示每个单词的词性是标识符、分界符还是数。
语法分析:对词法分析的结果,根据语言规则,将一个个单词符号组成语言的各种语法类。分析时如果发现有不合法规则的符号,要把这些出错的符号报给程序员。语法分析与语文中分析句子成分类似,分析过程常用语法树(怎样用数据结构来描述语法树,对于SQL解析程序来说极为重要)来表示句子。
另外,还有一个重要的概念——符号表。在编译过程中要记录源程序中出现的标识符,并收集每个标志符的各种属性信息。在词法分析中,对所有的标识符都用一个统一的符号表示,那么这个符号代表的标识符是变量名、函数名还是其他对象的名称呢?如果是变量名,那么变量的类型是什么?如果是函数名,那么编译程序怎么知道参数的个数、类型以及函数返回值的类型等信息呢?为此需要建立一个符号表来记录有关标识符的各种信息。符号表是由若干记录组成的数据结构,每一个标识符在表中有一个记录,每条记录有多个域,每个域记载标识符的一个属性。例如:
| 标识符名 | 标识符类型 | 类型 | 地址 |
|---|---|---|---|
| Aaa | 1(表示变量) | 1(表示整型) | 0001 |
| Phone | $12 |
二、 Flex和Bison基础
Bison程序和Flex程序相同的三部分构成:声明部分、规则部分和C代码部分。声明部分包含了会被原样拷贝到目标分析程序开头的C代码,同样也通过%{和%}来声明。随后是%token记号声明,以便于告诉bison在语法分析程序中记号的名称。通常来说,记号总是使用大写字母,虽然bison本身并不这么要求。任何没有声明为记号的语法符号必须出现在至少一条规则的左边。2.1 Flex基础
2.1.1 声明部分
Flex组成部分分为声明部分、规则部分和C代码部分,和上面描述一致,下面截取OceanBase源码中sql_parser.l 文件的部分代码如下:声明部分如图所示:
声明部分的头部%option 用来指定flex词法解析程序的编译选项,其中有几个比较重要的选项,一是%option noyyalloc noyyrealloc noyyfree。这个选项告诉flex不要用默认的内存分配函数,而是用自定义的内存分配函数,而这些函数的具体实现,在Flex的第三部分C语言代码部分来指定。这里有一个问题需要注意,
在哪里需要用到yyalloc, yyrealloc以及yyfree?我跟进了Flex生成的代码查看到在:
yy_scan_bytes (yyconst char * yybytes, int _yybytes_len , yyscan_t yyscanner);
yy_create_buffer (FILE * file, int size , yyscan_t yyscanner);
等函数的实现中均有用到alloc,也就是说,在flex中,和缓冲区相关的内存分配都是由yyalloc,yyrealloc等函数来确定的。由于oceanbase提供了自己默认的内存管理机制,所以为了统一控制内存管理,所以在这里没有采用Flex默认的内存分配方式,而是重写了。
另外一个比较重要的的声明是%option reentrant bison-bridge bison-locations,其中reentrant表示可重入词法分析器,在多线程程序中,允许多分词法分析器的拷贝同时激活,所以增加了reentrant选项后,需要为每一个词法分析器实例创建一个记录其状态信息的对象,也就是yyscan_t 类型的变量。具体体现在oceanbase中的初始化函数int parse_init(ParseResult* p)中的这样一段代码:
ret = yylex_init_extra(p, &(p->yyscan_info_));
将yyscan_t进行初始化。
声明部分包含了外部定义的一些数据结构,以及词法分析中可能用到的函数的定义,由%{ …… %}包裹具体的引用文件。
2.1.2 规则定义部分
接下来是规则定义部分,规则定义部分由%%……%%包裹起来,截取部分OceanBase词法解析程序的代码如下图示:规则定义部分即词法匹配规则,包含了词法匹配的正则表达式,匹配成功后相应触发的动作,关于动作代码需要写在{}中。另外,词法分析本质上是返回一系列的符号(token),所以基本在每个规则处理动作代码中都会return token,其中token是预先定义的一系列标志(这些token的定义放在语法分析程序中)。需要注意的是yylval这个变量,这个变量比较重要,表示当前节点的值,而这个yylval具体的定义可以由用户指定,具体在语法解析程序中进行指定。
2.1.3 C代码处理部分
第三部分是C语言代码部分,负责实现具体的工具函数,OceanBase词法解析中的C语言代码部分如下图所示:其重写的函数就是yyalloc,yyrealloc,yyfree,这三个和内存相关的函数,在函数内部调用的parse_malloc,parse_realloc以及parse_free都是oceanbase提供的内存操作函数。
2.2 Bison基础
与Flex类似,Bison程序结构和Flex一致。在程序结构上也是分为三部分,声明部分,规则部分以及C语言代码处理部分。2.2.1 声明部分
在Bison中声明部分和Flex类似,在%{……%}中引入头文件声明,也就是语法解析所需要用到的数据结构函数等等。一个具体的声明实例如下图所示:其中较为重要的是%union这个变量,这个变量是连接词法分析程序和语法分析程序的关键所在,在词法分析程序中变量yylval具体是什么就是由%union这个Bison变量来确定的,即%union是用来声明语法分析器中符号值得类型。在OceanBase 中yylval联合体由自定义的结构体_ParseNode, _NonReservedKeyword指针以及int类型的变量组成。
另外在头文件中的%parse-param也比较重要,这个声明是作为语法解析的入口函数的参数部分的声明,有了这个声明,在Bison生成语法解析程序的代码中,入口函数yyparse()就会被定义为void yyparse(sParseResult* result );
另外在第一部分中,还有各个token的声明以及语句节点类型的声明,在OceanBase中具体实例代码如下图2-4所示:
上图中%token定义语法树中的节点类型,也就是在语法分析过程中,每一个语法树节点的种类,而<…>中的值对应的是%union结构体中的某一种类型,即用来描述语法树的节点具体用什么样的数据结构或者数据类型来表示,这里NAME节点就是用%union联合体中的node来描述,即具体NAME节点在实际程序中的类型是struct _ParseNode * ,那么在实际解析过程中NAME的值具体就由node来表示。
对于所有声明的语法符号包括记号和非终结符,都可以有一个相应的值,默认情况下所有的符号值都是整数。像如下图2-5所示的节点的声明就是采用的默认符号值:
除此之外,还有运算符号优先级定义,具体实例如下图所示:
其中%left代表运算符是左结合,%right代表运算符是右结合,%nonassoc代表单目运算符,无结合性,而写在最顶层的运算符具有更低的优先级,写在最底层的运算符具有最高的优先级。例如,这里的UNION,EXCEPT是左结合运算符具有相同的优先级,而INTERSECT是左结合运算符,比UNION,EXCEPT优先级都高,OR运算符排在INTERSECT下面,所以其优先级要高于INTERSECT。
2.2.2 规则定义部分
规则定义部分与词法分析类似,也是由%%……%%引用起来,其定义的规则为SQL语言具体的BNF文法,一个具体的实例代码如下图所示:其中这里的BNF文法即是sql_stmt ::= stmt_list END_P。对应的C语言处理语句用{}引起来,其中变量$$表示:== 左边的值,在这里,表示sql_stmt的值,而变量$1表示:==右边的第一个语法符号的值,这里代表的是stmt_list的值,依次类推$2表示:==右边第二个语法符号的值,$3表示:==右边第三个符号的值。另外,在处理的C语言代码中,result变量也相对比较重要,这里的result变量正是%parse-param {ParseResult* result} 中的result变量,也就是sql解析入口函数传进来的变量。
2.2.3 C代码处理部分
这一部分主要涉及一些工具函数以及主函数的设计与实现,在OceanBase中,主要有四个函数,一个出错处理函数,一个解析初始化函数,一个解析开始函数,一个解析终止函数:void yyerror(YYLTYPE* yylloc, ParseResult* p, char* s, ...) int parse_init(ParseResult* p) int parse_sql(ParseResult* p, const char* buf, size_t len) int parse_terminate(ParseResult* p)
这些函数也是对外的接口所在,在OceanBase源码中,正是通过调用parse_sql来进入SQL语法以及词法解析的。
其中parse_init用来进行初始化工作,主要用来初始化flex词法解析中的额外变量以及用于存放OceanBase语法解析结果的ParseResult指针。调用yylex_init_extra(p, &(p->yyscan_info_))函数对,scanner对象进行初始化操作。
