《Sql Server 分页查询》
2016-01-29 08:19
288 查看
记得在做牛腩新闻发布系统的时候就做过分页查询,分页查询在查询语句中起到了很大的作用,它能提高查询效率,写好了也能简化代码。现在我简单介绍一下Sql Server中的分页查询。
具体的业务逻辑是这样的,我数据库中有100条数据,我要查第40-50数据,表中有两个字段,一个字段是id,一个字段是name,其中id是不连续的,因为我删除id为44、45的记录,因为我要查数据的第40-50条记录,也就是id分别为41、42、43、46、47、...52的十条记录。那该怎么办呐?下面就是一些具体的例子。
方法一
先搜出id在1-40之间的数据,紧接着搜出id不在1-40之间的数据,最后将搜出的结果取前十条。
效果图如下
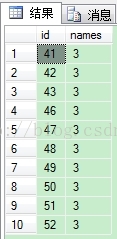
方法二
先查询前40条记录,然后获得其最id值,如果id值为null的,那么就返回0,然后查询id值大于前40条记录的最大id值的记录。这个查询有一个条件,就是id必须是int类型的。
效果图同上
方法三 使用Row_Number
把表中的所有数据都按照一个rowNumber进行排序,然后查询rownuber大于40的前十条记录。
方法四 OFFSET x ROW FETCH NEXT y ROWS ONLY;
使用OFFSET是SQLServer2012新具有的分页功能,主要功能是从第x条数据开始共取y数据。但是其必须根再Order By 后面使用,相比前三种方式更加方便。例如
select id from a Order by id Offset 0 Row Fetch Next 5 Rows Only. 这种方法支持SQLServer2012,但是SQLServer2008不支持,这种方法就像lamda表达式的Skip().Take()原理差不多。
小结
自我感觉第三种方式非常的爽,而且是爽到家了,因为没有嵌套查询啊,少了Sql语句的嵌套,就少了“视觉上的逻辑”,由上面的例子可以看出,Sql Server的确挺强大的,但是如果我们缺少发现“功能” 的眼睛的话,Sql Server再强大对我们来说也没有。
具体的业务逻辑是这样的,我数据库中有100条数据,我要查第40-50数据,表中有两个字段,一个字段是id,一个字段是name,其中id是不连续的,因为我删除id为44、45的记录,因为我要查数据的第40-50条记录,也就是id分别为41、42、43、46、47、...52的十条记录。那该怎么办呐?下面就是一些具体的例子。
方法一
先搜出id在1-40之间的数据,紧接着搜出id不在1-40之间的数据,最后将搜出的结果取前十条。
SELECT TOP 10 --3、最后再取出前10条数据,这就是数据库中第41-50条数据(注意,id不是41-50,因为我删除了id为44、45的记录) * FROM dbo.a WHERE id NOT IN ( --2、然后搜出id不在前40之内的其它数据 SELECT TOP 40 --1、按照id排序之后先搜出前40条数据 id FROM dbo.a ORDER BY id ) ORDER BY id;
效果图如下
方法二
先查询前40条记录,然后获得其最id值,如果id值为null的,那么就返回0,然后查询id值大于前40条记录的最大id值的记录。这个查询有一个条件,就是id必须是int类型的。
SELECT TOP 10 --3、最后再取出前10条数据, * FROM dbo.a WHERE id > ( SELECT ISNULL(MAX(id), 0) --2、如果Id为空则赋值为0 FROM ( SELECT TOP 40 --1、按照id排序之后先搜出前40条数据 id FROM dbo.a ORDER BY id ) B ) ORDER BY id;
效果图同上
方法三 使用Row_Number
把表中的所有数据都按照一个rowNumber进行排序,然后查询rownuber大于40的前十条记录。
SELECT TOP 10 * FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY id ) AS rownumber , * FROM a ) A WHERE rownumber > 40;
方法四 OFFSET x ROW FETCH NEXT y ROWS ONLY;
使用OFFSET是SQLServer2012新具有的分页功能,主要功能是从第x条数据开始共取y数据。但是其必须根再Order By 后面使用,相比前三种方式更加方便。例如
select id from a Order by id Offset 0 Row Fetch Next 5 Rows Only. 这种方法支持SQLServer2012,但是SQLServer2008不支持,这种方法就像lamda表达式的Skip().Take()原理差不多。
小结
自我感觉第三种方式非常的爽,而且是爽到家了,因为没有嵌套查询啊,少了Sql语句的嵌套,就少了“视觉上的逻辑”,由上面的例子可以看出,Sql Server的确挺强大的,但是如果我们缺少发现“功能” 的眼睛的话,Sql Server再强大对我们来说也没有。

相关文章推荐
- more、less 和 most 的区别
- 十万条Access数据表分页的两个解决方法
- 推荐Sql server一些常见性能问题的解决方法
- SQL Server存储过程的基础说明
- sqlserver关于分页存储过程的优化【让数据库按我们的意思执行查询计划】
- 高效的mysql分页方法及原理
- asp又一个分页的代码例子
- SqlServer 2000、2005分页存储过程整理第1/3页
- ADO存取数据库时如何分页显示
- SQL Server下几个危险的扩展存储过程
- 如何在SQL Server 2008下轻松调试T-SQL语句和存储过程
- SQL Server中选出指定范围行的SQL语句代码
- 透彻掌握ASP分页技术很详细的分析
- 一条SQL语句搞定Sql2000 分页
- 分页 SQLServer存储过程
- 一些SQL Server存储过程参数及例子
- 实现SQL分页的存储过程代码
- SQL Server优化50法汇总
- sql分页查询几种写法
- SQL行号排序和分页(SQL查询中插入行号 自定义分页的另类实现)