几种排序算法总结
2016-02-10 18:21
585 查看
注:以下所有排序算法都是按照整数值从小到大排序。
示例:对于序列4, 10, 1, 6, 2, 7, 3, 8如下图(红框表示下一趟需要处理的子序列)
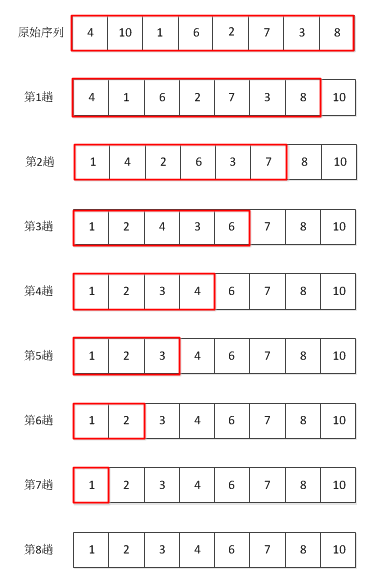
即总共需要走n趟,当第i趟走完时倒数i个数是有序的。
代码
优化:由上面的示意图可知,当第4趟走完时序列已经完全排好序了,后面的几趟都是多余的。因此可以弄一个标记变量,假如在某一趟中没有发生交换则说明对于任意两个相邻的元素都满足前者<后者,也就是序列已经排好序了,因此可以提前结束。
时间复杂度:O(n^2),空间复杂度O(1),稳定性:稳定。
总结:走n趟,第i趟将前n-i+1个元素的最大数冒到最后面。
示例:对于序列4, 10, 1, 6, 2, 7, 3, 8如下图
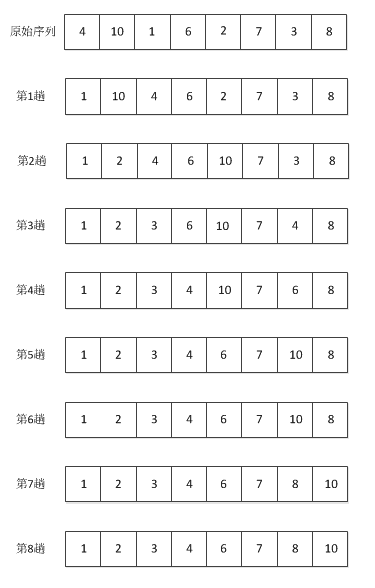
代码
时间复杂度:O(n^2),空间复杂度O(1),稳定性:不稳定。
总结:走n趟,第i趟将后n-i+1个元素的最小数选择放到最前面。
示例:对于序列4, 10, 1, 6, 2, 7, 3, 8如下图

代码(直接插入法)
时间复杂度:O(n^2),空间复杂度O(1),稳定性:稳定。
总结:将后n-1个元素逐个插入到前面的有序序列中
示例:对于序列4, 10, 1, 6, 2, 7, 3, 8。Partition过程:
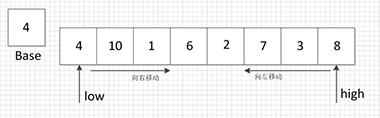
代码
时间复杂度:最好情况O(nlogn),最坏情况O(n^2),平均情况O(nlogn)。空间复杂度:所需栈空间O(logn)~O(n)。稳定性:不稳定
代码:
时间复杂度:最好情况O(nlogn),最坏情况O(nlogn),平均情况O(nlogn)。空间复杂度:O(1)。稳定性:不稳定
时间复杂度:最好情况O(nlogn),最坏情况O(nlogn),平均情况O(nlogn)。空间复杂度:O(n)。稳定性:稳定
说明:如果最好情况与最坏情况的时间复杂度不一样,则说明初始数据集的排列顺序对该算法的性能有影响。
转载请注明出处:http://blog.csdn.net/u012619640/article/details/50650054
冒泡排序
思想:对于一个序列,走一趟把最大数冒到最后面。示例:对于序列4, 10, 1, 6, 2, 7, 3, 8如下图(红框表示下一趟需要处理的子序列)
即总共需要走n趟,当第i趟走完时倒数i个数是有序的。
代码
for(i = 0; i < n; i++) {//需要走n趟
for(j = 0; j < n - i - 1; j++) {//后面i个元素已经有序了不用管
if(a[j] > a[j + 1]) {//不断地把较大的数后移
int temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
}优化:由上面的示意图可知,当第4趟走完时序列已经完全排好序了,后面的几趟都是多余的。因此可以弄一个标记变量,假如在某一趟中没有发生交换则说明对于任意两个相邻的元素都满足前者<后者,也就是序列已经排好序了,因此可以提前结束。
时间复杂度:O(n^2),空间复杂度O(1),稳定性:稳定。
总结:走n趟,第i趟将前n-i+1个元素的最大数冒到最后面。
选择排序
思想:对于一个序列,走一趟就把选到的最小数放在该序列的最前面。示例:对于序列4, 10, 1, 6, 2, 7, 3, 8如下图
代码
for(i = 0; i < n; i++) {
int index = i;
for(j = i; j < n; j++) {//前面i-1个元素已经有序了
if(a[j] < a[index]) {//寻找后n-i+1个元素的最小数下标位置
index = j;
}
}
if(index != i) {//将找到的最小数放在最前面
int temp = a[index];
a[index] = a[i];
a[i] = temp;
}
}时间复杂度:O(n^2),空间复杂度O(1),稳定性:不稳定。
总结:走n趟,第i趟将后n-i+1个元素的最小数选择放到最前面。
插入排序
思想:对于后面n-1个数,依次插入到前面的有序序列。示例:对于序列4, 10, 1, 6, 2, 7, 3, 8如下图
代码(直接插入法)
for(i = 1; i < n; i++) {//从第2个元素开始
for(j = i - 1; j >= 0; j--) {//将a[i]插入到前面有序的序列中
if(a[j + 1] < a[j]) {
int temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
} else {
break;
}
}
}时间复杂度:O(n^2),空间复杂度O(1),稳定性:稳定。
总结:将后n-1个元素逐个插入到前面的有序序列中
快速排序
思想:分治排序每一部分,而排序采用partition方法进行。示例:对于序列4, 10, 1, 6, 2, 7, 3, 8。Partition过程:
代码
//对a[left]~a[right]进行划分
int partition(int a[], int left, int right) {
if(left > right || left < 0) {
return -1;//出错
} else {
int base = a[left];
int low, high;
low = left;
high = right;
while(low < high) {
//右指针寻找第一个小于base的数的位置
while(low < high && a[high] >= base) {
high--;
}
//如果找到则放到low指针指向的位置
if(low < high) {
a[low] = a[high];
low++;
}
//左指针寻找第一个大于等于base的数的位置
while(low < high && a[low] < base) {
low++;
}
//如果找到则放在high指针指向的位置
if(low < high) {
a[high] = a[low];
high--;
}
}
//此时low一定等于high
//将基准值放在中间位置并返回
a[low] = base;
return low;
}
}
//对a[left]~a[right]排序
void quickSort(int a[], int left, int right) {
if(left < right) {
int mid = partition(a, left, right);
quickSort(a, left, mid - 1);
quickSort(a, mid + 1, right);
}
}时间复杂度:最好情况O(nlogn),最坏情况O(n^2),平均情况O(nlogn)。空间复杂度:所需栈空间O(logn)~O(n)。稳定性:不稳定
堆排序
思想:利用堆进行调整使得堆上的元素有序。代码:
void siftDDown(int a[], int p, int len) {
int temp;
int child = 2 * p + 1;
while(child < len) {
//有右孩子且右孩子更小
if(child + 1 <len && a[child] > a[child + 1]) {
child++;
}
if(a[p] > a[child]) {
temp = a[p];
a[p] = a[child];
a[child] = temp;
p = child;
child = 2 * p + 1;
} else {
break;
}
}
}
int main()
{
int a[] = {4, 10, 1, 6, 2, 7, 3, 8};
int n = 8;
int i;
//建立小根堆
for(i = n/2 - 1; i>= 0; i--) {
siftDDown(a, i, n);
}
//不断取出堆顶元素
for(i = n - 1; i >= 0; i--) {
cout<<a[0]<<" ";
a[0] = a[i];
siftDDown(a, 0, i);
}
cout<<endl<<endl;
return 0;
}时间复杂度:最好情况O(nlogn),最坏情况O(nlogn),平均情况O(nlogn)。空间复杂度:O(1)。稳定性:不稳定
归并排序
代码://合并a[start]~a[mid]和a[mid+1]~a[end]
void merge(int a[], int start, int mid, int end) {
if(start > mid || mid + 1 > end) {
return;
}
int p = start, q = mid + 1;
//临时空间
int *temp = new int[end - start + 1];
int k = 0;
while(p <= mid && q <= end) {
if(a[p] <= a[q]) {
temp[k++] = a[p++];
} else {
temp[k++] = a[q++];
}
}
while(p <= mid) {
temp[k++] = a[p++];
}
while(q <= end) {
temp[k++] = a[q++];
}
//
for(int i = start; i <= end; i++) {
a[i] = temp[i - start];
}
delete []temp;
}
void mergeSort(int a[], int start, int end) {
if(start < end) {
int mid = (start + end) / 2;
mergeSort(a, start, mid);//a[start...mid]
mergeSort(a, mid + 1, end);//a[mid+1...end]
merge(a, start, mid, end);
}
}时间复杂度:最好情况O(nlogn),最坏情况O(nlogn),平均情况O(nlogn)。空间复杂度:O(n)。稳定性:稳定
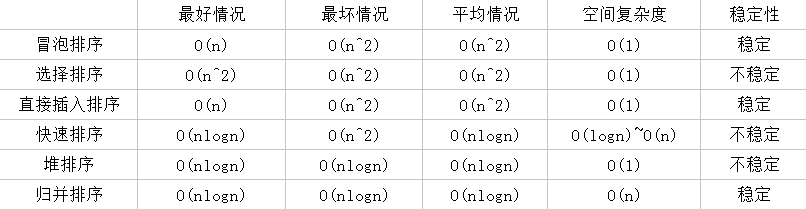
几种排序算法对比
说明:如果最好情况与最坏情况的时间复杂度不一样,则说明初始数据集的排列顺序对该算法的性能有影响。
转载请注明出处:http://blog.csdn.net/u012619640/article/details/50650054

相关文章推荐
- 在命令行用 sort 进行排序
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- 文件遍历排序函数
- C#数据结构之顺序表(SeqList)实例详解
- C#选择排序法实例分析
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- Lua教程(七):数据结构详解
- C#实现Datatable排序的方法
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- 超大数据量存储常用数据库分表分库算法总结
- SQLSERVER的排序问题结果不是想要的
- Windows Powershell排序和分组管道结果
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- C#数据结构之队列(Quene)实例详解
- C#数据结构揭秘一
- C#通过IComparable实现ListT.sort()排序