MongoDB仲裁节点的理解以及memcached,zookeeper,redis,故障恢复方案思考.
2016-02-07 13:03
1151 查看
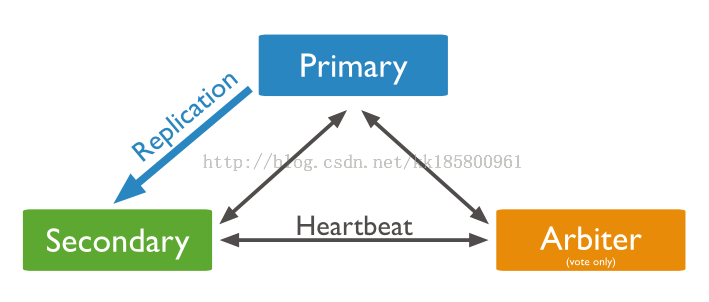
在进行副本集部署时我们会添加一个或多个仲裁节点,仲裁节点不用于备份数据,由于它职责的职责是负责选举主节点,所以对硬件没有太高要求,可以将它部署在单独的服务器上,这个服务器可以是监听服务器,也可以部署在虚拟机上,但是有一点仲裁节点一定不能备份数据.仲裁节点和注解点都可以参与选举,而选举对象是各个非投票成员,也就是需要备份数据的从节点.
图列
这让我想起了以前了解过的zookeeper集群中的选举方案,它和MongoDB有所不同.
ZooKeeper采用一种称为Leader election的选举算法。在整个集群运行过程中,只有一个Leader,其他的都是Follower,如果ZooKeeper集群在运行过程中Leader出了问题,系统会采用该算法重新选出一个Leader。因此,各个结点之间要能够保证互相连接,必须配置上述映射。
ZooKeeper集群启动的时候,会首先选出一个Leader,在Leader election过程中,某一个满足选举算的结点就能成为Leader。
而对于memcached不提供分布式方案,我们可以利用代理服务器来实现分布式部署.而Magent就是一个memcached代理服务器,但是它不存在什么leader,secondary,所有的命令入口都是magent这个代理服务器,当某个节点出现done机时,而请求数据找不到,它会从备份节点上获取.当让我们可用通过zookeeper来管理memcached分布式集群.
而对于redis 当设置好slave服务器后,slave会建立和master的连接,然后发送sync命令。无论是第一次同步建立的连接还是连接断开后的重新连 接,master都会启动一个后台进程,将数据库快照保存到文件中,同时master主进程会开始收集新的写命令并缓存起来。后台进程完成写文件 后,master就发送文件给slave,slave将文件保存到磁盘上,然后加载到内存恢复数据库快照到slave上。接着master就会把缓存的命 令转发给slave。而且后续master收到的写命令都会通过开始建立的连接发送给slave。从master到slave的同步数据的命令和从 client发送的命令使用相同的协议格式。当master和slave的连接断开时slave可以自动重新建立连接。如果master同时收到多个 slave发来的同步连接命令,只会使用启动一个进程来写数据库镜像,然后发送给所有slave。对于master出现故障时,我们可以通过持久化数据来恢复,而对于salve出现故障那么它会和master重新连接然后将所有的内从快照写入slave.可见这样恢复一定是很慢的.
图列
这让我想起了以前了解过的zookeeper集群中的选举方案,它和MongoDB有所不同.
ZooKeeper采用一种称为Leader election的选举算法。在整个集群运行过程中,只有一个Leader,其他的都是Follower,如果ZooKeeper集群在运行过程中Leader出了问题,系统会采用该算法重新选出一个Leader。因此,各个结点之间要能够保证互相连接,必须配置上述映射。
ZooKeeper集群启动的时候,会首先选出一个Leader,在Leader election过程中,某一个满足选举算的结点就能成为Leader。
而对于memcached不提供分布式方案,我们可以利用代理服务器来实现分布式部署.而Magent就是一个memcached代理服务器,但是它不存在什么leader,secondary,所有的命令入口都是magent这个代理服务器,当某个节点出现done机时,而请求数据找不到,它会从备份节点上获取.当让我们可用通过zookeeper来管理memcached分布式集群.
而对于redis 当设置好slave服务器后,slave会建立和master的连接,然后发送sync命令。无论是第一次同步建立的连接还是连接断开后的重新连 接,master都会启动一个后台进程,将数据库快照保存到文件中,同时master主进程会开始收集新的写命令并缓存起来。后台进程完成写文件 后,master就发送文件给slave,slave将文件保存到磁盘上,然后加载到内存恢复数据库快照到slave上。接着master就会把缓存的命 令转发给slave。而且后续master收到的写命令都会通过开始建立的连接发送给slave。从master到slave的同步数据的命令和从 client发送的命令使用相同的协议格式。当master和slave的连接断开时slave可以自动重新建立连接。如果master同时收到多个 slave发来的同步连接命令,只会使用启动一个进程来写数据库镜像,然后发送给所有slave。对于master出现故障时,我们可以通过持久化数据来恢复,而对于salve出现故障那么它会和master重新连接然后将所有的内从快照写入slave.可见这样恢复一定是很慢的.

相关文章推荐
- 分布式缓存Memcached
- Java通过SpyMemcached来缓存数据
- Linux下使用Magent+Memcached缓存服务器集群部署
- memcached的配置和spymemcached的使用笔记
- .Net专版-memcached在windows下的下载与安装
- Memcached安装使用和源码调试
- #Memcached系列#(6)使用Enyim.Caching访问Memcached的一个C#控制台程序
- memcache安装
- Tomcat6.x+memcached集群session管理(memcached-session-manager)
- #Memcached系列#(5)使用.NET memcached client library访问Memcached的一个C#控制台程序
- memcached—如何在Windows操作系统中安装、启动和卸载memcached
- spy memcache 客户端使用体会
- win8/win10下(64bit) memcache安装时报 "failed to install service or service already installed"
- memcached-1.4.22介绍以及安装
- #Memcached系列#(4)Windows 8.1企业版 64位操作系统安装Northscale版本的Memcached
- Memcached安装使用和源码调试
- linux-tomcat-memcached-session共享
- memcached搭建缓存系统
- #Memcached系列#(3)Windows 8.1企业版 64位操作系统安装Jellycan版本的Memcached
- #Memcached系列#(2)在Windows环境下安装Memcached