Spring Batch入门实例教程实现对CVS文件的操作
2016-02-14 09:52
841 查看
原文:Spring
Batch入门实例教程实现对CVS文件的操作
源代码下载地址:http://www.zuidaima.com/share/1749751500557312.htm
Spring Batch是一个轻量级的,完全面向Spring的批处理框架,可以应用于企业级大量的数据处理系统。Spring Batch以POJO和大家熟知的Spring框架为基础,使开发者更容易的访问和利用企业级服务。Spring Batch可以提供大量的,可重复的数据处理功能,包括日志记录/跟踪,事务管理,作业处理统计工作重新启动、跳过,和资源管理等重要功能。
详细介绍请看上一篇《Spring Batch入门教程及其框架搭建》
本文将再通过一个完整的实例,运用Spring Batch对CSV文件的读写操作。此实例的流程是:读取一个含有四个字段的CSV文件(ID,Name,Age,Score),对读取的字段做简单的处理,然后输出到另外一个CSV文件中。
工程结构如下图:
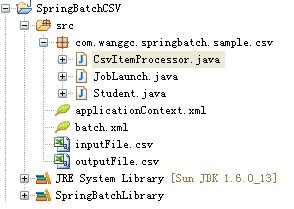
项目文件说明:
1、JobLaunch类用来启动Job,
2、CsvItemProcessor类用来对Reader取得的数据进行处理,
3、Student类是一个POJO类,用来存放映射的数据。
4、inputFile.csv是数据读取文件, outputFile.csv是数据输出文件。
本Job包含一个Step,完成一个完整的CSV文件读写功能。分别由 csvItemReader完成CSV文件的读操作,由 csvItemProcessor完成对取得数据的处理,由 csvItemWriter完成对CSV文件的写操作。
csvItemReader实现的是Spring Batch提供FlatFileItemReader类,此类主要用于Flat文件的读操作。它包含两个必要的属性 resource和 lineMapper。前者指定要读取的文件的位置,后者是将文件的每一行映射成一个Pojo对象。其中 lineMapper也有两个重要属性 lineTokenizer和 fieldSetMapper, lineTokenizer将文件的一行分解成一个 FieldSet,然后由 fieldSetMapper映射成Pojo对象。
这种方式与DB的读操作非常类似。lineMapper类似于ResultSet,文件中的一行类似于Table中的一条记录,被封装成的FieldSet,类似于RowMapper。至于怎么将一条记录封装,这个工作由lineTokenizer的继承类DelimitedLineTokenizer完成。DelimitedLineTokenizer的delimiter属性决定文件的一行数据按照什么分解,默认的是“,”, names属性标示分解的每个字段的名字,传给fieldSetMapper(本实例用的是BeanWrapperFieldSetMapper)的时候,就可以按照这个名字取得相应的值。fieldSetMapper的属性prototypeBeanName,是映射Pojo类的名字。设置了此属性后,框架就会将lineTokenizer分解成的一个FieldSet映射成Pojo对象,映射是按照名字来完成的(lineTokenizer分解时标注的名字与Pojo对象中字段的名字对应)。
总之,FlatFileItemReader读取一条记录由以下四步完成:1,从resource指定的文件中读取一条记录;2,lineTokenizer将这条记录按照delimiter分解成Fileset,每个字段的名字由names属性取得;3,将分解成的Fileset传递给fieldSetMapper,由其按照名字映射成Pojo对象;4,最终由FlatFileItemReader将映射成的Pojo对象返回,框架将返回的对象传递给Processor。
实例中用到的输入数据如下:

实例输出结果如下:

Batch入门实例教程实现对CVS文件的操作
源代码下载地址:http://www.zuidaima.com/share/1749751500557312.htm
Spring Batch是一个轻量级的,完全面向Spring的批处理框架,可以应用于企业级大量的数据处理系统。Spring Batch以POJO和大家熟知的Spring框架为基础,使开发者更容易的访问和利用企业级服务。Spring Batch可以提供大量的,可重复的数据处理功能,包括日志记录/跟踪,事务管理,作业处理统计工作重新启动、跳过,和资源管理等重要功能。
详细介绍请看上一篇《Spring Batch入门教程及其框架搭建》
本文将再通过一个完整的实例,运用Spring Batch对CSV文件的读写操作。此实例的流程是:读取一个含有四个字段的CSV文件(ID,Name,Age,Score),对读取的字段做简单的处理,然后输出到另外一个CSV文件中。
工程结构如下图:
项目文件说明:
1、JobLaunch类用来启动Job,
2、CsvItemProcessor类用来对Reader取得的数据进行处理,
3、Student类是一个POJO类,用来存放映射的数据。
4、inputFile.csv是数据读取文件, outputFile.csv是数据输出文件。
本Job包含一个Step,完成一个完整的CSV文件读写功能。分别由 csvItemReader完成CSV文件的读操作,由 csvItemProcessor完成对取得数据的处理,由 csvItemWriter完成对CSV文件的写操作。
csvItemReader实现的是Spring Batch提供FlatFileItemReader类,此类主要用于Flat文件的读操作。它包含两个必要的属性 resource和 lineMapper。前者指定要读取的文件的位置,后者是将文件的每一行映射成一个Pojo对象。其中 lineMapper也有两个重要属性 lineTokenizer和 fieldSetMapper, lineTokenizer将文件的一行分解成一个 FieldSet,然后由 fieldSetMapper映射成Pojo对象。
这种方式与DB的读操作非常类似。lineMapper类似于ResultSet,文件中的一行类似于Table中的一条记录,被封装成的FieldSet,类似于RowMapper。至于怎么将一条记录封装,这个工作由lineTokenizer的继承类DelimitedLineTokenizer完成。DelimitedLineTokenizer的delimiter属性决定文件的一行数据按照什么分解,默认的是“,”, names属性标示分解的每个字段的名字,传给fieldSetMapper(本实例用的是BeanWrapperFieldSetMapper)的时候,就可以按照这个名字取得相应的值。fieldSetMapper的属性prototypeBeanName,是映射Pojo类的名字。设置了此属性后,框架就会将lineTokenizer分解成的一个FieldSet映射成Pojo对象,映射是按照名字来完成的(lineTokenizer分解时标注的名字与Pojo对象中字段的名字对应)。
总之,FlatFileItemReader读取一条记录由以下四步完成:1,从resource指定的文件中读取一条记录;2,lineTokenizer将这条记录按照delimiter分解成Fileset,每个字段的名字由names属性取得;3,将分解成的Fileset传递给fieldSetMapper,由其按照名字映射成Pojo对象;4,最终由FlatFileItemReader将映射成的Pojo对象返回,框架将返回的对象传递给Processor。
实例中用到的输入数据如下:
实例输出结果如下:

相关文章推荐
- 一个jar包里的网站
- 一个jar包里的网站之文件上传
- 一个jar包里的网站之返回对媒体类型
- Spring整合Quartz(JobDetailBean方式)
- Spring整合Quartz(JobDetailBean方式)
- 模拟Spring的简单实现
- spring+html5实现安全传输随机数字密码键盘
- Spring中属性注入详解
- SpringMVC框架下JQuery传递并解析Json格式的数据是如何实现的
- struts2 spring整合fieldError问题
- spring的jdbctemplate的crud的基类dao
- 读取spring配置文件的方法(spring读取资源文件)
- Spring Bean基本管理实例详解
- java实现简单美女拼图游戏
- 详解Java的Spring框架中的事务管理方式
- 解析Java的Spring框架的BeanPostProcessor发布处理器
- Java开发框架spring实现自定义缓存标签
- java基本教程之线程休眠 java多线程教程
- JSP开发中在spring mvc项目中实现登录账号单浏览器登录
- spring boot实战之内嵌容器tomcat配置