使用python操作elasticsearch实现监控数据及kibana分析
2016-02-23 10:54
1216 查看
原文地址:http://rfyiamcool.blog.51cto.com/1030776/1420811
前言:
例行公事,有些人可能不太了解elasticsearch,下面搜了一段,大家瞅一眼。
Elasticsearch是一款分布式搜索引擎,支持在大数据环境中进行实时数据分析。它基于Apache Lucene文本搜索引擎,内部功能通过ReST API暴露给外部。除了通过HTTP直接访问Elasticsearch,还可以通过支持Java、JavaScript、Python及更多语言的客户端库来访问。它也支持集成Apache
Hadoop环境。Elasticsearch在有些处理海量数据的公司中已经有所应用,如GitHub、Foursquare和SoundCloud等。
elasticsearch 他对外提供了rest的http的接口,貌似很强大的样子。 但是咱们的一些数据平台市场会对于elasticsearch的数据进行分析,尤其是实时分析。 当然不能用 http的方式。 比如官网的demo提供的例子:
下面是查询,/ceshi 是索引,rui是type,搜索的内容是,title是jones的。
添加数据
1.x之后,貌似不能直接curl,
注意,唯一标识符是放置在URL中而不是请求体中。如果您忽略这个标识符,搜索会返回一个错误,类似如下:
No handler found for uri [/ceshi/rui/] and method [PUT]
发现用0.90.x的人,还是很多的~
当然在python里面,咱们可以用urllib2来搞数据。
但是这样的话,速度明显有点慢,官方提供了更加快速更方便的方法。
>>> from datetime import datetime
>>> from elasticsearch import Elasticsearch
# 连接elasticsearch 的端口,默认是9200
>>> es = Elasticsearch()
# 创建索引,索引的名字是my-index, 如果已经存在了,就给个400
>>> es.indices.create(index='my-index', ignore=400)
{u'acknowledged': True}
# 插入
>>> es.index(index="my-index", doc_type="test-type", id=42, body={"any": "data", "timestamp": datetime.now()})
{u'_id': u'42', u'_index': u'my-index', u'_type': u'test-type', u'_version': 1, u'ok': True}
# 查询
>>> es.get(index="my-index", doc_type="test-type", id=42)['_source']
{u'any': u'data', u'timestamp': u'2013-05-12T19:45:31.804229'}
其实熟悉mongodb的人,再看elasticsearch的语法,会发现非常的熟悉。
上面的意思是,查询这个时间段里面的数据。
上面是精确的匹配,匹配user值为 xiaorui 的数据。
一些详细的语法就不在描述了,大家看下官方的文档,然后再python引用就行了。
原文:http://rfyiamcool.blog.51cto.com/1030776/1420811
下面的数据,是我用python的elasticsearch库,打的随机数据。 关键是kibana会把es里面的数据,相应的统计好的。
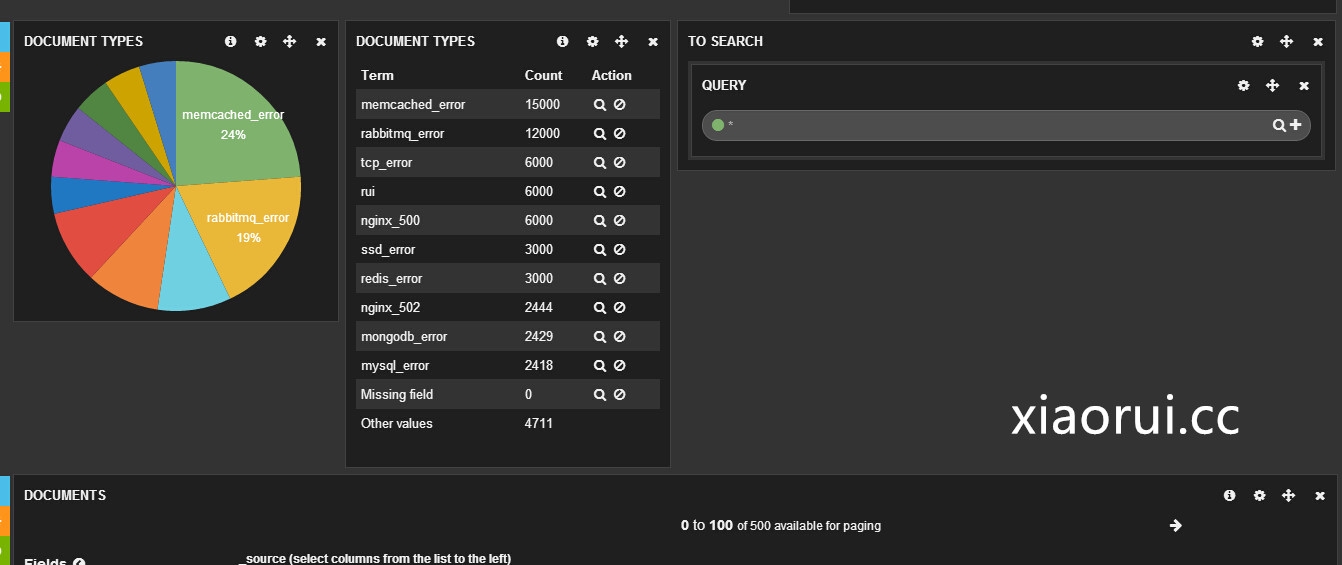
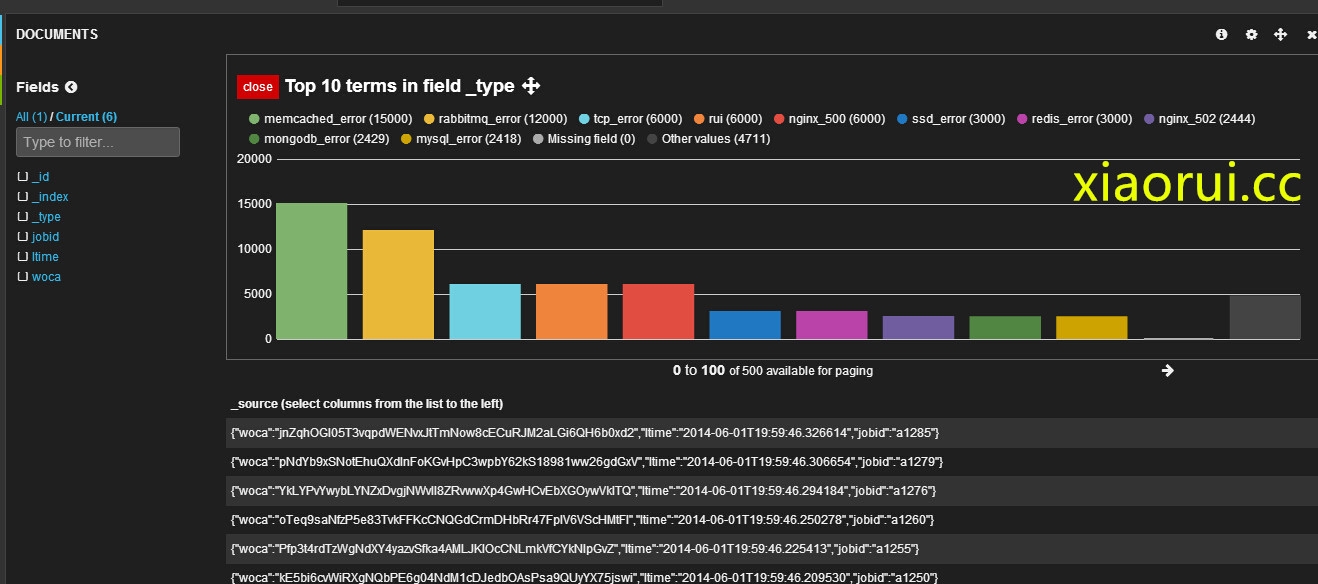
支持很多的语法,可以随意的query查询,你想要的组合数据。
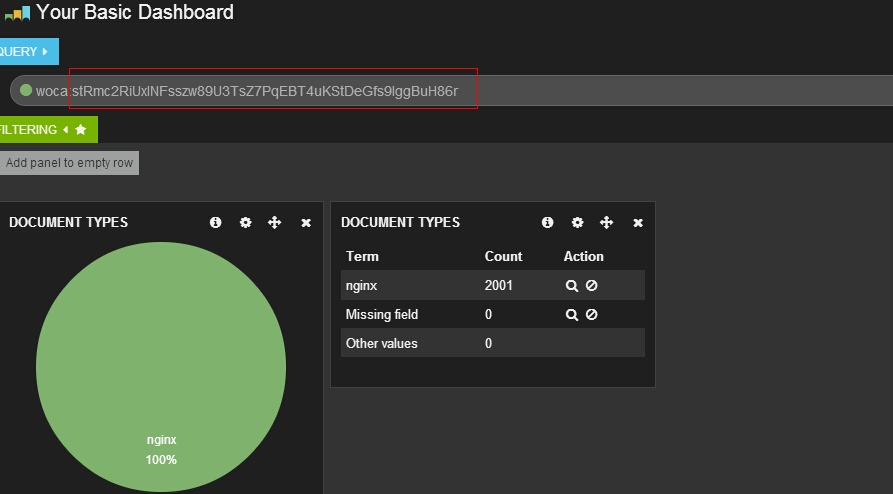
还可以多条件查询
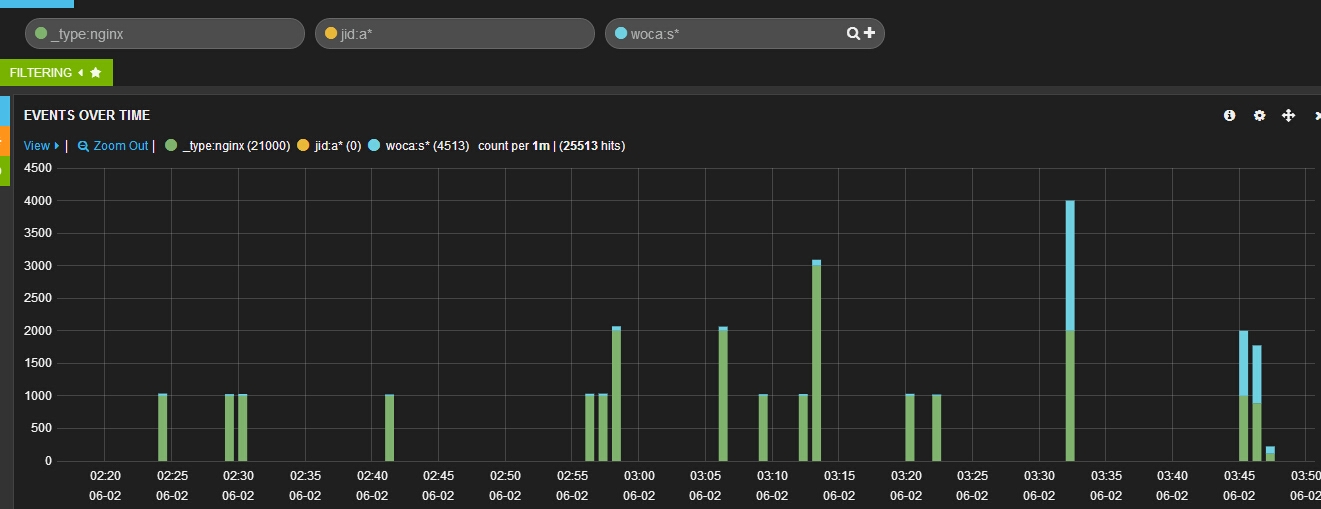
其中遇到了一个问题,kibana3 时间貌似是UTC的,图表显示的时候,总是差距8个小时,需要调整源码,改成北京时间。
其实对我来说,我还是更喜欢用mongodb,他的bjson,让我爽到天,哈 ! 要是量大的话,用mongodb的分片,elasticsearch的dsl语法,还是让我有些看不下去。 我这里正在做通知平台,以前都是把数据放在mongodb,然后用各种图表展示。 我发现kibana很绚丽,就在研究kibana的一些个特性, 他只是为elasticsearch存在的。
所以大家也不要在尝试改掉kibana,直接把数据插入到elasticsearch,然后通过kibana显示就行了。
前言:
例行公事,有些人可能不太了解elasticsearch,下面搜了一段,大家瞅一眼。
Elasticsearch是一款分布式搜索引擎,支持在大数据环境中进行实时数据分析。它基于Apache Lucene文本搜索引擎,内部功能通过ReST API暴露给外部。除了通过HTTP直接访问Elasticsearch,还可以通过支持Java、JavaScript、Python及更多语言的客户端库来访问。它也支持集成Apache
Hadoop环境。Elasticsearch在有些处理海量数据的公司中已经有所应用,如GitHub、Foursquare和SoundCloud等。
elasticsearch 他对外提供了rest的http的接口,貌似很强大的样子。 但是咱们的一些数据平台市场会对于elasticsearch的数据进行分析,尤其是实时分析。 当然不能用 http的方式。 比如官网的demo提供的例子:
下面是查询,/ceshi 是索引,rui是type,搜索的内容是,title是jones的。
注意,唯一标识符是放置在URL中而不是请求体中。如果您忽略这个标识符,搜索会返回一个错误,类似如下:
No handler found for uri [/ceshi/rui/] and method [PUT]
发现用0.90.x的人,还是很多的~
当然在python里面,咱们可以用urllib2来搞数据。
>>> from datetime import datetime
>>> from elasticsearch import Elasticsearch
# 连接elasticsearch 的端口,默认是9200
>>> es = Elasticsearch()
# 创建索引,索引的名字是my-index, 如果已经存在了,就给个400
>>> es.indices.create(index='my-index', ignore=400)
{u'acknowledged': True}
# 插入
>>> es.index(index="my-index", doc_type="test-type", id=42, body={"any": "data", "timestamp": datetime.now()})
{u'_id': u'42', u'_index': u'my-index', u'_type': u'test-type', u'_version': 1, u'ok': True}
# 查询
>>> es.get(index="my-index", doc_type="test-type", id=42)['_source']
{u'any': u'data', u'timestamp': u'2013-05-12T19:45:31.804229'}
其实熟悉mongodb的人,再看elasticsearch的语法,会发现非常的熟悉。
一些详细的语法就不在描述了,大家看下官方的文档,然后再python引用就行了。
原文:http://rfyiamcool.blog.51cto.com/1030776/1420811
下面的数据,是我用python的elasticsearch库,打的随机数据。 关键是kibana会把es里面的数据,相应的统计好的。
支持很多的语法,可以随意的query查询,你想要的组合数据。
还可以多条件查询
其中遇到了一个问题,kibana3 时间貌似是UTC的,图表显示的时候,总是差距8个小时,需要调整源码,改成北京时间。
其实对我来说,我还是更喜欢用mongodb,他的bjson,让我爽到天,哈 ! 要是量大的话,用mongodb的分片,elasticsearch的dsl语法,还是让我有些看不下去。 我这里正在做通知平台,以前都是把数据放在mongodb,然后用各种图表展示。 我发现kibana很绚丽,就在研究kibana的一些个特性, 他只是为elasticsearch存在的。
所以大家也不要在尝试改掉kibana,直接把数据插入到elasticsearch,然后通过kibana显示就行了。

相关文章推荐
- Python的UnicodeEncodeError: 'ascii' codec can't encode characters
- Pandas数据分析基础
- Python学习笔记《一》
- python文档生成工具pydoc在网页上查看的方法
- pyinstaller打包python步骤
- How to concatenate two matrices in Python?
- python爬虫(抓取百度新闻列表)
- jpython LookupError: unknown encoding 'ms936' 问题解决
- 【python】编程语言入门经典100例--11
- python xlsxwriter 在 flask 中的使用
- python windows报错ConfigParser.NoSectionError: No section: 'mysql'
- Python实用环境pyenv搭建教程
- Python lib
- Python中调用父类的同名方法
- Python中方法链的使用方法
- [python爬虫] Selenium爬取新浪微博内容及用户信息
- python字典概述
- python字典概述
- 图解python入门
- python发送smtp 邮件 图片